
Large e-commerce companies often face the challenge of displaying enticing product images while also ensuring fast loading speeds on high-traffic pages of their website. At DoorDash, we confronted this issue because our home page — the primary vehicle for our online marketplace’s success — was plagued with slow download speeds that were hurting the user experience and our SEO page rankings.
Our solution was to implement server-side rendering for high-traffic pages, which involved overcoming numerous challenges. In this article, we enumerate those challenges and how we approached them in order to build successful server-side rendering and prove it was effective.
Contents
- Why server-side rendering (SSR) improves a site
- Common pitfalls to avoid when moving to SSR
- Measuring performance to ensure meeting success metrics
- Customizing Next.js for DoorDash
- Implementing SSR without downtime
- Scaling and service reliability
- Dealing with gotchas
- Results
- Conclusion / Summary
Why server-side rendering (SSR) improves a site
The DoorDash app was running on a client-side system prone to loading issues, poor SEO, and other issues. By moving to server-side rendering, we hoped that we could upgrade a number of key elements, including:
- Enhancing the user experience: We wanted to improve the user experience by shortening page-load times. This aligns with the recent introduction of Google’s web metrics that favor fast, lightweight pages on modest mobile devices. These metrics have significant influence on the page rank assigned by Google.
- Enabling Bundle Size Optimization: Our existing client-side rendered single-page app (CSR, SPA) was becoming difficult to optimize because the size of the JavaScript and other resource bundles had become bloated.
- Improving SEO: We set out to deliver optimal SEO metadata using server-side rendered content. Whenever possible, it is better to deliver fully formed web content to search engines rather than waiting for client-side JavaScript to render the content. One approach: Move API calls from the client browser (north-south) to the server-side (east-west), where performance typically is better than on a user’s device.
Common pitfalls to avoid when moving to SSR
We wanted to be careful to avoid common issues with SSR as we worked to achieve these benefits. Rendering too much content on the server can be costly and require a large number of server pods to manage traffic. Our high-level goal was to use the server only to render above-the-fold content or content required for SEO purposes. This required ensuring the state between server and client components was an exact match. Discrepancies between client and server will result in unnecessary re-renders on the client side.
Measuring performance to ensure meeting success metrics
We used webpagetest.org both to measure the performance of the pre-SSR pages and also to confirm the performance gains on the new SSR pages. This excellent tool allows page measurements across a variety of devices and network conditions while providing extremely detailed information about the multitude of activities that occur when a large and/or complex page loads.
The most reliable way to get performance information is to test against real devices with realistic network speeds at geographical distance from your servers. Case in point: Website performance on a MacBook Pro is not a reliable predictor of real-world performance.
More recently, we added Google web vitals tracking (LCP, CLS, FID) to our observability dashboards to ensure that we are capturing and monitoring page performance across the entire spectrum of visitors and devices.
Customizing Next.js for DoorDash
Many engineers at DoorDash are huge fans of the Next.js team and Vercel. Vercel’s infrastructure was built for Next.js, providing both an amazing developer experience and a hosting infrastructure that make working with Next.js easy and maximally optimized.
In fact, we used Vercel to build out our initial SSR proof-of-concept that we then used for pitching stakeholders.
At DoorDash, however, we needed a little more flexibility and customization than Vercel could offer when it comes to how we deploy, build, and host our apps. We opted instead for the custom-server approach to serving pages via Next.js because it provided us more flexibility in how we hosted our app within our existing Kubernetes infrastructure.

Our custom server is built with Express.js and leverages our in-house JavaScript server toolkit, which provides out-of-the-box functionality like logging and metrics collection.
At our Ingress layer, we configured a reverse proxy that directs requests using our in-house experimentation framework. This configuration allows us to use a percentage-based rollout for consumers in treatment. If consumers are not bucketed in treatment, we route their request to our pre-existing single-page application. This proxy setup gives us flexibility over the conditions under which we direct the traffic.
This proxy also handles additional scaling concerns such as logging, circuit breaking, and timeouts, which are discussed below.
Stay Informed with Weekly Updates
Subscribe to our Engineering blog to get regular updates on all the coolest projects our team is working on
Please enter a valid email address.
Thank you for Subscribing!
Implementing SSR without downtime
Because DoorDash is growing rapidly and has many developers working at all times, we cannot afford any downtime, which would disrupt the customer experience and our developers working on other parts of the platform.
In other words, we needed to change the wheels of the car while we were barreling down the freeway at 65 miles per hour.
We carefully considered how our migration efforts to Next.js would affect customers, engineers, and the DoorDash business as whole. That meant resolving several key issues before we could proceed.
How to ensure new technology adoption without stopping or slowing down new feature development
It wasn’t feasible for us to halt new feature development — code freeze — while migrating our stack to Next.js because DoorDash is like a rocketship in terms of growth (see Figure 2).

If we forced engineers to develop their new features only on the new Next.js stack, we risked blocking their rollouts and product launches; customers wouldn’t get to try new experience-enhancing features and our business wouldn’t be able to iterate as fast on new ideas.
Consequently, if we required engineers to develop new features in both the old codebase and the new Next.js codebase, we would be burdening them with maintaining features in two separate runtime environments. Not only that, but our new Next.js application itself is in a rapid development state, which would require developers to relearn many significant changes throughout the development lifecycle.
Minimizing overhead and maintenance costs while both versions of a site are actively serving traffic
That left us to figure out how to maintain new features in both environments without requiring engineers to contribute solely to the new codebase. We wanted to ensure they were not slowed down or blocked by the migration to Next.js.
Having stacks live in a separate codebase was not ideal because we didn’t want to maintain a fork in a separate codebase, which would increase operational overhead and context-switching for engineers. Remember: DoorDash is growing fast, with new contributors from different teams and organizations hitting the ground running; any technical decision or constraint that affects how engineers operate has massive implications.
We therefore had both apps live together in the same codebase, maximizing code reuse wherever possible. To minimize overhead for developers, we enabled features build-out without concern for how they would eventually integrate with Next.js and SSR paradigms. Through code review and enforced linting rules, we ensured that new features were being written to be SSR-compatible. That process ensured that changes would integrate well with SSR regardless of changes made within the Next.js app.
When unifying the proof-of-concept Next.js codebase with our old application codebase, we needed to take care of some build configurations so that components written for one app were interoperable with the other app.
Some of this unification work involved building tooling changes, including updating our project’s Typescript configuration to support isolatedModules, updating our Webpack’s Babel configuration, and updating our Jest configurations so that code written for Next.js and our existing app were written similarly.
All that was left at this stage was to migrate our app from CSR to SSR.
Incrementally adopting SSR on an existing page without re-writing every feature
We wanted to learn quickly and see big performance wins for our customers without going through a multi-quarter effort to migrate a large app with dozens of pages. Migrating an entire multi-page app to Next.js would have been a massive effort that was out of scope for what we were trying to accomplish.
We therefore opted for a page-by-page incremental adoption approach in which we migrated one page to Next.js at a time.
We adopted a “trunk-branch-leaf” strategy, which involves focusing optimization efforts on components close to the top of the page or close to the top of the hierarchy of components on the page. For example, we completely rewrote the hero image component at the top of the homepage because it was above the fold and almost at the top of the component hierarchy of the page. Components lower down the page or lower in the hierarchy were left untouched. If these components contained references to objects not available on the server — such as window or document — then we either opted to lazy-load them on the client or simply performed a light refactor to remove the client-side dependency from them.
To permit the symmetrical usage of components in SSR, either server side or client side, and the CSR SPA app, we introduced a context provider called AppContext. This provider gives access to common objects such as query string parameters, cookies, and page URL in a way that works transparently in any context. On the server, for example, cookies are available by parsing them from the request object, while on the client these are available by parsing the document.cookie string. By wrapping both the new SSR app and the existing CSR SPA app in this provider, we could enable components to work in either.
Abstracting implementation details and conditional behavior using app context
There are some differences between our old app and our new app that are critical:
- Routing: React Router (SPA) vs Next.js-based routing
- Reading Cookies: Reading directly from document vs. no document available during SSR
- Tracking: Not firing tracking events during SSR vs. client-side
With the bridge pattern, we can decouple the implementation from the abstraction and change behavior at runtime based on the environment within which we’re running the app.
Here are some examples of how this can be done with some simplified pseudo code. We can create an app context which stores some metadata about our app and experience:
const AppContext = React.createContext<null | { isSSR: boolean }>(null)
const useAppContext = () => {
const ctx = React.useContext(AppContext)
if (ctx === null) throw Error('Context must be initialized before use')
return ctx
}
Then our core dependencies can read from this global app-state to behave conditionally or swap out dependencies depending on the need as follows:
const useTracking = () => {
const { isSSR } = useAppContext()
return {
track(eventName: string) {
// do a no-op while server-side rendering
if (isSSR && typeof window === 'undefined') return
// else do something that depends on `window` existing
window.analytics.track(eventName, {})
},
}
}import { Link as ReactRouterLink } from 'react-router-dom'
import NextLink from 'next/link'
// Abstracting away React-Router leads to more flexibility with routing
// during migration:
const WrappedLink: React.FC<{ to: string }> = ({ to, children }) => {
const { isSSR } = useAppContext()
if (!isSSR) {
return <ReactRouterLink to={to}>{children}</ReactRouterLink>
}
return <NextLink href={to}>{children}</NextLink>
}
Each application get instantiated with this global state:
const MyOldCSRApp = () => (
<AppContext.Provider value={{ isSSR: false }}>
<MySharedComponent />
</AppContext.Provider>
)
const MyNewSSRApp = () => (
<AppContext.Provider value={{ isSSR: true }}>
<MySharedComponent />
</AppContext.Provider>
)Meanwhile, shared components remain blissfully unaware of their environment or the dependencies working under the hood:
const MySharedComponent = () => {
const { track } = useTracking()
return (
<div>
<p>Hello world</p>
<WrappedLink to="/home">Click me to navigate</WrappedLink>
<button onClick={() => track('myEvent')}>Track event</button>
</div>
)
}
Scaling and service reliability
We needed to ensure that our new application would work reliably without hiccups. To do that, we needed to understand our current implementation better and prepare the system to withstand any potential issues we might encounter as we increased traffic to our service. We accomplished a reliable rollout using the following approaches:
Measuring and benchmarking
Before rolling out our new service to production, we needed to know how much traffic it could support and what resources it required. We used tools like Vegeta to audit the current capacity of a single pod. After an initial audit we saw that not all cores were being utilized to spread the processing load. As a result we used Node.js’s cluster API to make use of all the pod’s cores, which quadrupled the pod’s request capacity.
Falling back safely to mitigate service degradation
Because this service was new and not promoted to production yet, we realized that there were rollout risks that likely would need to be mitigated. We decided to ensure that, if the new service was failing requests or timing out, we could smoothly fall back to the old experience.
As mentioned earlier, we configured a proxy to handle routing traffic and bucketing users. To solve our concerns around a reliable rollout, we configured the proxy to send the request back to our old app experience if the new service’s request was failing.
Shedding load and circuit breaking
To prevent system overload or having customers experience a degraded app experience, we needed to have mechanisms like circuit breaking in place. These ensure that we can handle requests that start to fail because of runtime issues or because requests start to queue, degrading performance.
A limited timeout circuit breaker allows us to detect overloading on SSR servers and short-circuit -- load shed — to fall back to CSR.
Our proxy was configured with a circuit breaker — opossum — to load shed if requests were taking too long to complete or failing.
Figure 3 diagrams such a circuit breaker. According to the diagram’s famous author, Martin Fowler:
“The basic idea behind the circuit breaker is very simple. You wrap a protected function call in a circuit breaker object, which monitors for failures. Once the failures reach a certain threshold, the circuit breaker trips, and all further calls to the circuit breaker return with an error, without the protected call being made at all. Usually you'll also want some kind of monitor alert if the circuit breaker trips.”
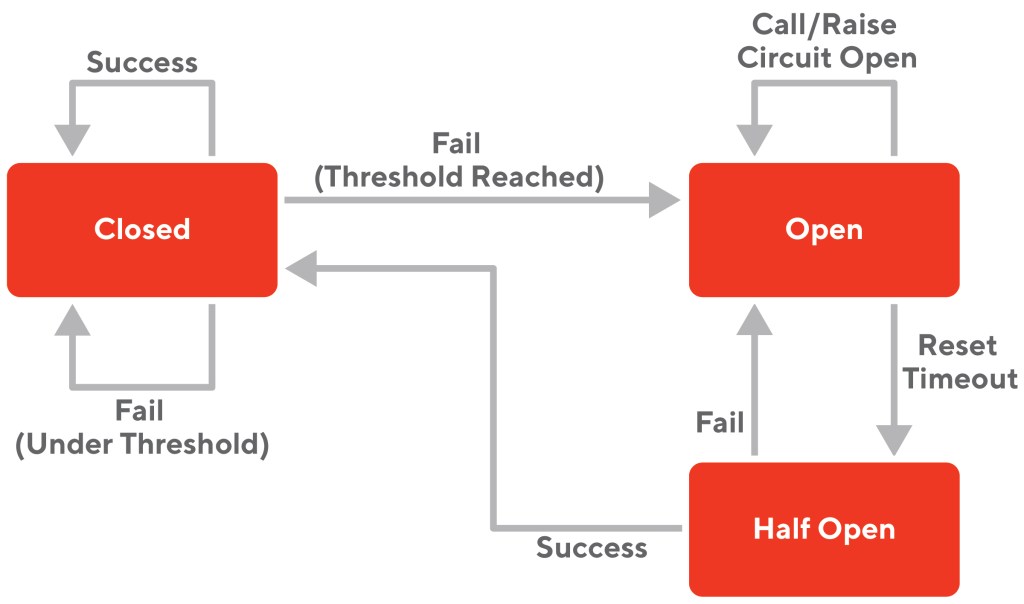
A diagram showing the various states of a circuit breaker.
Dashboards, monitoring RUM, and operational readiness
To ensure our service was behaving as expected, it was vital for us to build in full observability and monitoring of the system’s health.
We instrumented metrics and counters for things like request rates, failures, latencies, and circuit breaker status. We also configured alerting so that we would be notified immediately of any issues. Lastly, we documented operating playbooks so we could onboard on-call engineers to the service seamlessly to handle any alerts.
Dealing with gotchas
While our approach was good, it was by no means perfect, which meant that we had to deal with a few gotchas along the way. These included:
Gotcha #1: Analytics and tracking success metrics
Even though we didn’t implement a full rewrite, partially rewriting components and loading pages with a new stack led to unexpected analytics readings.This gotcha isn’t just specific to Next.js or SSR, but any major migration involving some form of rewrite. It’s critical to ensure product metrics are collected similarly for both the old and new product.
Gotcha #2: Next.js aggressively bundle splitting and preloading
We used client-side rendering within Next.js as a way to improve the server-side rendering performance, lazy load unneeded client-side features, and adopt components that were not ready to be rendered server-side. However, when lazy loading these bundles, which use the preload tag, we saw an increase in interactivity delays. The Next.js team already was aware of this potential performance issue because they are working on addressing more granular control over preloading of JavaScript bundles in a future release of Next.js.
Gotcha #3: Excessive DOM Size when Server Rendering
Web Performance best practices advocate maintaining a small DOM size of fewer than 1,500 elements, and a DOM tree depth less than 32 elements with fewer than 60 children/parent elements. On the server-side, this penalty can sometimes be felt even more so than on the browser as the Time to First Byte is delayed by the additional CPU processing required to fulfill the rendering of the request. In turn, the user can be waiting longer than desired looking at a blank screen while the page is loading, offsetting the expected performance gains that Serverside Rendering can provide. We refactored certain components and deferred loading of certain components to be lazy loaded to reduce the server side rendering overhead and improve performance.
Results
Migrating our pages to Next.js achieved +12% and +15% page load time improvements on Home and Store. LCP (one of Google’s core speed metrics) has improved 65% on Home and 67% on store pages. Leading indicator of Poor URLs (LCP > 4s) on Google has dropped by 95%.
Conclusion / Summary
To any engineers looking to migrate their stack to Next.js, we’d like to summarize our main takeaways from introducing Next.js to DoorDash:
- Performance: Adopting Next.js can lead to huge improvements in mobile web performance. Definitely use tools like https://www.webpagetest.org/ to audit existing performance before and after the rollout.
- Incremental Migration: To any team considering migrating their app to Next.js, we want to emphasize that an incremental approach can minimize full re-writes while allowing features to co-exist in both an old CSR and in new Next.js SSR apps.
- Rollout Strategy: We want to stress the importance of having a defined rollout strategy, and safe-guard fallback mechanisms to protect against site outages.
- Success Metrics: Lastly, the importance of having clearly defined success metrics, and ensuring the right tracking is in place to confirm the migration was successful.

