

Photo: Courtesy of The AI Conference
Imagine a bustling marketplace where consumers seamlessly connect with local merchants to get everything from groceries to gifts delivered to their doorsteps. That’s our mission at DoorDash. With our recent expansion into New Verticals — like groceries, alcohol, retail, and more — we’re transforming what’s possible in on-demand delivery. And at the core of this transformation is the fusion of Machine Learning (ML) and Generative AI, taking customer experience to the next level.
At the 2024 AI Conference in San Francisco, our Head of New Verticals ML/AI, Sudeep Das, took the stage to unveil some of the groundbreaking work that the Machine Learning team at DoorDash has been up to.
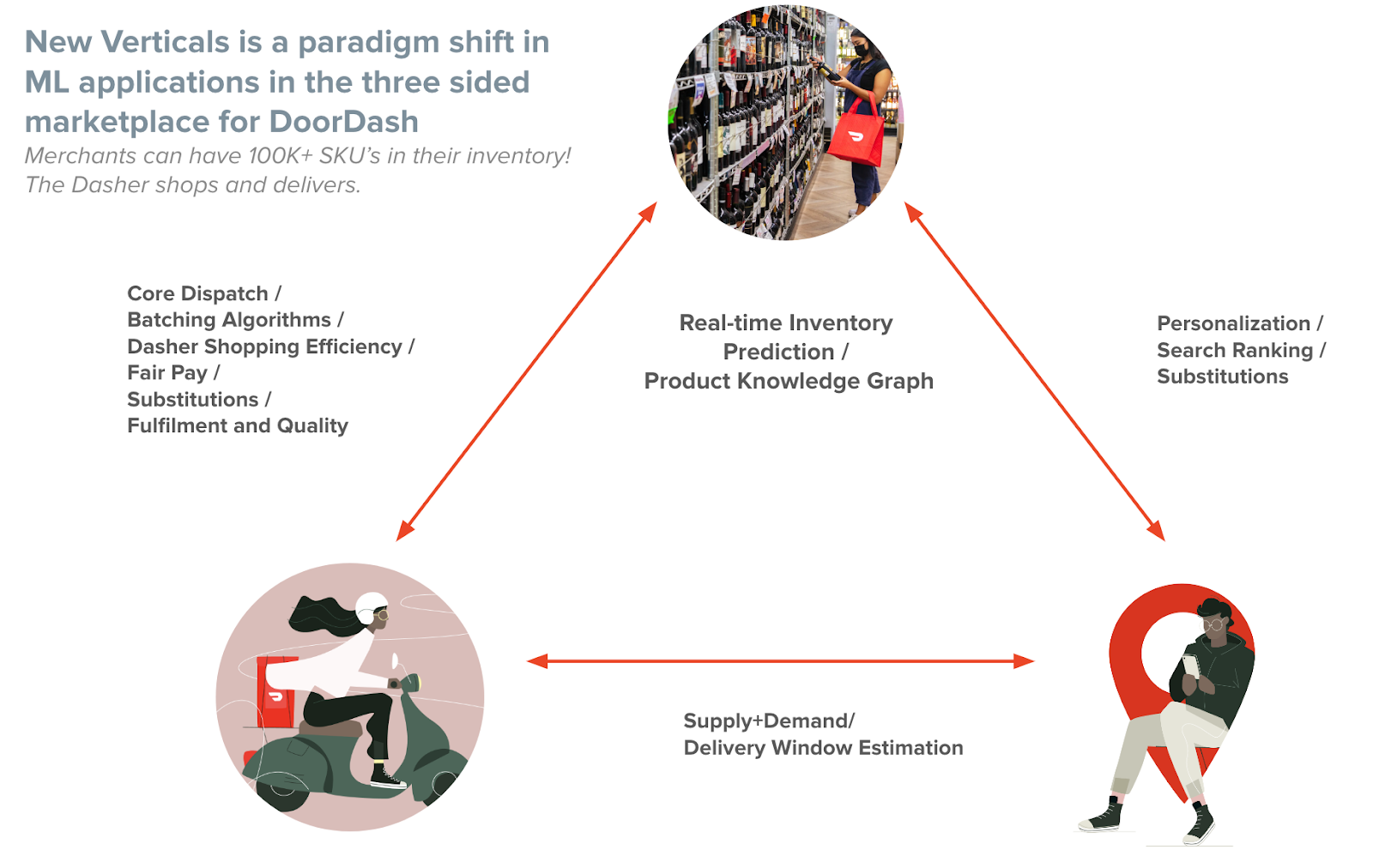
DoorDash’s growth beyond food delivery is not just an expansion; it’s a paradigm shift in how we approach ML/AI. Handling hundreds of thousands of SKUs across diverse categories, understanding complex user needs, and optimizing a dynamic marketplace are just some of the challenges this expansion brings.
Expanding to New Verticals: A paradigm shift in DoorDash’s ML/AI applications
With new verticals come new complexities. Our dashers are no longer simply picking up prepared meals — they’re navigating grocery store aisles, selecting items from multiple categories, and managing an intricate mix of orders. At the same time, consumers are building grocery carts on small mobile screens, searching for specific items across a vast inventory, and expecting an experience that’s fast, relevant, and convenient. These challenges demand innovative ML solutions that can personalize search, optimize logistics, and ensure efficiency at every step. This is where our commitment to pushing the boundaries of ML/AI truly shines, enabling us to deliver a seamless shopping experience across our expanding marketplace. Managing this means developing ML models for everything, from better product suggestions to optimizing dasher shopping routes.
So, how do we do it? Here are some of the key areas where ML is making waves:
- Product Knowledge Graph: Enriching our product information such that both the consumer and the dasher can shop more confidently.
- Personalization & Search: Tailoring the shopping experience for every customer.
- Substitutions & Fulfillment Quality: Ensuring every order is accurate and fulfilled with high quality.
- Dasher Shopping Efficiency: Streamlining the process for dashers so they can fulfill orders faster while ensuring fair pay.
- Inventory Prediction: Keeping track of what’s in stock so consumers always get what they want.
- And many more …
The real kicker? We’re combining traditional ML with the power of Large Language Models (LLMs) to supercharge these areas. In this talk, Sudeep focused on two areas that are getting supercharged by the blending of Traditional ML with LLMs, Product Knowledge Graph and Search.
Let's dive in!
Supercharging product knowledge graphs with LLM-assisted annotations and attribute extraction
Building a robust Product Knowledge Graph is essential for delivering an accurate and seamless shopping experience at DoorDash, particularly as we expand into new verticals like groceries and alcohol. To make this possible, we rely on LLM-assisted processes to overcome traditional challenges in product attribute extraction such as high operational costs and long turnaround times.
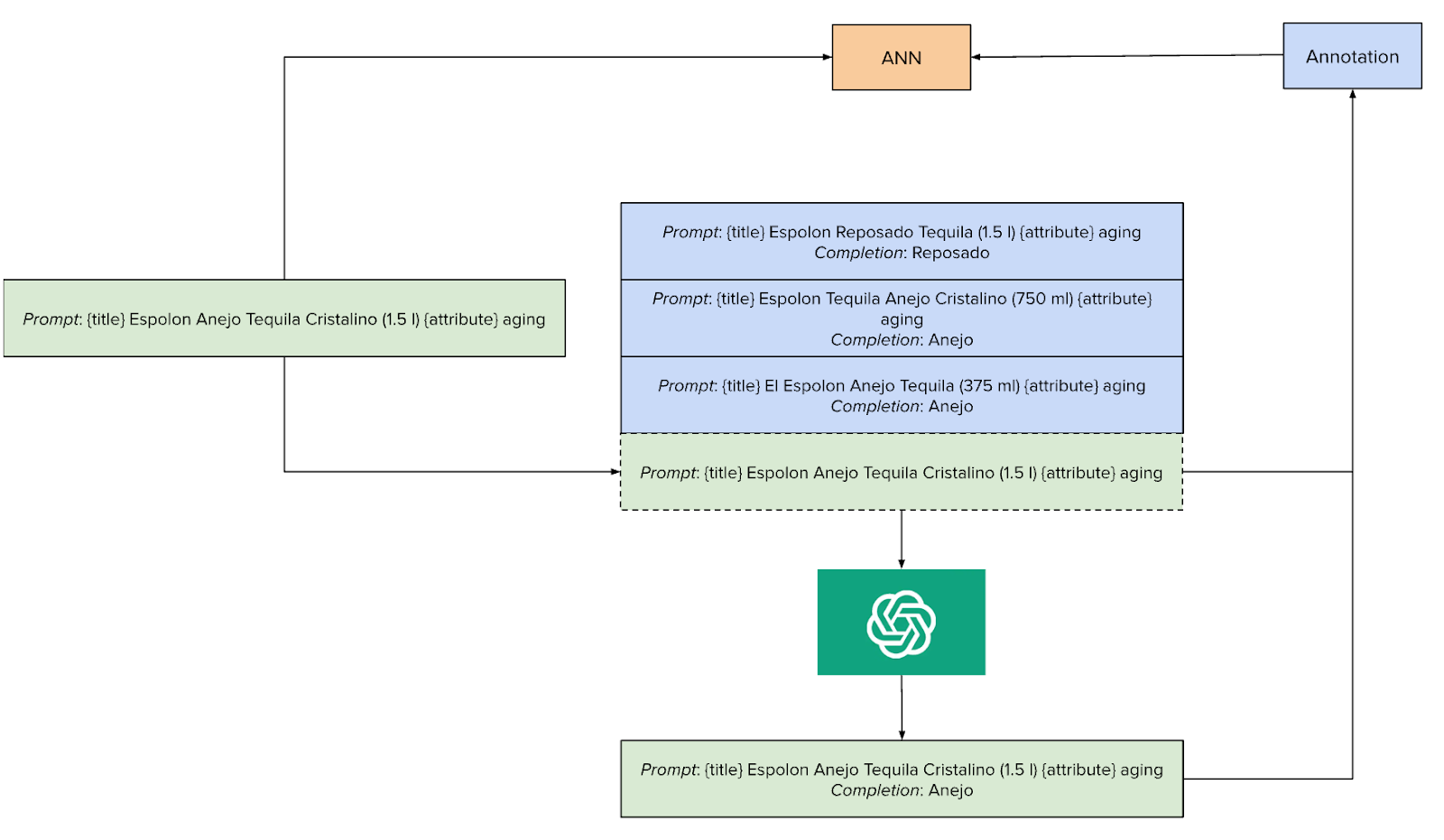
Training an effective Natural Language Processing (NLP) model requires a large amount of high-quality labeled data. Traditionally, this has meant outsourcing annotation tasks to human annotators—a process that is both time-consuming and expensive. But with the power of Large Language Models (LLMs), we can dramatically accelerate this process. At DoorDash, LLM-assisted annotations help us tackle the "cold start" problem, significantly reducing costs and enabling us to train models in days instead of weeks.
We begin by creating a few high-quality, manually labeled annotations—known as "golden" annotations—for new categories or products. Then, using Retrieval-Augmented Generation (RAG), we generate many additional "silver" annotations. This expanded dataset allows us to fine-tune LLMs, resulting in a Generalized Attribute Extraction model capable of identifying and extracting critical product attributes across diverse categories.
For example, when categorizing alcohol products, we need to extract attributes that are unique to each type of beverage:
- Wine: Region (e.g., Sonoma County), Vintage (e.g., 2012), Grape Variety (e.g., Pinot Noir)
- Spirits: Flavor (e.g., Pineapple), Aging (e.g., Silver), ABV (e.g., 80 Proof), Container (e.g., Plastic Bottle)
- Beer: Flavor (e.g., Sour), Container (e.g., Can), Dietary Tag (e.g., Light)
This model allows us to enrich our Product Knowledge Graph with accurate and detailed product information, making it easier for customers to find exactly what they are looking for, whether it's a specific vintage wine or a flavor of craft beer.
By starting with a small set of golden annotations and leveraging LLMs to generate a much larger set of silver annotations, we can quickly scale up our labeling efforts. This approach not only improves the relevance and accuracy of our product database but also enhances the shopping experience by powering smarter, more intuitive recommendations
.
Detecting and prioritizing catalog inaccuracies with LLMs
Ensuring the accuracy of our product catalog is crucial to maintaining customer trust and delivering a seamless shopping experience. At DoorDash, we use Large Language Models (LLMs) to automate the detection of catalog inconsistencies. Our process begins by constructing a natural language prompt based on primary attributes like the item name, photo, and unit information. The LLM evaluates the product details, identifying any discrepancies between the listed attributes and the visual representation on the packaging.

If an inconsistency is detected, the system classifies the issue into priority buckets — P0, P1, or P2 — based on the severity and urgency of the fix. For example, a major inconsistency (P0), such as a mismatch in product flavor between the title and the package image, is flagged for immediate correction. Medium inconsistencies (P1) are addressed in a timely manner, while minor issues (P2) are added to the backlog for future updates. This LLM-driven approach not only enhances the accuracy of our catalog but also helps streamline the process of issue prioritization, ensuring that our customers always have access to reliable product information.
The results? Enhanced product discovery, quicker adaptations to new verticals, and a smoother, trustworthy, and more intuitive shopping experience for our consumers and dashers.
Lets now turn to another area that is getting transformed by LLMs — Search!
Transforming Search at DoorDash: Multi-intent, geo-aware, and personalized
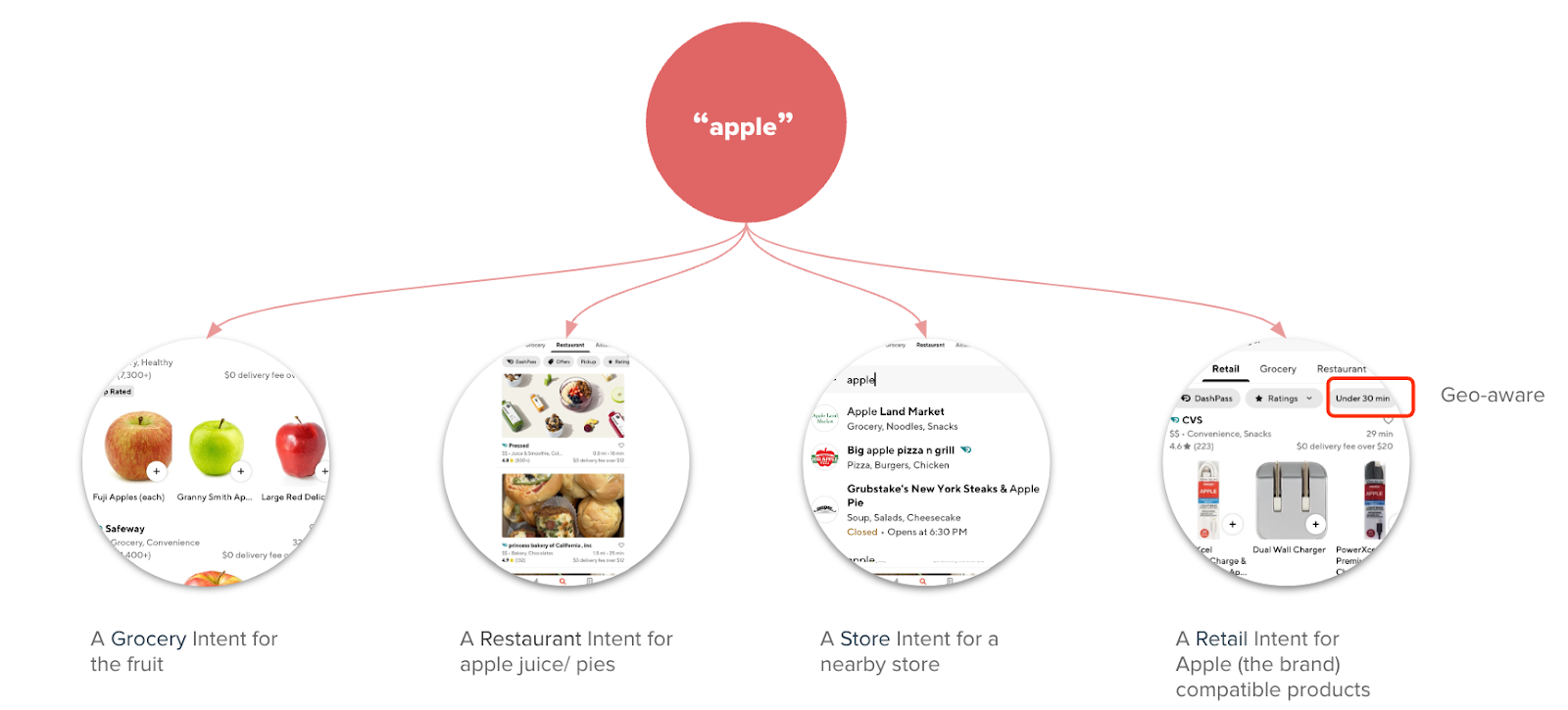
Search at DoorDash is more than just a straightforward keyword matching system; it’s a dynamic, multi-intent, multi-entity-type, and geo-aware engine. When a user searches for something like “apple,” our search system understands that the intent can vary widely depending on context. Is the user looking for fresh apples from a grocery store, apple juice from a restaurant, or even Apple-branded products from a retail store? This multi-faceted approach allows us to deliver tailored results based on the specific needs of the user, which is critical for a diverse marketplace like ours.
On top of being multi-intent and multi-entity, our search engine is geo-aware. This means it prioritizes results based on location, ensuring that users see products and stores that are relevant to their immediate area. Whether they’re searching for fresh produce, a local restaurant, or a nearby retail store, we make sure that results are both relevant and accessible.
Understanding Query Intent with LLMs: Training for Precision
To deliver accurate and relevant search results, it’s essential to understand the underlying intent behind each query. For example, when someone searches for “ragu,” our system needs to determine if they’re looking for pasta sauce, a restaurant, or even a specific brand. We train relevance models based on engagement signals, but since engagement data can be noisy and sparse for niche or “tail” queries, we leverage Large Language Models (LLMs) to improve training data quality at scale. LLMs help us assign labels to these less common queries, enhancing the accuracy and reliability of our search systems.
Personalization in Search: Making Every Result Relevant
Personalization plays a crucial role in enhancing the search experience. After all, when it comes to products like milk or chips, preferences can vary drastically. Some users prefer organic options, while others are more price-sensitive. At DoorDash, we utilize personalization in search to rank results based on individual preferences such as dietary needs, brand affinities, price sensitivity, and shopping habits. This ensures that each user sees the most relevant products for their unique needs.
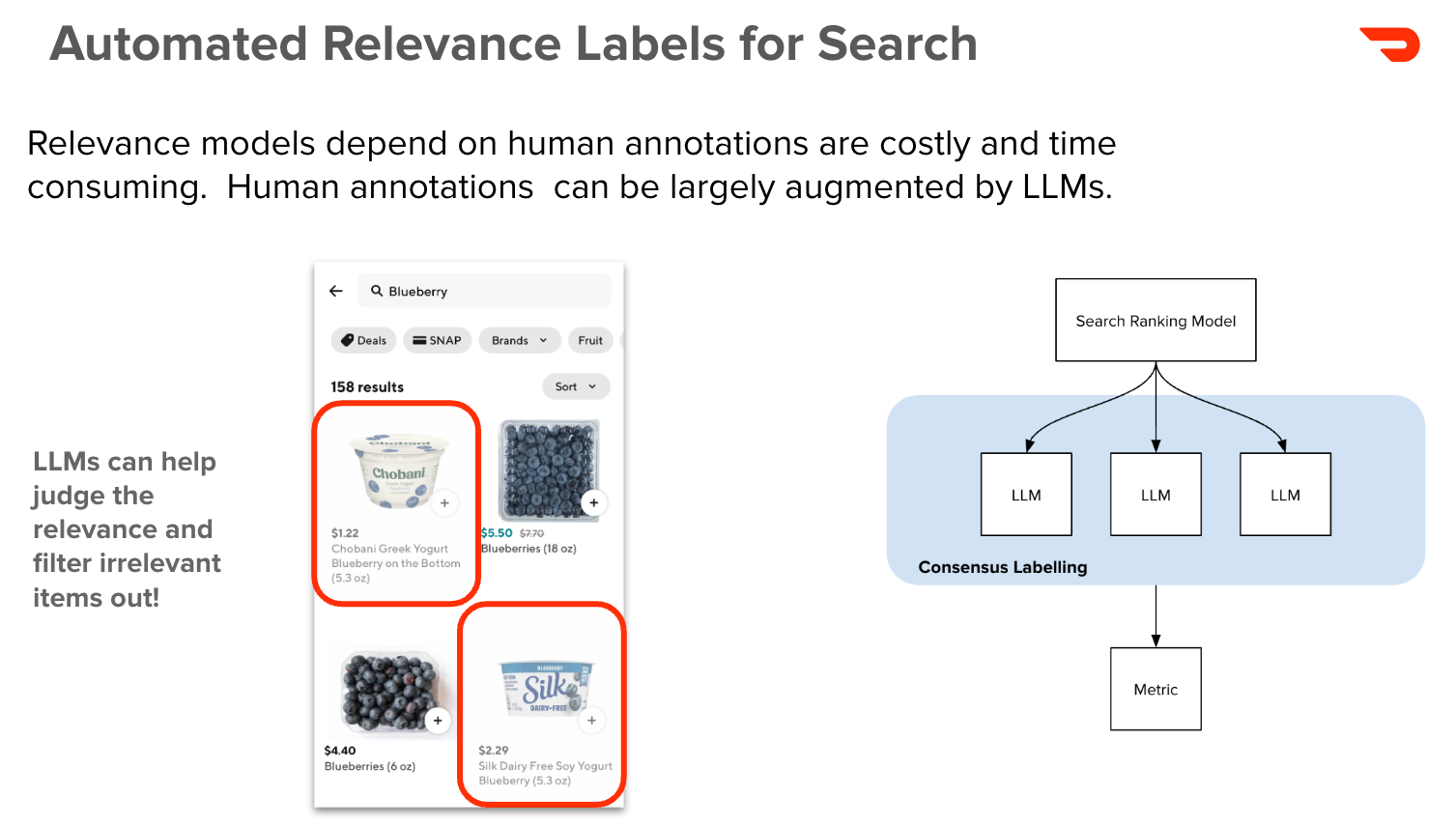
But, as with any advanced technology, there’s a fine line to walk. Over-personalization can lead to users seeing repetitive or irrelevant items. To counter this, we prioritize relevance guardrails to ensure that personalization complements, rather than overshadows, the actual search intent. For example, while a user with a preference for yogurt might see yogurt-related products in a search for “blueberry,” we ensure that the results remain relevant to blueberries rather than overly focusing on yogurt.
Automating Relevance Labels: LLMs to the Rescue
Labeling search results for relevance is a task that traditionally relies on human annotations, which can be both costly and time-consuming. At DoorDash, we use LLMs to automate this process by evaluating and filtering out irrelevant results. This not only helps reduce the workload for our human annotators but also speeds up the model development process, allowing us to maintain high-quality search experiences with greater efficiency. By implementing consensus labeling with LLMs, we ensure our search engine remains precise and capable of consistently delivering the most relevant results to our users.
Through these advancements in multi-intent understanding, personalization, and relevance filtering, DoorDash is redefining the search experience to be intuitive, personalized, and contextually aware, ultimately making every shopping experience as seamless and efficient as possible.
Overcoming challenges and exploring new horizons with LLMs
As we continue to push the boundaries of Machine Learning at DoorDash, integrating Large Language Models (LLMs) into our systems presents unique challenges. Prompt tuning and evaluation at scale is a significant hurdle, especially as we leverage distributed computing frameworks like Ray to accelerate LLM inference. Fine-tuning LLMs with internal data for domain-specific needs, while maintaining flexibility and scalability, requires sophisticated methods such as LoRA and QLoRA. Additionally, integrating Retrieval-Augmented Generation (RAG) techniques allows us to inject external knowledge into our models, enhancing their contextual understanding and relevance.
Another challenge is building high-throughput, low-latency pipelines. LLMs are powerful but often computationally intensive. To meet the demands of real-time applications, we employ model distillation and quantization to create smaller, more efficient student models suitable for online inference. This process allows us to scale LLM-powered features without compromising on performance, making our systems faster and more cost-effective.
Looking ahead, we are excited to explore Multimodal LLMs that can process and understand a variety of data types, from text to images, to create even richer customer experiences. We’re also working towards building DoorDash-specific LLMs to further enhance our Product Knowledge Graph and optimize natural language search. As we integrate LLMs deeper into our ecosystem, we envision a future where DoorDash provides increasingly personalized, intuitive, and efficient services across all our verticals, delivering a truly seamless shopping experience for our users.
Join us and help shape the future of shopping
At DoorDash, we’re on the cutting edge of technology, and LLMs are at the core of our innovation strategy. We’re building a future where every interaction is intuitive, personalized, and efficient. So, if you’re passionate about machine learning and want to make a tangible impact on millions of users worldwide, we’d love to have you on board.
Ready to make your mark? Let’s build the future of shopping together.
