What is Variance Reduction?
Strategies that attempt to reduce the variance of a target metric are known as variance reduction techniques. Common variance reduction techniques include stratification, post-stratification, and covariate control. CUPAC falls into the covariate control category. To more clearly illustrate what variance reduction seeks to accomplish, consider the distributions for the test and control observations in Figure 1 below:
Reducing Variance using Linear Models
The standard t-test for a difference in population averages can be generalized to a regression setting using an approach known as ANOVA (Analysis of Variance). In the most basic version of this approach, the treatment indicator T is regressed on the outcome variable Y. The estimated value of the coefficient on T, typically denoted as β̂ , is then compared to its own standard error. We conclude that the treatment effect is statistically significant if this ratio is sufficiently large. This regression approach can be then extended to include control variables that help explain the variation in Y not due to the treatment T. The expansion is straightforward and involves adding X to the regression of T on Y, where X is the vector of covariates. Note that for our measurement of the treatment effect to remain valid under this extension, each of these control variables must be independent of our treatment T.  To make this concrete, let’s again consider measuring changes in ASAP times. A potential control variable for such a test would be the travel time between the restaurant and the consumer (as estimated at the time of order creation). Under the assumption that our treatment is assigned randomly and that it does not meaningfully affect road conditions, this variable should be independent of our treatment T. In addition, it should have significant explanatory power over the ASAP time, Y. As a result the standard error on β̂ , the coefficient on T, will be significantly smaller after the introduction of this covariate, making it easier for our test to achieve statistical significance.  Using Predictions as Covariates in Linear Models
CUPED (Controlled-experiment Using Pre-Experiment Data) delivers variance reduction through the inclusion of control variables defined using pre-experiment data. The key aspect of this approach is the insight that pre-experimental data is collected before a randomly assigned treatment effect is introduced. Such variables must be uncorrelated with the treatment assignment and therefore are permissible to include as controls. To build on this approach, we defined an approach to variance reduction we call CUPAC that uses the output of a machine learning model as a control variable. CUPAC involves using pre-experiment data to build a model of our outcome variable Y using observation-level features. As long as these features are uncorrelated with the treatment T during the experimental period, this estimator ŷ — as a function of these features — will also be uncorrelated with T. As a result, it is permissible to include such an estimator as a covariate.  The amount of variance reduced by CUPAC scales linearly with its out-of-sample partial correlation with the outcome variable Y, given other control variables. When improving model performance (hyperparameter tuning, feature engineering, etc.), we therefore recommend aiming to maximize the partial correlation between the prediction covariate (CUPAC) and the target metric. Using an ML-based covariate represents an improvement over competing control strategies for multiple reasons. First, an ML-based encoding of our outcome variable generalizes CUPED to situations where the relevant pre-experiment data is not clearly defined. For example, in logistics experiments at DoorDash pre-experiment data does not exist at the delivery level in the same way that it does for a market or customer-level test. While there are multiple pre-experiment aggregates that can be used as proxies (e.g. the average value of the outcome Y during the same hour the week before), all such averages can be viewed as simple approximations to a ML-based control model specifically designed to maximize the partial correlation with the outcome variable. Second, an ML-based encoding of our outcome variable will capture complex relationships between multiple factors that a set of linear covariates will miss. In nature, nonlinearities and complex dependencies are not the exception, but the rule. ML models such as ensembles of gradient-boosted trees are uniquely suited to capture such complex interaction effects. Finally, an ML-based approach to control can reduce the computational complexity of variance reduction. Prior to implementing CUPAC, we had used multiple categorical covariates in our experiment analysis. As such regression analysis requires categorical variables to be one-hot encoded, excessive cardinality can make the required calculations computationally expensive. By replacing a large number of variables with a single ML-based covariate, we are able to significantly reduce runtime.Increasing Experimental Power using CUPAC
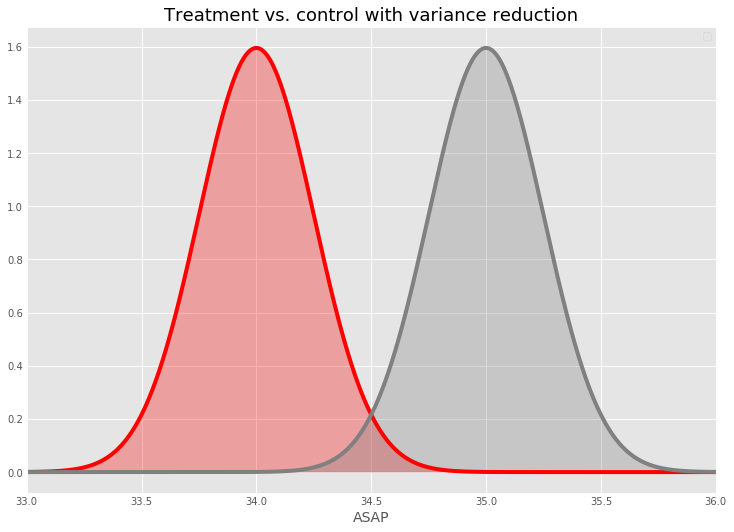
In offline simulations, CUPAC consistently delivers power improvements across a variety of effect sizes. The graphic below shows how CUPAC reduces the time required to detect a 5 second ASAP change with 80% power relative to a baseline model with no controls. We include results for each of the 4 random subsets of markets we currently use for switchback testing. On average, CUPAC drives a nearly 40% reduction in required test length vs. baseline and a 15-20% improvement when compared to alternative control methods. While the magnitude of these effects varies across market groups, in each instance CUPAC proves itself to be the most powerful control method.