

Even state-of-the-art classifiers cannot achieve 100% precision. So, when we encountered a business problem on DoorDash’s ad platform that required an error rate of effectively zero, we turned to hybrid solutions that combine a classification model with human review. Here we explain the underlying entity linkage problem and show how to tune a fuzzy matching algorithm to reach extremely high precision without compromising recall.
Background: The types of ads a platform can run
There are many types of digital ads, even within a single company’s offerings. One simple example is DoorDash’s Sponsored Listings. A restaurant can promote its search result — and, optionally, a special offer — when a consumer searches for a relevant keyword in the DoorDash app. This is “simple” because an ad involves only three parties: DoorDash, the restaurant, and the consumer who will view the ad.
A more complicated example is DoorDash’s Sponsored Products, which introduces a fourth party: a consumer-goods brand whose items are sold through grocery or convenience stores on DoorDash. For example, suppose a consumer is browsing a grocery store’s DoorDash page, searching for “soda can” or clicking through categories. A brand owner — say “Fizzy Cola, Inc.” — can promote their offerings ahead of competing options, increasing awareness and sales. This is more complicated than the previous example because the advertiser, Fizzy, is a separate entity from the grocery store.
The challenge when the advertiser and store are different
When the advertiser and the store hosting the ad are different, it’s harder to set up a new ad campaign because there are more possible placements. For Sponsored Listings, it’s relatively easy — if a fast-food chain wants to advertise free fries with any purchase, they tell our operations team which item on the menu should be free. But for Sponsored Products, if Fizzy wants to promote “Diet Fizz 12 oz. can (6-pack),” it would require manually sifting through all catalogs from thousands of stores where the item is available on DoorDash to select matching items to promote. We set out to automate that matching process to simplify campaign creation enough that brand owners could do it themselves, as shown in Figure 1. Without such automation, it wouldn’t be feasible to scale our exchange beyond a few dozen advertisers.
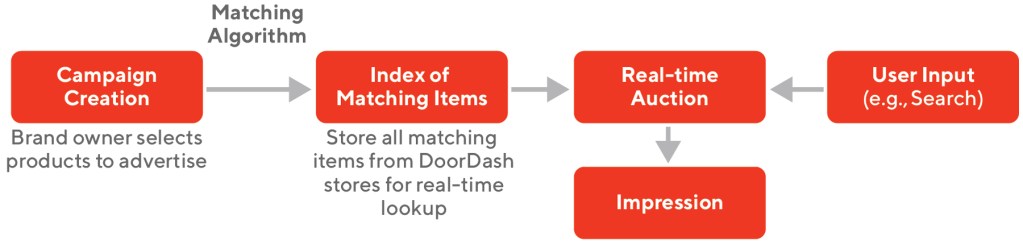
Existing solutions are inadequate. Exact item name matches are rare because of variations in minor details like word order or how size is represented. A more reliable identifier — but still not reliable enough — would be the ubiquitous barcodes on most packaged goods that represent universal product codes, or UPCs. Advertisers know the UPCs for their own products, but stores on DoorDash don’t always offer reliable UPC records to match against. Codes can be missing or incorrect, or sometimes the same product can be described by multiple UPCs, making it easy to miss matches. We found that UPC-based approaches yielded only about half of the matches we sought.
Stay Informed with Weekly Updates
Subscribe to our Engineering blog to get regular updates on all the coolest projects our team is working on
Please enter a valid email address.
Thank you for Subscribing!
Business requirements
Beyond UPC matching, we investigated custom solutions. Figure 2 illustrates the problem, which we framed loosely as classification: Given an item provided by an advertiser, find as many matches as possible (high recall) in DoorDash’s store catalogs while also generating few bad matches (high precision).

To use a software analogy, the advertiser’s product is like a class and DoorDash’s store catalogs contain millions of instances with mutations in attributes such as item name. Or from philosophy, the product is like an ideal platonic form. Our goal is to trace each imperfect catalog item back to the class (or form) from which it originated.
False negatives and false positives carry different business costs:
- A false negative means missing a match. The advertiser won’t get to advertise their item at that store and DoorDash loses ad revenue. On a healthy ad exchange, revenue loss is not quite linearly proportional to false negatives, because ad auctions tend to have multiple participants. We set a soft target of identifying 80% of all true matches.
- A false positive — generating a bad match — can be much costlier. It depends on the type of mistake. For example, if we mistook a 12-pack of Diet Fizz for a 6-pack of Diet Fizz, then at worst the advertiser would be annoyed. We set a soft target to mess up minor attributes like quantity, size, and flavor in fewer than 5% of matches. But if we mistook a competitor’s soft drink for Fizzy Cola it would be a nightmare — Fizzy asked us to promote their product, but we instead promoted a competitor’s. To add insult to injury, we would automatically bill Fizzy for the mistake. The rate of such an error must be zero.
Modeling approach
It would be unrealistic to expect even a powerful model to meet such strict requirements as 80% recall and especially 95 to 100% precision. Human assistance is essential to perform at that level, but a purely manual approach is infeasible at scale. Our prospective advertisers offer hundreds of thousands of unique products, and DoorDash’s convenience and grocery catalog contains millions of both redundant and unique items.
We settled on a hybrid approach:
- First, a fuzzy matching algorithm compares advertiser product names against DoorDash store items to generate match candidates. In short, the algorithm considers each word separately and generates a total score based on how many words match or nearly match, differing by only a character or two.
- Each candidate is then reviewed by at least one human. In this case, we contracted an external vendor.
With proper tuning, the algorithm ensures high recall (few false negatives) and human review ensures high precision (few false positives).
Tricks to tune the algorithm
The following techniques helped us maximize performance of the overall hybrid approach.
- Optimize the fuzzy threshold. By default, our matching algorithm returned the best advertiser product match for each store item, along with a confidence score from 0 to 100. Discarding matches that score below a threshold favorably trades recall for precision as shown in Figure 3. We typically chose a low threshold between 80 and 90 to keep recall high.

- Evaluate top k candidates. Sometimes the algorithm’s favorite candidate is a bad match and one of the runner-ups is correct. Exposing more than one candidate for human evaluation — typically three to ten — greatly increased the hybrid approach’s precision and especially recall. The cost is more time spent evaluating, but that’s lower than it seems because auditors find it efficient to review similar candidates in quick succession; and after finding a match, they can skip any remaining candidates in that batch.
- Limit the search space. False positives occur only when the pool of possible matches is large. For our application, to find a match for an item somewhere in DoorDash’s catalog, the search pool consists of hundreds of thousands of advertiser products. We simplified the problem for the beta launch of the Sponsored Products ad exchange by allowing only a handful of advertisers to participate. This shrank the search space by more than a factor of 10, improving the precision of our beta algorithm without losing recall as well as buying time to continue developing it.
- Apply metadata constraints. Similarly, metadata — features beyond item name — can restrict the match search. The most useful dimension we found was item quantity. For example, if a brand owner labels their product “qty 6” while a store labels a possible match candidate “qty 12,” then the two items almost certainly are different and there’s no need to compare names. However, edge cases matter: “qty 1” and “qty 12” might be a match if the intention behind the former was “one case of 12.” We also considered aisle metadata, but it was too inconsistent; for example, frozen taquitos might sometimes be categorized as “snacks” and sometimes “frozen”. Finally, we looked at size metadata, but the edge cases included challenging issues such as unit conversion and decimal precision.

To accommodate deadlines and limited contractor resources, we also tuned our approach according to the business impact we expected. For example, we lowered the fuzzy threshold and increased k when checking items carried by DoorDash’s most popular stores, concentrating our review there to maximize the number of matches found.
Without directly changing the base fuzzy matching algorithm, the last three improvements above enhanced its performance from 27% precision and 54% recall to 38% precision and 73% recall. After adding human review as a second step and further tuning for business impact, the hybrid approach met our aggressive requirements.
Other applications of product matching at DoorDash
In addition to the ad exchange, these product matching techniques also contribute to streamlining our universal retail catalog. Matching items from individual store catalogs to a single universal catalog helps to improve the consumer experience by filling in missing metadata, such as photos. We currently use both UPC matching and fuzzy matching for this process, but we are investigating other types of item identifiers like price lookup codes to improve support for weighted items.
Conclusion
To create a catalog data infrastructure for a scalable ad exchange, we combined fuzzy matching with manual review, ultimately achieving high recall and very high precision when mapping advertiser items to those offered through DoorDash. Without changing the base algorithm, we demonstrated a few techniques to improve performance that should generalize well to other record linkage problems.
Acknowledgments
The authors thank Kyle Tarantino and Sam Eade for designing the manual review process and Hai Yu for proposing item quantity and size constraints.
