

DoorDash is supporting an increasingly diverse array of infrastructure use cases as the company matures. To maintain our development velocity and meet growing demands, we are transitioning toward making our stateful storage offerings more self-serve. This journey began with Kafka, one of our most critical and widely used infrastructure components.
Kafka is a distributed event streaming platform that DoorDash uses to handle billions of real-time events. Our engineers — the primary users of this platform — manage Kafka-related resources such as topics, users, and access control lists, or ACLs, through Terraform. However, managing these resources manually was cumbersome and created a significant support burden for our infrastructure engineers because of the need to review and approve multiple pull requests.
To address this, we developed Kafka Self-Serve, our flagship self-serve storage infrastructure platform. Kafka Self-Serve empowers product engineers to onboard and manage their Kafka resources with minimal interaction from infrastructure engineers. This system was built in response to feedback from our product engineers and a careful examination of the support burden on our infrastructure team.
Here we share our Kafka Self-Serve platform development journey, the challenges we faced along the way, and the solutions we implemented. We hope to provide valuable insights that can help the broader tech community embark on similar journeys toward self-serve infrastructure.
The pain points
Before we implemented the Kafka Self-Serve platform, we faced several significant challenges in managing Kafka resources effectively. These pain points affected both our customers — product engineers — and our infrastructure engineers:
Customer pain points
- Confusion with Terraform’s manual onboarding: Terraform, our primary method for onboarding and managing Kafka resources, was cumbersome and confusing for our customers, requiring them to create topics and configure properties manually. This often led to errors and inefficiencies.
- Difficulty debugging misconfigurations: When customers misconfigured their Kafka topics, it was challenging for them to debug the issues. They frequently needed to seek help from infrastructure engineers, which caused delays and added to the engineers' workload.
- Complicated and unclear documentation: Our documentation, which lacked definitive best practices guidelines, was often complex and unclear.This made it difficult for customers to understand and follow the correct procedures for managing Kafka resources.
- Need for abstracted configurations: Many Kafka topic configurations could be abstracted or set to recommended default values. But customers had to manually configure these settings, increasing the likelihood of errors and misconfigurations.
- Difficulty viewing topics: Kafka topics were buried in directories within our Terraform GitHub repository, making it difficult for customers to view their topics, further complicating the management process.
- Insecure and inconvenient user password retrieval: When customers created Kafka users, they needed to ask infrastructure engineers for the passwords. Passwords were sent via direct message on Slack, which was not only inconvenient and time-consuming but also posed a security risk.
Infrastructure engineer pain points
- High support noise: Our manual and error-prone processes led to frequent support requests from product engineers, creating a significant burden for infrastructure engineers. This constant noise diverted their attention from more strategic tasks.
- Limited control over traffic enforcement: Without a centralized automated platform, it was challenging to enforce traffic policies and ensure consistent configurations across different teams. This lack of control could lead to inconsistent practices and potential performance issues.
- Scalability challenges: As the number of teams and use cases grew, managing Kafka clusters manually did not scale well. The infrastructure team struggled to keep up with the increasing demand, leading to delays and potential bottlenecks.
- Reliability guarantees for shared Kafka: Significant manual effort was required to ensure reliability for shared Kafka clusters. There were no built-in mechanisms to guarantee reliability, increasing the risk of downtime and data loss.
- Ownership and delegation: Effective management of both shared and dedicated Kafka clusters required clear ownership and the ability to delegate responsibilities. Infrastructure engineers needed a way to take ownership of shared Kafka clusters while delegating management responsibilities for dedicated clusters to power users.
Our Kafka Self-Serve platform was designed to address each of these pain points to not only empower product engineers but also to support and streamline the work of infrastructure engineers, leading to a more efficient and scalable system.
Design and implementation
As we delve into the details of our design and implementation processes, note that some decisions described here are tailored specifically for DoorDash Engineering. Nonetheless, the underlying principles and thought processes are broadly applicable to any organization looking to streamline their Kafka resource management.
Level of abstractions
It's a common misconception that making infrastructure self-serve is simply about building a UI to allow people to create infrastructure. While that is the eventual outcome on the surface, the true goal goes deeper. To solve the pain points outlined above, the focus should be on establishing the proper level of abstractions. Our approach involved:
- Hiding complex configurations: We strove to hide many of the intricate configuration options for Kafka topics, exposing only the essential settings related to topic capacity. This simplification helped users avoid common pitfalls and misconfigurations.
- Enforcing best practices by default: By abstracting complex configurations, we inherently enforced best practices. This ensured that users followed the optimal configurations without needing to understand the underlying details. On this paved path, it should be hard to make mistakes.
High-level design
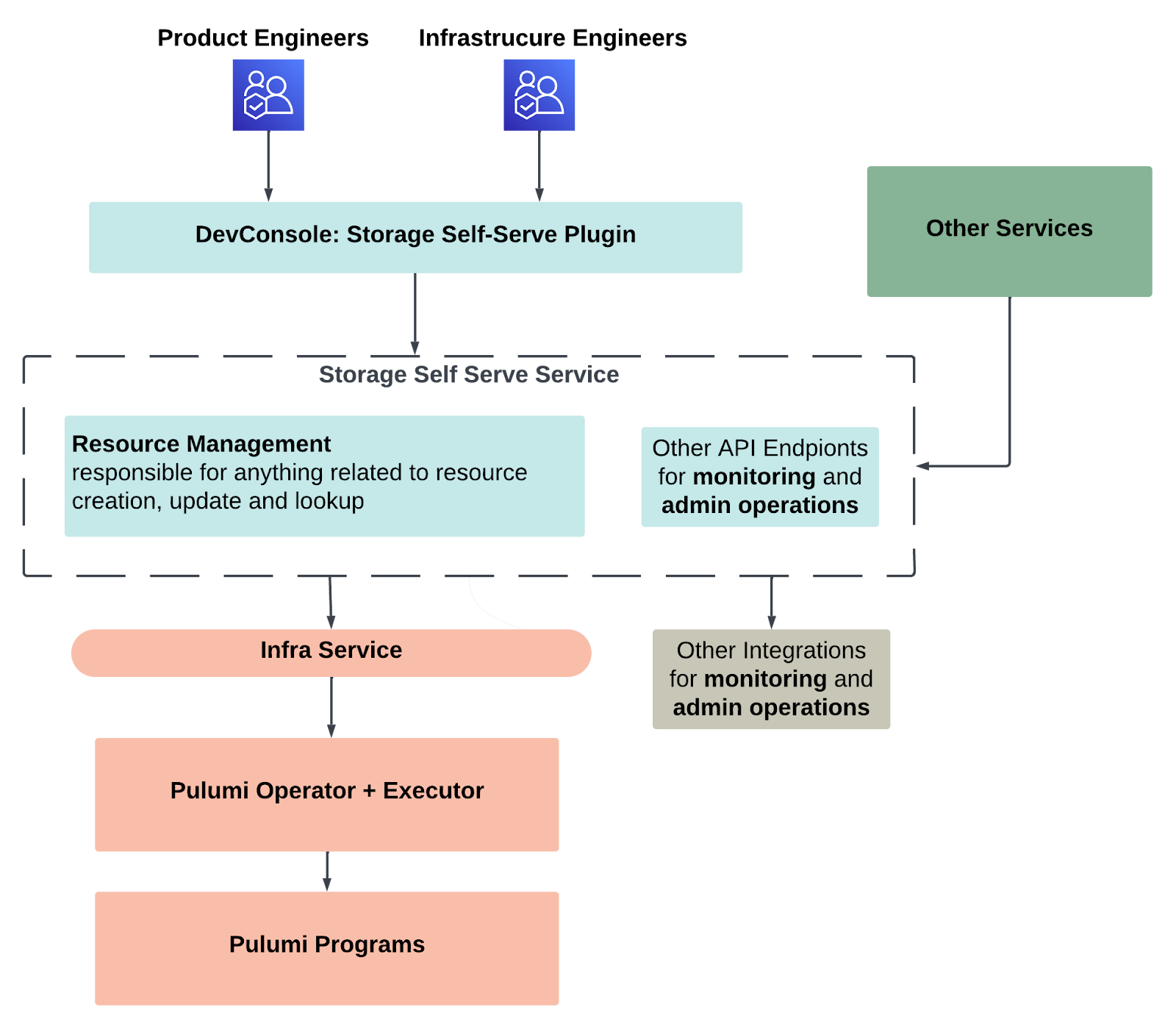
Figure 1 provides a high-level overview of Kafka Self-Serve’s architecture:
- User interaction through DevConsole: Both product and infrastructure engineers interact with the platform via the DevConsole — an internal portal for developers based on Spotify Backstage — specifically through the storage self-serve plugin. This plugin serves as the user interface, providing an accessible and intuitive way for engineers to manage their Kafka, Redis, CRDB, and other infrastructure resources.
- Storage self-serve service: At the core of our platform is the storage self-serve service, which orchestrates the entire workflow. This service has two main components:
- Resource management: This component handles all API requests related to resource creation, updates, and lookups. It ensures that all resource management tasks are executed efficiently and reliably.
- Other API endpoints: These endpoints are dedicated to monitoring and admin operations, providing visibility and control over the managed resources.
- Infra service: The infra service is responsible for the actual execution of resource management tasks. It leverages Argo Workflows to execute Pulumi programs to provision and manage infrastructure resources. Underneath infra service, we have our own Kafka Pulumi plugin which utilizes the official Kafka provider. We will delve into more detail in the next section.
This high-level design ensures that our Kafka Self-Serve platform is both scalable and user-friendly, enabling engineers to manage their resources efficiently without requiring deep knowledge of the underlying infrastructure.
Infra service: Generic API over infra-as-code
While infrastructure-as-code, or IaC, tools like Pulumi are powerful, we realized that alone they were not sufficient for building a truly self-serve Kafka management platform. We needed something that provided a higher level of abstraction over IaC, allowing us to create a more user-friendly and efficient solution. To achieve this, we developed infra service to manage the resources life cycle as shown in Figure 2 below.

The goal was to create a generic framework that allows infrastructure engineers to build plugins for different types of resources, enabling self-serve experiences tailored to the needs of product engineers.
Besides Kafka, we already have plugins for managing AWS S3 buckets, AWS ElastiCache clusters, and CockroachDB users. Infra service exposes a CRUD API (create/read/update/delete) that can be invoked for any registered plugin type, making it a versatile and powerful tool for our infrastructure needs.
We will delve deeper into infra service and its architecture in a dedicated blog post soon, so stay tuned for more details.
Permissioning and auto-approvals
At DoorDash, we use SASL/SCRAM (salted challenge response authentication/simple authentication and security layer) authentication alongside ACLs to control which services — including producers and consumer groups — can access each Kafka topic. The high-level flow for onboarding and using Kafka involves the following steps:
- Request a Kafka topic: Developers request the creation of a new Kafka topic.
- Request a Kafka user: If the service does not already have a Kafka user, a request is made to create one.
- Request access level: Developers request the necessary access levels (read, write, describe) for their Kafka users.
Each of these requests traditionally required review and approval from the infrastructure team. This process was time-consuming and heavily manual, creating bottlenecks and delaying project timelines.
To streamline the approval process, we implemented auto-approval designs for specific Kafka resource changes. This automation is crucial because it reduces the dependency on manual reviews, allowing for quicker provisioning and enabling developers to move faster. By setting predefined criteria for auto-approvals — for example, creating new users is considered safe and auto-approved — we ensured that routine and low-risk requests could be processed automatically, while still maintaining control and oversight for more critical changes.
Migrations
It’s not easy to migrate from Terraform-backed Kafka resources to Pulumi-backed Kafka resources. We developed a series of scripts to bulk import and streamline the process. The specific migration process depends on design and which providers are used. Specifically, we use the official Pulumi Kafka provider and we migrate from the popular mongey/terraform-provider-kafka. It's worth noting that the official Pulumi Kafka provider uses the same Terraform provider underneath. We encountered two interesting challenges:
User import complications
Problem
When migrating Kafka users, we faced several significant challenges, including:
- Terraform lacks import support: The underlying Terraform module does not support importing Kafka users. This limitation meant that the usual import process could not be applied to SCRAM users, causing significant delays and difficulties.
- Password retrieval issues: We no longer had access to the actual passwords for existing users because Kafka does not store them for SALT challenge authentication. For newer users created by more recent versions of Terraform, the passwords were stored securely, but we needed to handle older users differently.
Solution
To work around these issues, we implemented the following steps:
- Simulated import by creating new users in Pulumi: We approached the import process by creating new users in Pulumi to effectively override the users on Kafka with the same password. This method, however, introduced the risk of overwriting existing passwords.
- Additional validation: To mitigate the risk of password overwrites, we added validation steps using kafka-cli to ensure that the passwords were valid and consistent.
- Password retrieval from secure sources: We loaded passwords from secure storage solutions like 1Password and AWS Secrets Manager. In cases where passwords were not found, we reached out to individual teams for assistance.
Topic config complications
Problem
When migrating Kafka topics from Terraform to Pulumi, we faced the significant challenge of ensuring that the topic configurations matched exactly. Here are the specific problems we faced and the solutions we implemented:
- Exact config mapping requirement: When creating a topic through Terraform, a configuration mapping can be specified to set additional properties such as retention.bytes, min.insync.replicas, and more. When importing these topics into Pulumi, configurations must match the Terraform provider’s values exactly. This added difficulty to the task because each version of the Terraform provider had different default values. It was not possible to generalize the default values to match. It required time to seek default config values for each possible version. If these values did not match exactly, Pulumi failed the import.
- Configuration discrepancies: It was impractical and error-prone to manually ensure that every configuration setting was consistent between Terraform and Pulumi. Even minor mismatches could cause significant problems in a production environment.
Solution
To address these challenges, we developed a series of auditing scripts to automate verification and correction of topic configurations, including:
- Auditing scripts: These scripts load the configuration details from the Terraform state and compare them with the desired Pulumi configuration. This allowed us to identify discrepancies between the two configurations.
- Automated matching: The scripts automatically adjusted the Pulumi configurations to match the existing Terraform settings exactly. The script pulled the default value for the provider, but if a config value was used that differed from the default, that value was used instead. This ensured that all topics were configured correctly during the migration process, eliminating the risk of errors caused by manual configuration.
- Consistency checks: After the initial matching process, we implemented additional consistency checks to verify that the configurations remained aligned during the transition. These checks provided an extra layer of assurance that the migration was successful and that all topics were configured as expected.
Impact
The transition to a fully self-serve model for Kafka resource management has brought significant benefits to our customers and the engineering team. Let's delve into some of the key wins we've achieved through this initiative.
Customer accolades
Before looking at the improvements and wins in a more quantitative manner, let’s hear a few words from our customers:
“In the past, when we wanted to add a new Kafka topic, we had to first understand the existing configuration by reading code from multiple code repositories before commiting code changes, posting the pull request to a Slack channel, and finding the right person to ask for approvals. It could take several hours because of the multiple-step operations. Now we can simply fill in a form in the UI and click the submission button, then everything is done in just a few minutes!”
-Dax Li at Store Platform
“With Storage Self-Serve Kafka, it's now all in one place. I can point a new developer to the Dev Console Kafka Self-Serve Storage UI to begin creating a Kafka topic immediately and to see several great pointers regarding standard Kafka usage and visibility. I'm also a happy customer; I was able to create 20 production Kafka topics in less than half a day.”
-Robert Lee at Performance Platform
“The new self-service portal makes it so much easier to configure Kafka topics. Less time spent on remembering exactly which TF file the topic data was stored in (each cluster had a different pattern based on when the cluster was made) and more time spent building features leveraging Kafka.”
-Patrick Rogers at Observability
Velocity improvements
- Kafka resource creation and management is now fully self-serve, with 23,335 resources onboarded.
- Various UI improvements have led to an 80% reduction in average loading time.
- The average Kafka resource creation time has been reduced 99%, from 12 hours to under five minutes.
Reliability improvements
- Validations are built into the tool to enforce best practices at creation time.
- The storage team can now enforce Kafka topic disk usage to properly size our Kafka clusters, preventing us from ever running out of disk space on a Kafka cluster — which is disastrous and hard to recover.
- Admin options can now be handled efficiently by Infra engineers to quickly mitigate incidents.
Insights
Building out our Kafka Self-Serve system has been a transformative journey, filled with valuable lessons and insights. In this section, we want to share some of the key things we learned through this process.
Talk to your customers
As infrastructure engineers, it's easy for us to build infra abstractions without fully understanding what product engineers actually care about. To ensure that our Kafka Self-Serve system truly met the needs of our users, we prioritized open and continuous communication with our customers, the product engineers.
Here are some specific steps we took:
- Regular feedback sessions: These were conducted with product engineers to gather their input on the current system and understand their pain points. These sessions were crucial in identifying the specific features and functionalities that would have the biggest impact on their workflow.
- User-centric design: By focusing on the end-user experience, we ensured that the platform was intuitive and easy to use. We designed the system with the product engineers in mind, emphasizing simplicity and usability.
- Iterative development: We adopted an iterative development approach, releasing incremental updates and features based on user feedback. This allowed us to address any issues quickly while continuously improving the platform.
- Cross-functional collaboration: We worked closely with cross-functional teams, including product management and UX design, to ensure that our technical solutions aligned with the overall product strategy and user needs.
- Surveys and user testing: In addition to feedback sessions, we used surveys and user testing to validate our assumptions and gather quantitative data on user satisfaction and usability. This data-driven approach helped us to make informed decisions and prioritize development efforts.
By actively engaging with our customers, we were able to build a Kafka Self-Serve system that not only solved the technical challenges but also provided real value to product engineers. This customer-centric approach was key to the project’s success.
Infrastructure engineers as first-class citizens
On the flip side, it's easy to ignore the needs of infrastructure engineers and concentrate on shipping a platform that is focused purely on doing things faster. However, it's equally, if not more, important to ensure that the self-serve infrastructure platform — in this case Kafka — serves infrastructure engineers as well.
Here’s how we approached this:
- Enforcing best practices by default: We made sure that the platform enforced best practices automatically. This not only helped maintain consistency across all Kafka resources but also ensured that developers could follow the recommended configurations without needing to know the intricate details.
- Reducing review time: One of our key goals was to reduce the amount of time needed to review requests. By implementing auto-approvals for low-risk changes and building robust validation checks, we minimized manual intervention by infrastructure engineers. This allowed them to focus on more critical tasks while still maintaining control over the infrastructure.
- Building complementary automations for maintenance: These automations for maintenance tasks were built in from day one. This included automated monitoring, alerting, and remediation processes to help keep the Kafka infrastructure healthy without constant manual oversight. We are also building out our infra control plane to automate all our operations and maintenance tasks. These automations significantly reduce the operational burden on infrastructure engineers.
By considering the needs of infrastructure engineers and making them first-class citizens in our design, we created a self-serve platform that not only empowered product engineers but also supported and streamlined the infrastructure team’s work. This holistic approach was crucial for the sustainable success and scalability of Kafka Self-Serve.
Service level resources vs. resource level
Often, an infrastructure resource — such as a Kafka topic — is tied to a service. This relationship can affec how you choose to manage and organize these resources. To accommodate different use cases and preferences, we built support for both service-level and resource-level management.
- Service-level management: This approach allows for managing all Kafka resources tied to a particular service as a single unit. It’s beneficial for scenarios where changes need to be applied consistently across all resources associated with a service. This method simplifies the management process for teams that prefer to handle their infrastructure at a higher level of abstraction.
- Resource-level management: This approach provides more granular control, enabling developers to manage individual Kafka topics, consumer groups, and specific configurations. This flexibility is crucial for fine-tuning and optimizing specific resources without impacting the broader service. It allows teams to make precise adjustments and optimizations based on the unique needs of each resource.
By supporting both service-level and resource-level management, we ensured that our Kafka Self-Serve platform could cater to the diverse needs of our engineering teams. This dual approach provided the flexibility needed to manage resources effectively, whether at a high level or with fine-grained detail.
Next steps
As we continue to improve the Kafka Self-Serve platform and expand our other self-serve infrastructure offerings, we have several key initiatives planned, including:
Specific to Kafka
- Expand on auto-decision: We plan to enhance our auto-decision mechanisms to cover a broader range of Kafka resource changes. This will further reduce the need for manual reviews, allowing engineers to move even faster while maintaining a high level of security and compliance.
- Expand on credential automation: Automating the management of Kafka credentials is a top priority. We aim to develop more sophisticated tools for generating, distributing, and rotating credentials automatically, ensuring secure and seamless access to Kafka resources without manual intervention.
Broader initiatives
- Expand storage self-serve: Beyond Kafka, we are focused on extending our self-serve capabilities to other storage systems. This includes enhancing our current offerings for AWS S3 buckets, AWS ElastiCache clusters, and CockroachDB users, as well as integrating new storage solutions based on emerging needs.
- Expand storage self-serve control plane: We are building out our infra control plane to automate all our operations and maintenance tasks. This will include advanced monitoring, alerting, and self-healing capabilities to ensure our storage infrastructure remains robust and resilient. By automating these processes, we can further reduce the operational burden on our infrastructure engineers and improve overall system reliability.
- Expand on disk and throughput quota: To better manage resource allocation and ensure fair usage, we will expand our capabilities to set and enforce disk and throughput quotas for Kafka topics and consumer groups. This will help prevent resource contention and ensure that all teams have the necessary capacity to operate efficiently.




