
Managing inventory levels is one of the biggest challenges for any convenience and grocery retailer on DoorDash. Maintaining accurate inventory levels in a timely manner becomes especially challenging when there are many constantly moving variables that may be changing on-hand inventory count. Situations that may affect inventory levels include, but are not limited to:
- Items expiring
- Items may have to be removed due to damage
- The items vendors sent are different than than what was ordered
After an inventory update is made to the database, failure to reflect accurate inventory levels in different parts of the system in real time can result in under buying and over selling, which both lead to negative customer experiences and hurt business. Over-selling is when customers order items from the platform, and therefore listed as in stock, that are actually out of stock. Then, the merchant may be forced to refund or substitute the item, resulting in a subpar customer experience. Another issue is under buying, where inventory that has been replenished has not been updated on the platform. Under buying gives customers less selection, even if the items are available, and costs the business in potential sales that were lost.
DashMart, DoorDash’s first-party convenience and grocery offering, is no exception to this challenge. While building out DashMart’s internal inventory management system to help DashMart associates manage inventory, the DashMart engineering team came to realize that since the inventory tables were so core and foundational to different operational use cases in a DashMart, some actions or code must be triggered every time the inventory level changes. Achieving this task in a clean, fault-tolerant way is non-trivial due to all the complex ways inventory levels can change.
Stay Informed with Weekly Updates
Subscribe to our Engineering blog to get regular updates on all the coolest projects our team is working on
Please enter a valid email address.
Thank you for Subscribing!
The solution to real-time processing of inventory changes
The simplest approach to propagating inventory level changes in the database to the rest of the system may have been to invoke the service code to take actions every time something that affects the inventory table is called. However, this approach is difficult to maintain and error-prone, as there are many different code paths that affect inventory levels. Additionally, it couples the action of changing the inventory with the reaction to inventory changes.
Instead, since the inventory levels are stored in specific CockroachDB tables, we decided to leverage CockroachDB’s change feed to send data changes to Kafka, which then starts Cadence workflows to accomplish whatever task needs to be done. This approach is fault-tolerant, near real-time, horizontally scalable, and more maintainable for the engineers as there are clear separations of concerns and layers of abstraction.
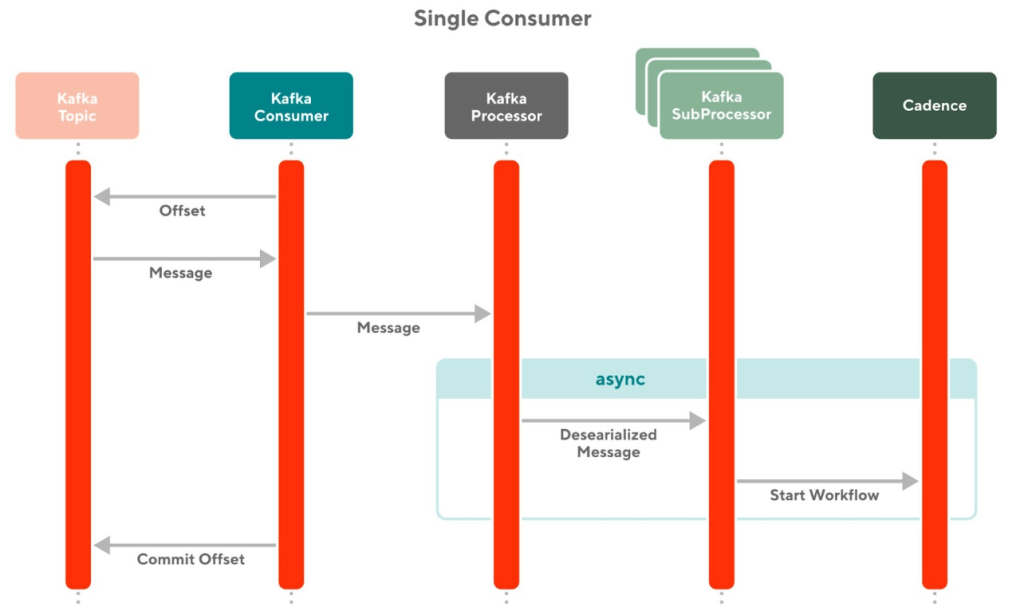
More specifically, the high-level solution of utilizing changefeed is as follows (Figure 1):
- Create separate Kafka topics that consume data changes from the inventory tables
- Configure the changefeeds on the inventory tables to publish to those Kafka topics from the previous step
- Start Cadence workflows to trigger different workflows based on the data changes

As illustrated in the diagram above, multiple tables can be configured with changefeeds to send messages to Kafka. We currently have two inventory tables with slightly different business needs. We have set up one Kafka consumer per table (more details on how the consumer is set up below). Consumers can choose which Cadence workflow they want to start. Note that the consumers do not have to start any Cadence workflows: they can choose to ignore the Kafka message, or do something else completely (e.g. interact with the database). For our use cases, we wrapped everything in Cadence to take advantage of Cadence's fault-tolerance, logging, and retry capabilities.
We wrote a general Kafka processor and abstract stream processing Cadence workflow to process the inventory updates from the CockroachDB changefeed. The general Kafka processor provides a simple three-method interface for client code to implement sub processors that can kick off different Cadence workflows. The framework also handles errors, logging, and duplicate stale updates while leaving the behavior configurable through the sub processors and concrete Cadence workflow implementations.
The abstract stream processing Cadence workflow is implemented as multiple long-running workflows that process messages through an input queue. The queue is populated through Cadence signals using the SignalWithStart API. We have also implemented functionality to easily batch process messages from the queue if the client implementation desires. Once the long-running Cadence workflow runs through to the client-specified duration time, the workflow will either complete or start a new workflow depending on whether there are more messages that still need to be processed.
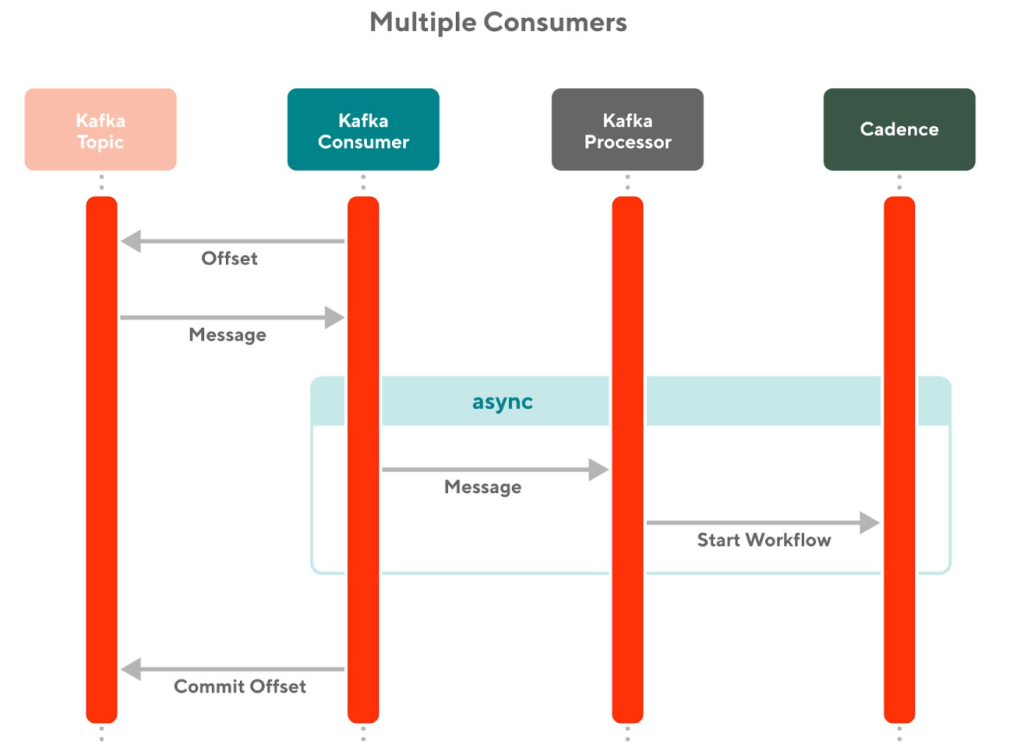
An alternative design where each Kafka topic has multiple consumers was also considered. Each consumer would handle different tasks instead of having one consumer that has many different subprocessors that handle different tasks. However, DoorDash's internal server framework for Kafka consumers only allows one consumer per Kafka topic. This limitation provided a strong incentive for us to use one consumer and multiple sub processors in order to avoid having to write custom Kafka consumer logic.
Building for requirement extensibility and code maintainability
As mentioned, today DashMart writes to two separate tables for inventory levels for different business needs. Initially, there was a business requirement where we only wanted one table to kick off a certain Cadence workflow, and did not want the other table to kick off that Cadence workflow. Business requirements changed later, and we decided that we wanted the other table to kick off the Cadence workflow as well. The layers of abstraction in the framework made it very easy to add that new functionality: simply add the existing Kafka subprocessor to the existing processor. Enabling the functionality was as simple as a one-line code change.
If new functionality needs to be added, a new Cadence workflow and subprocessor would need to be written, then the subprocessor needs to be added to the existing processor, providing clear abstraction and separations of concern. Again, engineers adding new functionality would not need to worry about duplicate Kafka messages, logging, retries, etc. since that is all handled by the framework code. This setup enables engineers to focus on the business logic, and worry less about resiliency, failure modes, logging, alerting, and recovery.
Additionally, inventory table schema evolution was also considered in this design. The CockroachDB changefeed exports JSON, so any schema changes would be included in the JSON. As long as the data deserialization is written in a backwards-compatible way (e.g. do not fail deserialization on unknown properties, make columns that are to be deleted nullable), schema evolution can happen seamlessly and without any breaking deployments.
Ensuring durability and recovery with Cadence
We use Cadence to handle retries. In the event of failed Cadence workflows or even failed Kafka event consumption, it is easy to recover from the failures. We recently experienced some failed Cadence workflows due to a connection leak from other unrelated features. Thanks to the way everything was abstracted, we simply updated the “last updated” column for the affected rows in the inventory tables, which automatically sent updates to Kafka and started new workflows for the failed Cadence workflows.
An additional layer of protection can be added with a dead-letter queue for Kafka messages that fail to be processed. The dead-letter queue would allow us to debug failed message consumption more easily and replay only the failed messages that make it to the dead-letter queue. This additional capability has not yet been implemented since we have not seen many failures, but is something on the roadmap for engineering excellence.
Utilizing Kafka Pods for better scalability
We have a number of Kafka pods running the Kafka consumers that are consuming messages from the Kafka topics. We have separate Cadence pods running the Cadence workflows. We have tried sending thousands of simultaneous database updates to the existing Kafka pods at once, and the resulting Cadence workflows have all completed without issues. We can scale up the Kafka and Cadence pods if our system health metrics indicate that we need more resources to process the growing number of updates.
Conclusion
With CockroachDB's change feed feature, DashMart has built a scalable and durable system that can react to database updates in real time. Adding Kafka adds an additional layer of resiliency for moving data from one system to another. Using Cadence further provides robustness and easy access to successes and failures through a user interface. Creating a general framework for the Kafka and Cadence portions makes the system easily extensible, as adding new functionality involves only writing the core business logic that needs to be updated, saving the developer the time and effort for thinking about how to move the data around in a fast and durable way.

