

Business Policy Experiments Using Fractional Factorial Designs
At DoorDash, we constantly strive to improve our experimentation processes by addressing four key dimensions, including velocity to increase how many experiments we can conduct, toil to minimize our launch and analysis efforts, rigor to ensure a sound experimental design and robustly efficient analyses, and efficiency to reduce costs associated with our experimentation efforts.
Here we introduce a new framework that has demonstrated significant improvements in the first two of these dimensions: velocity and toil. Because DoorDash conducts thousands of experiments annually that contribute billions in gross merchandise value, it is critical to our business success that we quickly and accurately test the maximum number of hypotheses possible.
We have found that even as we enhance experimental throughput, we can also streamline the associated setup effort. In certain domains, such as campaign management in CRM, it can be time-consuming to designate and apply business policies to different user segments. The effort tends to be linearly correlated with the number of policies to be tested; additionally, the process can be prone to errors because of the need to conduct multiple manual steps across various platforms.
Our proposed framework, as outlined in this paper, increased experimental velocity by 267% while reducing our setup efforts by 67%. We found that the benefits generally are more pronounced when a model includes multiple factors, such as a feature or attribute of a policy, and levels, such as the value of a factor.
In addition to increasing velocity and reducing toil, our framework also provides a mechanism for testing the assumptions underlying an experiment's design, ensuring a consistently high level of rigor.
A/B testing for CRM campaign optimization
The consumer retention marketing team aims to build a lasting relationship with customers from the first moment they engage with DoorDash by presenting relevant marketing content to drive them to return. Like many businesses, we often use A/B tests to continually iterate on our best policy, choosing from the huge number of options in our policy space. Figure 1 below shows our typical experimentation lifecycle:
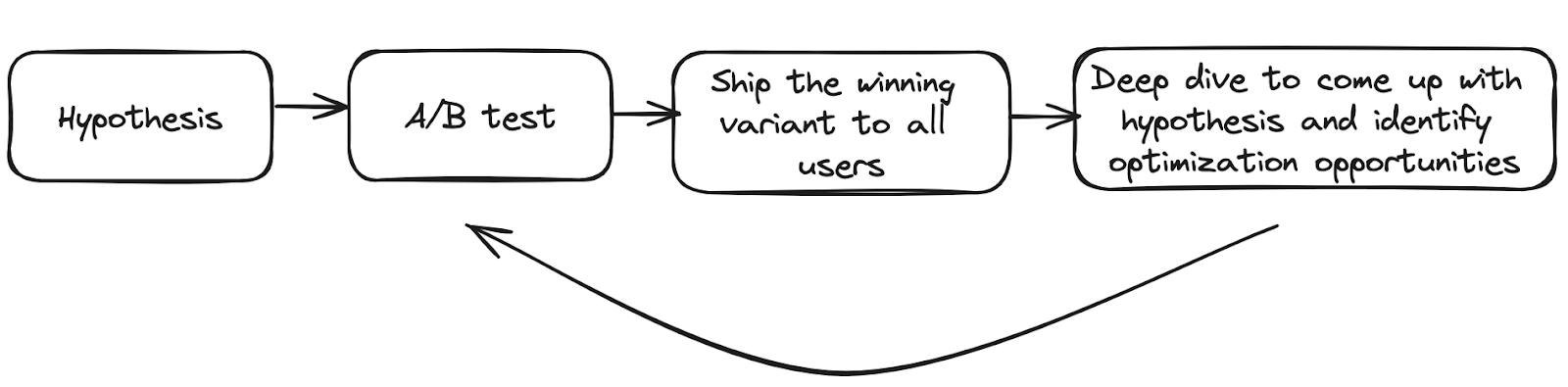
A number of challenges dampen our speed and increase the effort required to conduct experiments, including:
- High implementation costs: Unlike conventional web experiments, if we were to A/B test several policies at once, the setup implementation costs for randomized user segments could be extremely high.
- Budget constraints: Our limited marketing budget constraints our testing capabilities. Because each policy requires a minimum sample size to detect an effect, we can only assess a limited number of policies.
- Long-term metrics: Many metrics crucial to our evaluation, such as retention, require an extended measurement period, slowing our velocity.
- Sequential testing risks: Testing policies sequentially over time exposes experiments to potential risks, including shifts in business priorities. This may hamper implementation of optimal features while interfering with future iterations because of additional factors such as budget constraints and resource reallocation.
Because of these challenges and other issues, we can only test and compare a limited number of policies each quarter.
Another challenge worth mentioning is personalization, which we believe is key to making our marketing campaigns relevant and driving better long-term engagement. In a perfect world, we would test all possible policies and run a heterogeneous treatment effect, or HTE, model to identify the best policy for each consumer's historical data. However, because we have only training data with limited policies/campaigns and a small sample size, we are prevented from making the most of an HTE model.
Stay Informed with Weekly Updates
Subscribe to our Engineering blog to get regular updates on all the coolest projects our team is working on
Please enter a valid email address.
Thank you for Subscribing!
Applying fractional factorial design to the business policies space
In light of the challenges of prolonged experiment duration, high setup costs, and difficulty in identifying personalized policies, we created a framework that uses fractional factorial design to solve the problem. The following is a brief overview of the framework's intuition; readers seeking detailed insights are encouraged to explore our full paper on Arxiv.
Step 1) Factorization - break down the hypothesis into factors
Promotion policies traditionally have been treated at the experimentation phase as monolithic units and not as combinations of distinct components. Our framework's first innovation is to break down the campaign policy space into factors to create a foundation for the factorial design framework. In our project, we broke down the policy space into four distinct building blocks: promo spread, discount, triggering timing, and messaging, as shown in Figure 2.

Step 2) Apply fractional factorial experiment design to reduce in-sample variants
After creating these four building blocks - one with three levels and the others with two - we have 24 combinations. Recall the setup effort referenced above; there are major operational challenges in setting up such a 24-arm marketing campaign in one shot. To solve this problem, we make assumptions on higher-order interactions, for example no interaction effects. Don't worry; we will test these assumptions later. We then apply fractional factorial design to shrink the number of variants from 24 to eight, which reduces the setup cost by 66%. The different methodologies to conduct fractional factorial design are detailed in the full paper.

Step 3) Launch the experiment by including an additional out-of-sample variant
After we select eight in-sample variants to launch, we intentionally select a ninth variant which we will launch at the same time. We include an out-of-sample variant so that we can end-to-end test our assumptions about interaction effects. It is critical to validate with data any assumptions made based on our business intuition.

Step 4) Collect the data and validate the model assumption
After the experiment is launched and it reaches the predetermined sample size, we use the collected data to validate the model. On a high level, we use the data from the in-sample variants to predict the metric in the ninth validation variant. If the model is correct, the prediction should be close to the observed value. We discuss how to validate in greater detail in our paper.
Step 5) Estimate the treatment effect for each factor and policy
After the data is collected and the model assumption is validated through the out-of-sample variant, we estimate the treatment effect for each factor level and interaction if included in the model. We then can derive the treatment effect for all possible promo policy permutations.
Step 6) Use an ML model to estimate heterogeneous treatment effect
After the analysis of the average treatment effect, we consider personalized campaigns. The joint test we describe in our paper helps determine whether personalization is needed and what user characteristics are useful for personalization. If personalization buys us incremental value, we can apply a machine learning model to learn the heterogeneous treatment effect. In our paper, we discuss two general categories of models and a way to adjust the bias. In our example, the HTE model can generate 2% more profit than a single optimal campaign for all users.
Broader Applications
By breaking down policies into factors, we can leverage the factorial design to test more hypotheses simultaneously. By making assumptions about the interaction effects, we can reduce the number of in-sample variants that must be implemented.
In our specific business context, the framework improved on current methods by helping us discover the personalized policy with a 5% incremental profit while delivering 267% faster experimentation and 67% lower setup costs.
We believe the framework can be applied more generally to other domain areas where experiments are slowed by limited sample size and/or where setup or configuration costs increase with the number of variants or arms being tested. In our next steps, we plan to apply the framework to other domain areas at DoorDash and also further improve and productionize the personalized HTE model. For those seeking a deeper understanding, we encourage readers to delve into our preprint on Arxiv.
Acknowledgements
We would like to thank our retention marketing partners, Kristin Mendez, Meghan Bender, Will Stone, and Taryn Riemer, for helping us set up and launch the experiments throughout this research; we would also like to acknowledge the contributions of the data science and experimentation team colleagues, especially Qiyun Pan, Caixia Huang, and Zhe Mai. Finally, we want to thank our leadership Gunnard Johnson, Jason Zheng, Sudhir Tonse and Bhawana Goel for sponsoring this research and providing us with guidance along the way.
Resources
[1] Business Policy Experiments using Fractional Factorial Designs: Consumer Retention on DoorDash

