

We've traditionally relied on A/B testing at DoorDash to guide our decisions. However, when precision and speed are crucial, this method often falls short. The limited sensitivity of A/B tests - their ability to detect real differences between groups - can result in users being exposed to suboptimal changes for extended periods. For example, in our search and ranking use cases, achieving reliable results often required several weeks of testing across all traffic, which not only delays the introduction of new ideas but also prolongs the negative impact of underperforming changes.
Interleaving design offers significantly higher sensitivity - more than 100 times that of traditional methods - by allowing multiple conditions to be tested simultaneously on the same user as shown in Figure 1. Interleaving design generally provides a more accurate and granular understanding of user preferences, allowing us to iterate more quickly and with higher confidence.
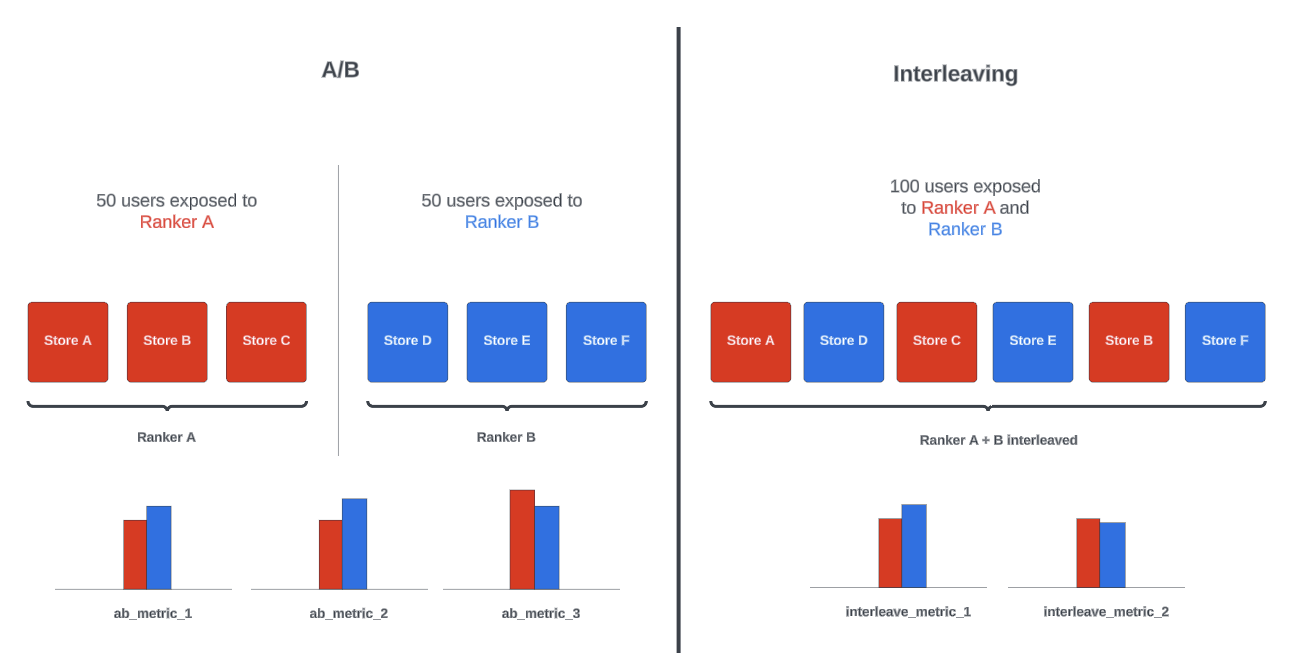
In this post, we dive into how we've implemented interleaving designs at DoorDash. We also explore how we've refined the design to be even more sensitive than what is reported in the industry (see Table 1), discuss the challenges we've faced, and provide recommendations for handling those challenges.
| Company | Sensitivity Gain |
| Netflix | ~100x |
| Airbnb | ~50x to ~100x |
| Thumbtack | ~100x |
| Amazon | ~60x |
| Wikimedia | ~10x to ~100x |
| Etsy | ~10x to ~50x |
| Doordash | ~100x to ~500x |
What makes interleaved designs highly sensitive
Almost all experimentation statistics can be summarized in the conceptual formula that looks at signal-to-noise ratio. If you want experiments that provide more clear insights, you can:
- Boost the signal: Test changes that are meaningful, where hypotheses are grounded in common anecdotes or data. This also requires ensuring users are exposed to and engaged with the change.
- Reduce the noise: Explain away the noise using techniques like CUPED — controlled experiment using pre-experiment data — or generate populations that are more homogenous. Alternatively, you can also opt to increase sample sizes.
Most folks have assumed that interleaving provides sensitive results by reducing noise. Specifically, because a user is exposed to all treatment conditions, the design naturally helps drive variance down because each user serves as their own control. But alongside this benefit, we noticed that setting up interleaving helps improve the signal in the data through two properties, as shown in Figure 2:
- Identifies non-engagement: Interleaving allows identification of users who are not actively engaging with the content so that they can be removed.
- Identifies noncompetitive pairs: We also can identify cases in which rankers generate similar-looking lists, allowing us to boost the signal by removing data where recommendations between treatment and control is too similar.

Both of these techniques allow you to improve interleaving sensitivity even further because they effectively eliminate data dilution, as seen in our previous post on dilution. In the next section, we elaborate on why these three drivers are so important in driving up sensitivity.
Controls for within subject variance
A fundamental reason for why interleaving designs are so much more sensitive than regular A/B designs is that the same user is tested under multiple conditions, allowing each participant to serve as their own control. For example, the device used, a user's search preferences, or other relevant information are all controlled by the nature of the design. Internally, when explaining the benefits of interleaved designs to stakeholders, we say that it's like running A/B tests in which all your subjects are identical twins. But not just any twins - these are perfect clones who share the same phenotype and environment right up to the moment you run the test. This imagery helps people understand that interleaved designs have an enormous potential to drive down variance. Despite the widespread use of within-subjects (repeated) designs in industries such as pharma, education, neuroscience, and sports science, their relative lack of adoption in the tech industry remains a surprising anomaly.
In interleaving, the effect of within-subjects design is even more pronounced because we simultaneously present the treatment conditions on the same screen at the same time, minimizing confounding variables such as learning effects, crossover effects, or other time-based confounders as shown in Figure 3. In the context of DoorDash, one of the biggest confounders is user hunger level when they come to our app. Rather than presenting one ranker on Day 1 and another ranker on Day 2, presenting them in the same context allows us to remove noise driven by satiety levels.

Handles dilution from competitive pairs
Interleaved designs also drive up sensitivity by showing if the experience exposed to the user is truly different between treatment and control. An interleaved design generates final output from two lists, allowing us to identify immediately whether those lists are too similar, as shown in Figure 4 below. In most machine learning applications, different modeling approaches are improvings things on the margin. In many cases, the search results returned by two rankers will largely overlap. An interleaved design lets us measure this overlap and analyze the data for competitive pairs - where rankers disagree on the recommendation - which leads to a signal boost.

Handles dilution from non-engagement
An interesting observation we made when looking at interleaved experiments - as well as search and ranking experiments in general - is that many user actions make it look as if the user is not paying attention or making any choices on the presented content. For instance, although we would generate a carousel with interleaved options, the user would not actively engage with the content and make a decision. As a result, including this data in interleaved analyses dilutes the signal.
Here is another way to understand non-engagement. Let's say we present a user with two drinks - Coke and Pepsi - and ask them which they like more. If the user does not engage or refuses to try any options, it might indicate:
- The user is not interested in the presented results.
- The user is not in a decision-making mindset at the moment.
While these are important insights, examining data from this undifferentiated feedback does not help to determine user preference or understand which drink is preferred. Attention and non-engagement is a fascinating research subject; many folks approach it by looking at additional metrics such as dwell time or how often a user backtracks as per Chucklin and Rijke, 2016. Fortunately, interleaving allows us to identify non-engagement more effectively so that we may remove impressions that are not meaningful. If a user does not take an action, we simply remove the exposure rather than marking the performance of the interleaved ranker as a tie.ctively so that we may remove impressions that are not meaningful. If a user does not take an action, we simply remove the exposure rather than marking the performance of the interleaved ranker as a tie. A/B tests can't effectively address non-engagement because they treat all data equally, including non-engaged interactions, which dilutes the signal and obscures true user preferences.
Results
Table 2 shows results across five online experiments in which we provide the average relative sensitivity improvement across different methods relative to an A/B setup. Across several experiments, we found that removing dilution helped boost interleaving sensitivity even more, which leads to much smaller required sample sizes. These results were so surprising even to us that we had to stop several times to conduct additional A/A tests to validate that we had not introduced a bug in our SDK, analysis pipeline, or metrics computation.
| Experiment | Vanilla Interleaving | Vanilla Interleaving + Removing Dilution | % Traffic Used |
| Exp 1 | 34x | 282x | <5% |
| Exp 2 | 67x | 482x | <5% |
| Exp 3 | 68x | 312x | <5% |
| Exp 4 | 109x | 545x | <5% |
| Exp 5 | 60x | 301x | <5% |
| Avg Improvement | ~67x | ~384x |
It's important to highlight that the sensitivity improvement depends on the metric. For clickthrough rate, we have observed half of the sensitivity boost observed in the checkout-conversion metric. Nonetheless, across all use cases we found that removing dilutive exposures drives very large gains in sensitivity.
Configuring and evaluating interleaving experiments
Interleaved designs are fully supported at DoorDash, with seamless integration across our SDK, experimentation UI, and internal analysis tools. This tight integration ensures that teams accustomed to A/B testing can transition to interleaving designs in a standardized manner, minimizing onboarding effort. In this section, we explore key implementation details for how we incorporated interleaving randomization in our experimentation SDK.
Traditional A/B experiments know the values that should be served at the time the experiment is configured. At its simplest, an A/B experiment would be configured with the values of either false - for the control experience, or true - for the treatment experience that enables the feature. At runtime, the business logic would read the true/false value directly from the experiment.
Consider this traditional A/B client interface:
interface TraditionalClient {
fun getBoolean(
// The name of the experiment to evaluate
name: String,
// Contextual information to determine outcome and randomization
context: Context,
// A safe value to use in case of errors
fallback: Boolean,
): Boolean
}Calling the client could look like this:
val isEnabled = client.getBoolean("is_new_feature_enabled", Context(), false)
If (isEnabled) {
newFlow()
} else {
oldFlow()
}Interleaving differs from traditional A/B in that the lists of objects being interleaved cannot be known at configuration time. However, this distinction does not prevent us from using our existing experiment objects to control an interleaving experiment flow. For example, an experiment interface still helps us with:
- Deciding who should be part of the experiment
- Slowly adding more users to the experiment
- Remotely turning off the experiment
- Selecting a winning variant
For interleaving experiments, the variants tell us which, if any, lists should be interleaved instead of explicitly telling us what value to serve.
An interleaving client would look like this:
// The client can interleave any object as long as it implemented 'Interleavable'
interface Interleavable {
// The type of object. 'store' as an example
fun itemKey(): String
// A unique key representing the underlying object. The store's ID an example
fun itemId(): String
}
// Essentially a named list of objects that may be interleaved
interface InterleaveData<T : Interleavable> {
val name: String
fun items(): List<T>
}
interface InterleavingClient {
// Templated interface. Pass in any object you want to interleave as long as it is "interleavable"
fun <T : Interleavable> interleave(
// A unique identifier used to connect the result to an analysis metric
interleaveId: String,
// The name of the experiment that controls if the experiment is enabled and what lists to interleave
experiment: String,
// Context that defines the user. Determines whether the user has access to the experiment
context: Context,
// A fallback list of items if anything goes wrong
fallback: InterleaveData<T>,
// A list of the named lists that might be interleaved as part of the result
vararg data: InterleaveData<T>,
): List<T>
}The experiment can be configured to separate different groups of users into segments. In traditional A/B, the matched segment ultimately decides what value is served to the user. Here, the matched segment decides which of the lists should be interleaved. This means that at runtime, you can pass in an arbitrary number of lists and dynamically choose a subset of them to interleave.
Example:
val control = FixedInterleaveData(
variantName = "control",
items = listOf(Food("apples"), Food("bananas"), Food("cucumbers")),
)
val treatment1 = FixedInterleaveData(
variantName = "treatment_1",
items = listOf(Food("oranges"), Food("apples"), Food("cucumbers")),
)
val treatment2 = FixedInterleaveData(
variantName = "treatment_2",
items = listOf(Food("oranges"), Food("tomatoes"), Food("bananas")),
)
val result = client.interleave(
interleaveId = "8346168",
experiment = "food_experiment",
fallback = control,
context = Context(),
// 3 different named lists are passed in
control,
treatment1,
treatment2,
)
Here we have 3 named lists of food: control, treatment_1, and treatment_2. The experiment food_experiment will ultimately decide which of these lists should be woven together based on the passed-in context and how food_experiment was configured. One, two, or all three lists could be selected.
You may notice that the underlying lists of food items are configured via fixed interleave data. Each array of items is realized immediately before even calling interleave. This could be problematic if you plan to test out multiple lists and the cost of generating each list is high. To avoid expensive and time-consuming calls, we also offer lazy interleave data:
data class LazyInterleaveData<T : Interleavable>(
override val variantName: String,
val itemGenerator: () -> List<T>,
) : InterleaveData<T>The engineer needs to provide the function responsible for generating the list without realizing the list immediately. The underlying interleaving client will execute the generators only for the subset of lists needed to interleave. This can help mitigate performance issues when the interleaved lists are very large.
Interleaving algorithm
As an abstraction, think of each list to be interleaved as containing players to be drafted for a single team. The same player may show up on each list but at a different rank. Assume each list of players is ordered from most- to least-favorite. To continue the analogy, let's look at an example in which we label the lists as teams.
The interleaving algorithm may more easily be explained with N team captains drafting their players. Imagine the following:
- Each captain has a list of players ordered from most- to least-desirable.
- Some players may exist on a few of the captains' lists, while others may only exist on a single captain's list.
- During each turn, all captains recruit a player to their team. Each captain calls out the most desirable player who has not already been selected.
- If all captains select different players, then we insert the players into each list in order of the captain's preference. The players then belong to the respective captains who selected them. All players are marked as competitive.
- If some captains attempt to select the same player during a turn, we find an untaken player in the captain's list. This player and all players added this turn are marked as not competitive.
- Competitive players will always come in group sizes equal to the number of captains.
- If any captain is unable to select a player in a given turn, then all players selected in that turn are marked as not competitive.
- Among the competitive selected players, there will be an equal number of picks by each captain.
Nearly identical lists example

This example highlights that the two captains make similar choices for the first four items, so those items are marked as not competitive. Only the last two items reflect a clear difference in captain recommendations.
Non-matching lists example

In this example, the first player is preferred by both captains. Because both captains have the same preference, performance due to player A is not considered when measuring the captains' success in drafting players. Using data from noncompetitive pairs would hurt the signal we can measure in the experiment.
How we handle event attribution
One of the most challenging aspects of setting up interleaving at DoorDash is figuring out how to handle event attribution. We've done an extensive literature review on this topic and talked with multiple practitioners from other companies that implemented interleaving. We were surprised to find very little consistency in the approach to performance attribution.
The most common approach is to aggregate a preference score across either a single or multiple sessions or even over days for each user. The outcome, run through the formula shown in Figure 5, computes for each user a score that encapsulates if they like ranker A or B based on their click behavior.

While this approach can work, it has two challenges:
- Emphasizes clicks: This approach limits your ability to look only at clicks to compute preference scores. For example, one ranker would get a win from driving more clicks even though downstream metrics such as checkouts are affected primarily by a different ranker.
- Does not handle dilution: As mentioned before, most of the data in search and ranking has no metric activity. The user effectively contributes a zero to all treatments. Including ties makes interleaving setups less sensitive.
Overall, we went with an approach that favors direct attribution. We track metrics associated with user behavior at the most granular level - the individual item level. Figure 6 below showcases how we collect data and aggregate it before running a paired t-test. Note that the whole process is handled automatically in our system; users don't have to write any complex pipelines for generic use cases and an analysis can be set up in less than two minutes.

Removing dilutive exposures poses a challenge by making it difficult to draw cross-experiment comparisons for a given metric. We solve this problem, however, by translating the localized impact to global impact, assuming that both control and treatment units get the new treatment ranker. Figure 7 below highlights how localized and global impact estimates are presented to our users. A user can then use the global impact metric to better understand if their treatment will meaningfully move the needle.

Interleaving challenges
Interleaving designs are not a free lunch for improving experiment sensitivity. Overall, interleaving experiments generate more complexity and come with generalizability issues. In the following, we outline some of the challenges and our recommendations for how to address them.
Measuring performance differences
In setting up an interleaved experiment, we need to generate the interleaved lists prior to randomization, which generally means making calls to two ranking algorithms. Even if the calls are made asynchronously or done through lazy evaluation, the latency impact on the system can be substantial enough that the interleaving setup will fail to capture a degradation. Consider this scenario:
- Ranker A shows less accurate results, but has very good latency and does not disrupt the user experience.
- Ranker B shows more relevant results, but is 40% slower than ranker A and could disrupt the user experience.
During initial testing of the two rankers in an interleaved setup, it may seem that ranker B outperforms A in terms of relevance and user satisfaction based on metrics such as click-through and conversion rates. This conclusion would be misleading. Interleaved metrics might not capture ranker B's latency and subsequent performance degradation, offsetting the impact of ranker B's more relevant results.
Recommendation
Fortunately there is a very simple solution to this problem. As shown in Figure 8 below, you can analyze interleaved traffic against reserved traffic in the context of an A/B experiment by specifically targeting app performance metrics. Specifically, divide the traffic into interleaved and reserved; because the traffic allocation is random, you can run a regular A/B test. If the resulting metrics indicate that the interleaved traffic has caused substantial app performance degradation, you can then follow up to optimize the ranking system's reliability. Note that this solution is free because we generally recommend that users perform an A/B test in parallel with an interleaved experiment.

External validity and interference effects
Interleaving experiments can suffer from issues related to external validity. In practice, users typically interact with a single ranker at a time rather than a blend of multiple rankers. Depending on circumstances, this means that the interleaving setup might not generalize to actual user behavior outside of the testing phase. Moreover, by exposing a user to multiple alternatives, we forgo our ability to measure long-term effects; we can only measure what users prefer at that moment when they can compare and contrast multiple list items.
To best illustrate why external validity is important, consider the hypothetical job offer example shown in Figure 9 below. If you're asked to select a salary - either $50,000 or $100,000 per year - you likely will behave rationally and choose the higher amount. But if you're given only one choice - $50,000 - without the ability to compare and contrast, the likelihood of you accepting that offer will be higher than zero. In other words, if users are offered only one choice, they might take it simply because there is no alternative. This highlights that interleaving designs can effectively amplify user preferences even when A/B testing might lead to a flat effect.

Recommendation
For teams just starting to run interleaved experiments, we recommend running a two-phased approach to build empirical evidence for the link between interleaved and A/B test results. Note that the two phases can run in parallel. The ultimate goal is to understand if the interleaved setup generates a similarly consistent set of conclusions as an A/B experiment. If after a dozen experiments the relationship between interleaved metrics and A/B metrics is strong, you can rely more often on an interleaved setup alone to make ship decisions.
Keeping up the pace
Another challenge with interleaved designs is that they provide such drastic sensitivity improvements that a team may not yet have built a process to take advantage of the improved velocity. Consider what the process might look like before and after adopting interleaving, as shown in Figure 10:
- Before interleaving: Teams typically ran experiments for two to six weeks. The focus was primarily on significant model changes likely to yield clear results, which lead to emphasizing zero-to-one work rather than incremental improvements such as removing features or testing refactoring work. Experiment decisions were made during weekly review meetings where new experiments were discussed and planned. Changes were tested on a large proportion of traffic - more than half. This increased the risk of exposing a significant number of users to potentially suboptimal model variants for extended periods.
- After interleaving: The time required to reach conclusive results shrank from weeks to hours. The decision-making process has been automated and now focuses on minimizing downside risk. When metrics degrade, engineers can roll back changes quickly without waiting for the next review meeting. Successful experiments are promoted promptly to A/B testing to assess long-term impact. Decision-making becomes decentralized, allowing individual team members to initiate experiments within specified guardrails. The exposure blast radius to suboptimal variants is minimized to less than one to two percent of traffic; the ability to measure the impact of changes efficiently frees teams to dedicate more effort to incremental improvements.

To get the highest possible leverage from interleaving, you need to optimize other parts of the process. Although methodological advancements play a key role in driving experimentation velocity, it's also important to reflect on the role of process and culture. If teams are not structured to operate with extreme levels of ownership, a clear guardrails process, and minimal red tape, increased levels of sensitivity may not help drive faster and better product iteration. In the next section, we detail how teams can improve their capacity to run more experiments to keep up with the improvements inherent in interleaving.
Recommendation: Reduce ramp, collection, and decision times
First, we recommend that teams track a narrow set of industry metrics that provide a good signal about ranker success. It is common for search and ranking experiments to have dozens of metrics that examine the impact of a change from multiple points of view. It is important, however, to keep the cognitive load low, allowing engineers to focus on only two or three metrics that have clear tradeoffs. Our recommendations include:
| Metric | Description | Why? |
| Click rate | Measures the number of clicks a user makes to different items, weighted by number of exposures. | Rankers with higher clicks can indicate that users are more engaged with the content. |
| Checkout conversion | Measures the number of checkout events weighted by number of exposures. If a user was exposed to an item, did they convert that item to a purchase? | Rankers should ultimately move meaningful business metrics rather than only generating clicks. Checkout conversion is a clear metric. |
| Gross order value (GOV) | Measures the subtotal of the item's order value, weighted by number of exposures. Is the user generating higher value orders thus driving higher revenue? | Rankers should try to maximize the overall order value, not just the likelihood that a user will checkout. |
With these three metrics, users can then follow the decision-making framework below:
| Scenarios | Decision |
| Clicks ? Conversion ? GOV ? | Ship as an A/B because the treatment ranker drives all metrics in a positive direction. |
| Clicks ? Conversion ? GOV ? | Ship as an A/B. Although treatment ranker drives fewer clicks, it ultimately impacts highly relevant topline metrics like conversions and GOV. Fewer clicks simply means that the ranker drives more meaningful clicks. |
| Conversion ? GOV ? or Conversion ? GOV ? | Ranker drives more orders, but of smaller size, or fewer orders, but with larger size. Encode the tradeoff to maximize overall GOV. |
| Remaining scenarios | All other scenarios require the team to continue iterating because the impact is negative or flat; you may be driving clicks without increasing GOV or conversion. |
By focusing on these metrics and decision-making framework, you can heavily reduce the durations involved in ramping, collecting, and - most importantly - deciding on next steps. This keeps the team's cognitive burden for decisions low.
Recommendation: Reduce development times
While new work will always demand the most effort, the increased sensitivity of interleaving designs allows for testing changes that were previously impractical. Here are some examples of what interleaving makes possible:
- Pruning features: With interleaving, we can quickly and accurately determine the impact of removing certain features from ranking algorithms. For example, if there are features that are brittle and hard to maintain, we can test their removal to see if they are truly necessary for maintaining ranking quality. This could lead to a leaner, more maintainable codebase without compromising performance.
- Micro-optimizations: Interleaving allows us to test small, incremental changes that might have been too subtle to measure accurately with traditional A/B tests. This includes tweaks to ranking weights, minor adjustments in algorithm parameters, or slight changes in feature calculations. These micro-optimizations can accumulate to significant improvements in the overall user experience.
- Operator adjustments: It is rare for ranking results to be used as-is. In practice, some results are boosted by operators outside of the ranking loop. Unfortunately, those changes are rarely vetted and tested. With interleaving, operators can have better visibility into whether their adjustments are effective.
- Handling edge cases: It is difficult to optimize a system against uncommon query types or edge cases when building ranking models. With interleaving, it becomes easier to measure incremental improvements from optimizing the tail in search results.
In summary, interleaving unlocks the potential to test a broader range of features iteratively and with greater precision.
Recommendation: Set guardrails
Because experimenters are given greater leverage and ownership over interleaving, proper guardrails must be in place to prevent mistakes and discourage behavior not aligned with user interests. Our recommendations include:
- Cap the traffic at 2% to 5%: Enforce a strict cap on the traffic allocation for any given interleaving experiment. Use monitoring tools to ensure compliance and automatically alert or halt experiments that exceed this limit. Given the highly sensitive nature of interleaving designs, there should be no reason to increase the blast radius beyond 5%.
- Increase transparency: Ensure that all of a team's experimental changes are done so that team members and managers can get a bird's-eye view of everything. Dashboards that collocate all actively running experiments and draw a heatmap from metric movements can quickly highlight any required actions. We also recommend creating a shared communication channel for alerts.
- Automated rollbacks: Establish and enforce automated rollbacks that stop the experiment when appropriate. The scenarios outlined in metric tradeoffs can be fully encoded to automate this decision-making process.
- Review only A/B promotions: Devote primary focus on reviewing decisions to promote to the A/B phase rather than reviewing interleaving experiments.
Recommendation: Stack your wins before moving to A/B phase
To increase velocity, don't immediately promote any winning ranker candidate from an interleaving experiment to an A/B setup. Because interleaving designs offer more than a 100-fold increase in sensitivity, an A/B experiment might not be powerful enough to capture a change. Instead, we recommend that engineers continuously iterate within an interleaving setup and only move a ranker to A/B after they have stacked sufficient improvements.

Conclusion
Interleaving can be a game changer in achieving heightened experiment sensitivity. By significantly boosting the sensitivity of experiments, it allows detection of meaningful changes much more quickly and accurately than in traditional A/B testing. More importantly, it allows testing within a much smaller blast radius, keeping the majority of traffic safe from being exposed to poor-quality ideas.
Interleaving's success hinges on its ability to reduce noise and increase signal through within-subject variance control and to handle dilution from noncompetitive pairs and non-engagement. These advantages make interleaving an essential tool for our teams, enabling them to make data-driven decisions rapidly and with greater confidence. Nonetheless, to harness the full potential of interleaving, it's crucial to establish robust guardrails and change the culture and process of experimentation. Teams with suboptimal experimentation workflows ultimately won't be able to leverage interleaving effectively.
Overall, we're excited to have built a platform that supports interleaving and makes the configuration and analyses of these setups easy to perform.
Acknowledgements
Thank you to Jay Zhang from the Homepage team and Muxi Xu from New Verticals team for partnering with us in configuring and testing interleaving setups. Thank you to Janice Hou for helping us define event sources used in metric computation. Thanks also to Yixin Tang and Qiyun Pan for their help extending the delta method to support paired t-tests and to Jun Jin and Qilin Qi for pushing for interleaving work to be prioritized. Thank you also to Sagar Akella for valuable feedback on this blogpost.

