

We reviewed the architecture of our global search at DoorDash in early 2022 and concluded that our rapid growth meant within three years we wouldn't be able to scale the system efficiently, particularly as global search shifted from store-only to a hybrid item-and-store search experience.
Our analysis identified Elasticsearch as our architecture's primary bottleneck. Two primary aspects of that search engine were causing the trouble: its document-replication mechanism and its lack of support for complex document relationships. In addition, Elasticsearch does not provide internal capabilities for query understanding and ranking.
We decided the best way to address these challenges was to move away from Elasticsearch to a homegrown search engine. We chose Apache Lucene as the core of the new search engine. The Search Engine uses a segment-replication model and separates indexing and searching traffic. We designed the index to store multiple types of documents with relations between them. Following the migration to DoorDash's Search Engine, we saw a 50% p99.9 latency reduction and a 75% hardware cost decrease.
Path to Our Search Engine
We wanted to design the new system as a horizontally scalable general-purpose search engine capable of scaling to all traffic - indexing or searching - by adding more replicas. We also designed the service to be a one-stop solution for all DoorDash teams that need a search engine.
Apache Lucene, the new system's foundation, provides a mature information retrieval library used in several other systems, including Elasticsearch and Apache Solr. Because the library provides all the necessary primitives to create a search engine, we only needed to design and build opinionated services to run on top of the library.
The Search Engine Components
To address scalability challenges, we adopted a segment-replication model. We split indexing and searching responsibilities into two distinct services - indexer and searcher, as shown in Figure 1 below. The indexer is a non-replicated service that handles all incoming indexing traffic and uploads newly created index segments to S3 for searcher consumption. The searcher is a replicated service that serves queries against the index downloaded from S3.
Because the searcher is not responsible for indexing traffic, it only needs to scale proportionally to the search traffic. In other words, the searcher will not be affected by any volume of indexing traffic. The indexer is not a replicated service; horizontally scaling the indexer means increasing the number of index shards, which could be expensive. To alleviate that issue, we split the indexing traffic into bulk and high-priority updates. The high-priority updates are applied immediately, while the bulk updates are only applied during the next full index build cycle, usually every six hours.
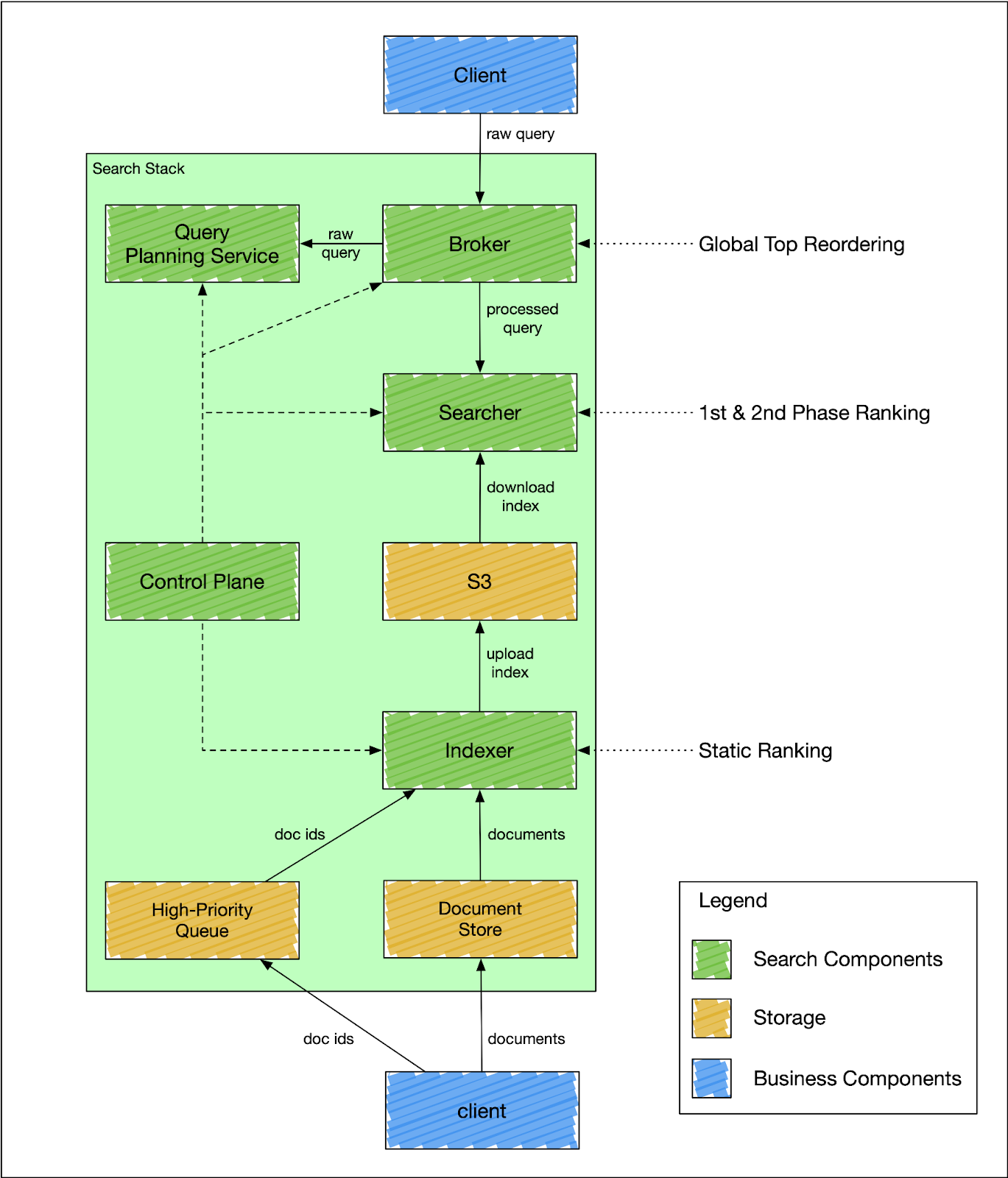
It's insufficient to query an index with only indexers and searchers because the index could consist of multiple index shards. Therefore, we designed the broker service as an aggregation layer that fans out the query to each relevant index shard and merges the results. The broker service also rewrites the user's raw query using a query understanding and planning service. 
We also needed a component that could do query understanding and query planning. The component needs to know the specifics of a particular index and the business domain where the index is used. It would be suboptimal to outsource this responsibility to the client because each client would need to replicate this logic and keep updated. But if the logic were consolidated into the query planning service, the clients would only need to know the high-level interface without getting into all the details about query internals.
General Purpose Search Engine
As a general-purpose search engine, the Search Engine must power not only DoorDash's store and item search but also must be available for every team that needs an information retrieval solution. That meant designing the system to provide a clear separation between core search and business logic. A user must be able to express business logic with little to no code changes and that logic must be completely isolated from the logic of other users.
The best approach to separating core search and business logic would be to introduce a declarative configuration for index schema and provide a generic query language. The index schema allows users to define strongly typed documents, or namespaces, and create relationships between the namespaces. A namespace definition consists of three primary parts:
- Indexed fields are fields the indexer processes and writes (or not) in some shape or form into the inverted index. The Search Engine supports all Apache Lucene fields, including text, numeric doc values, dimensional points, and KNN vectors.
- Computed fields are fields computed dynamically during query time based on inputs such as the query, the indexed fields, and other computed fields. The computed fields framework provides a means to express complex ranking functions and custom business logic; as an example, we can define a BM25 or an ML model as a computed field.
- Query planning pipelines define the logic of how to process raw client queries into the final form used to retrieve and rank documents. The primary objective is to encapsulate the business logic and store it in one place. For example, a client calling DoorDash's global search does not need all the complexity of the geo constraints if the logic is implemented in a query planning pipeline. The client would only need to supply the search with coordinates or a geo-hash of the delivery address and the name of the query planning pipeline to invoke.
In addition to the flexible index schema model, we created an SQL-like API as a powerful and flexible search query to allow customers to express their business logic with minimal code changes. The API provides a set of standards for search engine operators, such as keyword groups, filter constraints, sorting by fields, and a list of returned fields. Additionally, the Search Engine supports join and dedupe operators.
To support the join operator, we designed relationships between namespaces. A relationship can be either local-join or block-join. The local-join relationship is set between parent and child namespaces to guarantee that a child document will be added to the index shard only if a parent document references it. The nested relationship works similarly to the local-join relationship, but the parent and the children must be indexed together as a single block. Both options have advantages and weaknesses. The local-join relationship allows updating documents independently but requires executing queries sequentially. The nested relationship allows faster query execution but requires reindexing the whole document block.
Tenant Isolation and Search Stacks
Data and traffic isolation are important for users of a general-purpose search engine. To provide this isolation, we designed a search stack - a collection of search services dedicated to one particular index. A component of one search stack only knows how to build or query it's index. Thus, sudden issues in one search stack will not cause any issues for other search stacks. Additionally, we can easily account for all resources provisioned by tenants to keep them accountable.
Search stacks are great for isolating tenants' index schemas and services. Additionally, we wanted to find an easy way to mutate index schema and stack configuration without worrying about backward compatibility of changes. Users must be able to make changes in the index schema or fleet configuration and deploy them as soon as the changes do not have internal contradictions.
We designed a special component called a control plane - an orchestration service that is responsible for stack mutation, as shown in Figure 2 below. The control plane deploys stacks by gradually deploying a new generation and descaling the previous one. A generation has a fixed version of the search Docker image to deploy. All search components in the same generation have the same code version, index schema, and fleet configuration. The components inside a generation are isolated and can only communicate with other components within the same generation. A searcher can only consume an index produced by the indexer of the same generation, and a broker can only query searchers of the same generation.
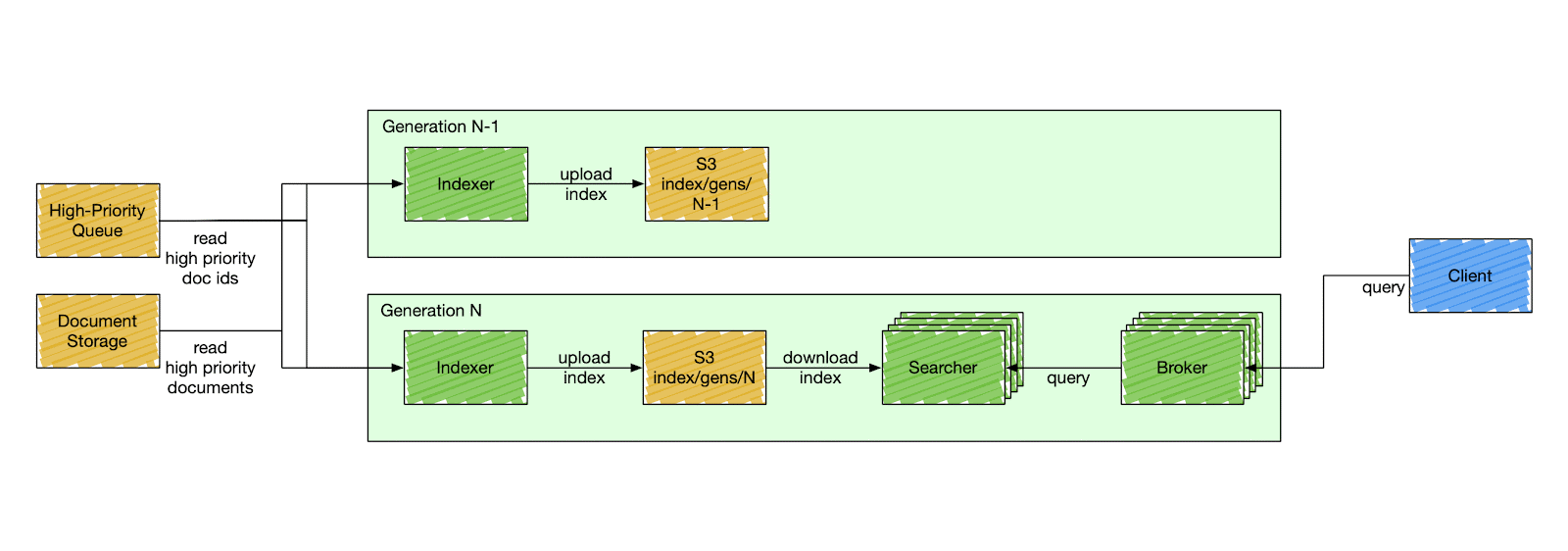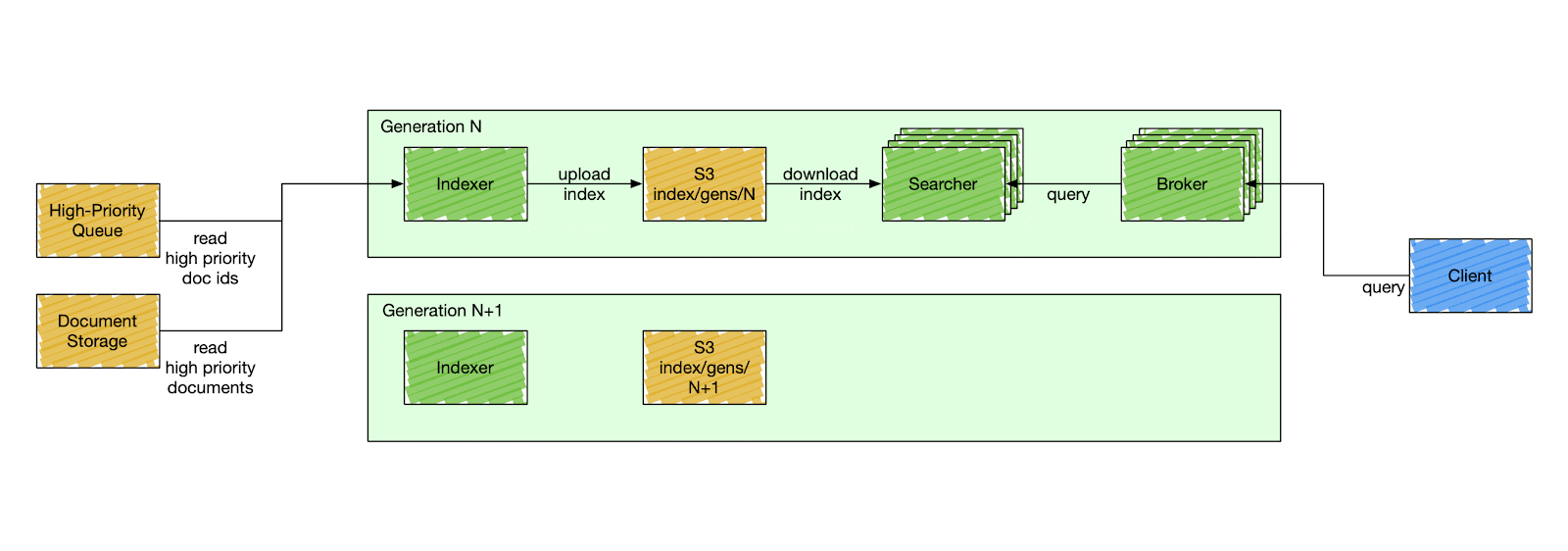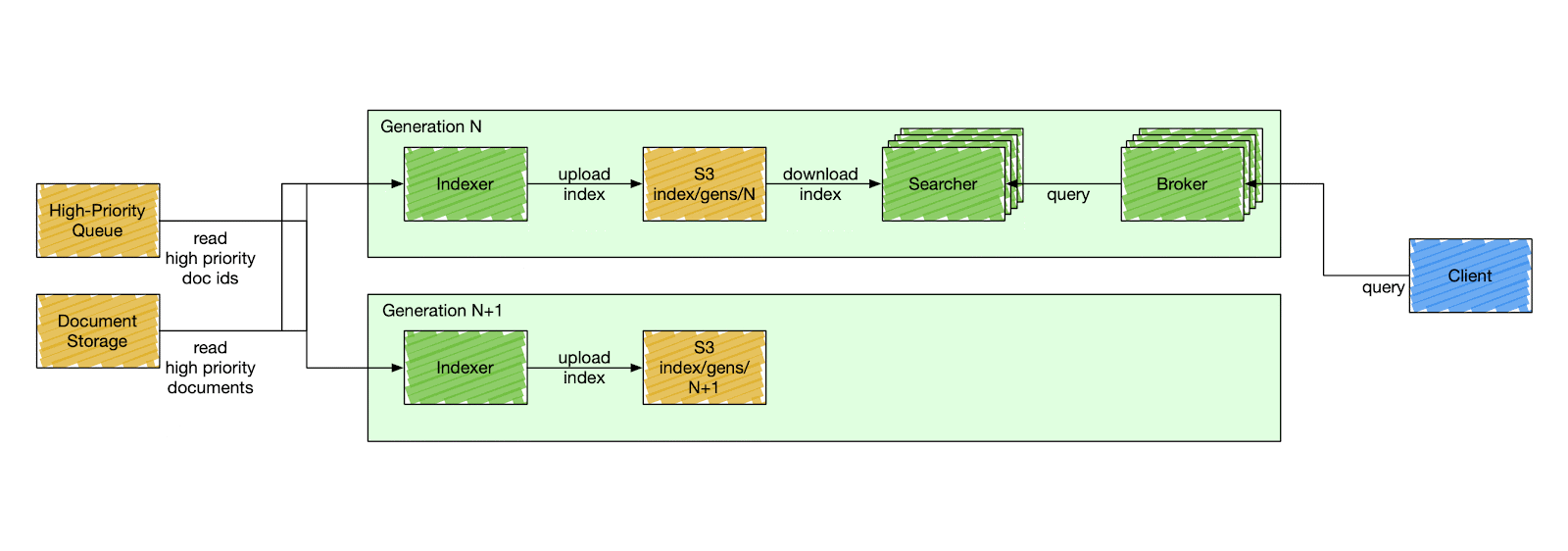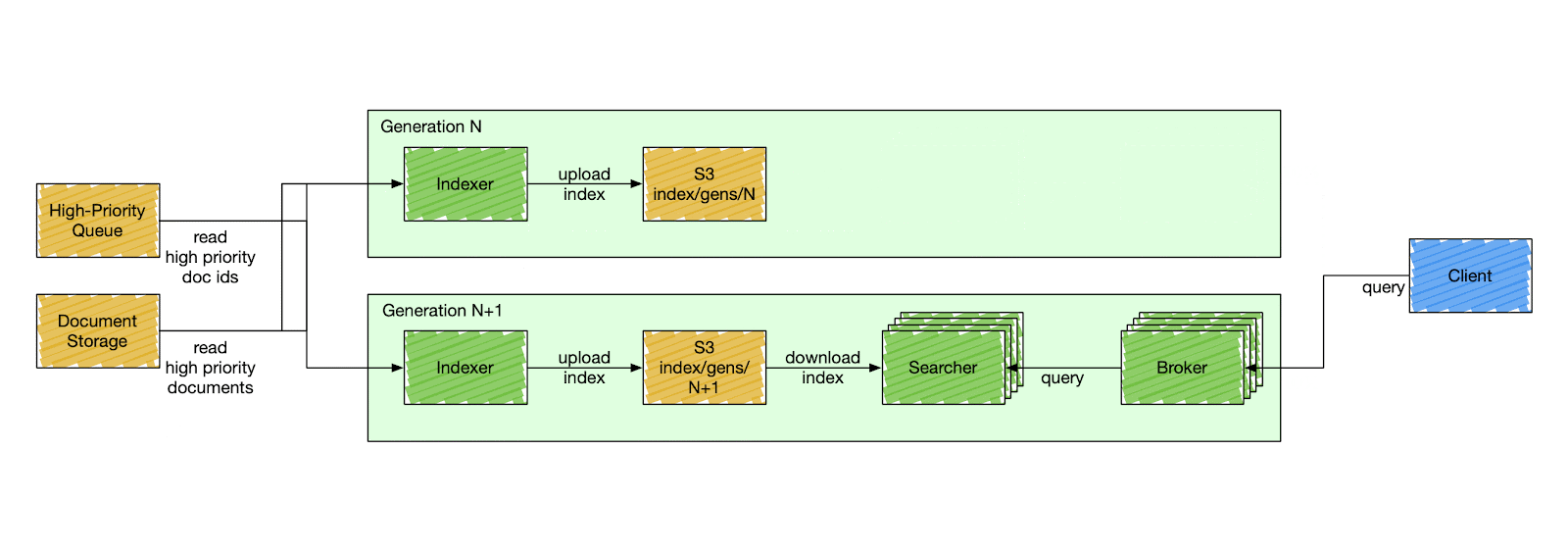
This simplifies user-side changes in exchange for a more complex deployment pipeline. The control plane deploys a new generation of a stack every six hours, although that can be changed to any arbitrary timing. It starts by cutting a new release of the search repository. When the release is ready, the control plane deploys a new stack, starting from the indexer. The indexer builds a new index from scratch - full index build - and catches up with high-priority updates. After the indexer signals the new index is ready, the control plane starts gradually scaling the serving side of the current generation and descaling the previous one.
Conclusion
We spent 2023 implementing the Search Engine and migrating DoorDash to it. In the first half of the year, we delivered the initial version of the system and migrated the global store search. That led to a two-fold reduction of the store retrieval latency and a four-fold reduction of the fleet cost.
During the second half of the year, we added support for the join queries, query planning, and support for ML-ranking functions. We migrated the query understanding from the client to the query planning layer. Now, any client can call the search without replicating complex query-building logic. The join query and ML ranking are used to do global item searches without first calling the store index. These features contributed to significant improvements in the precision and recall of the item index.
Migrating to an in-house search engine has given us tight control over the index structure and the query flow. The Search Engine lets us create a flexible, generic solution with features optimized for specific DoorDash needs and the scalability to grow at the same pace as DoorDash's business.


