

DoorDash’s struggles in understanding its catalog
We currently have over tens of millions of items in the DoorDash catalog, and tens of thousands of new items are added every day, most of which are unlike any other item we have seen before. For example, just consider a list of desserts which contains hundreds of different varieties. When you consider that our catalog contains only a small fraction of these the scale of the problem is clear . But multiple parts of DoorDash’s business need to be able to understand item characteristics at this level of detail. Merchandising and product teams want to be able to create curated editorial experiences like “best breakfast options near you” or “game night finger foods.” Strategy teams may want to know if we have enough “healthy” food options available in a market. Or, if a customer searches for “pad thai” but there are no nearby options, we might want to understand which Thai dishes with similar characteristics we can suggest instead. We can build specialized models for each of these tasks mentioned above, but that can be too time-consuming to quickly test new ideas.Why we decided to use ML-generated tags
One potential generic solution is to use embeddings that are fine-tuned to our menus, but embedding quality is difficult to evaluate, especially across hundreds of classes. They are also not especially intuitive for business users who just want to quickly explore the menu catalog. Another alternative is to categorize items by human-interpretable tags and build models to classify items, but this approach faces the cold start problem where we don’t have enough labeled data to support the 300-plus categories that our teams are interested in. If we try to depend on manual human labeling for these rare classes, we would need to re-label the entire catalog as users ask for new classes, which is expensive and slow. Even naively trying to have annotators label enough sample data to train a model would require millions of samples for tags that have a low base rate of occurrence. As DoorDash’s business grows and we offer more specialized selections, these rarer tags become even more important, allowing us to present more granular categories of items like “Shanghainese” and “Sichuan” instead of treating them as just “Chinese.” We decided to approach these cold start and scaling problems by developing a taxonomy of all the tags we were interested in and then building models to automatically tag every item in our catalog according to this taxonomy. We integrated these models into a human-in-the-loop system, allowing us to collect data efficiently and substantially reduce annotation costs. Our final implementation was a system that grows our taxonomy as we add tags and uses our understanding of the hierarchical relationships between tags to efficiently and quickly learn new classes.What are the characteristics of a good tagging solution?
Our solution needs to fulfill a few requirements to be useful:- Correctness: We need to ensure items are not incorrectly tagged in order to maintain high precision.
- Completeness: We want to make sure items have all appropriate tags and maintain high recall.
- Scalability: Merchandising teams regularly want to add new tags, and we need to be able to quickly re-tag our existing catalog.
- Flexibility: We need the ability to add and modify the organization of these tags.
Using a human-in-the-loop-flow for tagging
Ultimately, we need to establish ground truth for our labels, so we hired human annotators to help us do this. To control costs, we want to work efficiently by only labeling samples that help the model explore the decision space. With the following approach, we can meet the requirements described above and still be sample-efficient:- By first developing a taxonomy, we can significantly reduce the number of tag sets we need annotated for each item.
- We then design a task that is efficient for human annotators to complete with high precision and recall.
- We integrate this data into a model that generates new samples for annotation, completing our human-in-the-loop flow.
Best practices in designing a taxonomy
A well-designed taxonomy serves as the foundation effectively tagging the items in our catalog. We want this taxonomy to be comprehensive but flexible enough to cover the broad range of items we currently have, and those we will encounter in the future. 1) Try to keep tags from overlapping By guaranteeing tags are mutually exclusive, we can ensure that annotators don’t need to work through a list of hundreds of tags. By focusing on only relevant parts of the taxonomy, annotators can be more efficient and accurate.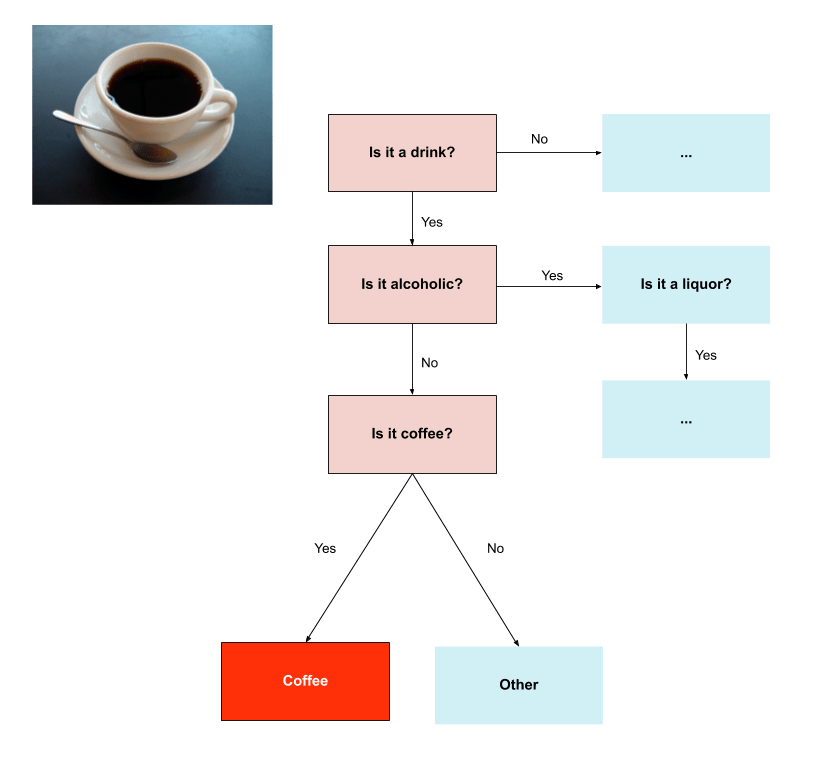
Designing a high-throughput, high-precision task for annotators
Since we need to use human annotators to provide the initial labels for our dataset, we will need to manage the key metrics below to ensure the dataset is of a sufficiently high quality and is representative enough to be used for model training and validation:- Annotation precision: We want to ensure annotators don’t incorrectly label the samples we provide them.
- Annotation recall: We want to ensure annotators generate all relevant labels for the samples we provide them.
- Sampling representativeness: Part of the annotated data will be used to generate model training data. If the samples annotators label as positive aren’t representative of the true diversity of a class, then our model recall will be low (regardless of annotation precision and recall). For example, if annotators are labeling burgers, but we don’t provide examples of “Whoppers,” then our model would never be able to train on “Whoppers.” Worse, if we don’t have any validation data that contains “Whoppers,” we wouldn’t even be aware of this model blind spot until the model runs in production.
 We also have finer control over the tradeoffs we need to make between annotation costs, speed, and quality. For example, we can use Amazon Mechanical Turk, a crowdsourcing marketplace, which is very inexpensive and fast but has lower annotation precision for simple questions (e.g. is this item vegan) requiring less background knowledge to answer. For more complex questions, we can use more experienced but slower annotators specializing in nutrition information (about 10 times the price of Mechanical Turk annotations) to decide if an item is healthy.
We also have finer control over the tradeoffs we need to make between annotation costs, speed, and quality. For example, we can use Amazon Mechanical Turk, a crowdsourcing marketplace, which is very inexpensive and fast but has lower annotation precision for simple questions (e.g. is this item vegan) requiring less background knowledge to answer. For more complex questions, we can use more experienced but slower annotators specializing in nutrition information (about 10 times the price of Mechanical Turk annotations) to decide if an item is healthy.
Building scalable models
Our models need to have a few key characteristics in order to work for a growing taxonomy and fit into our subsequent active learning pipeline.The flexibility to accommodate a growing taxonomy
As our taxonomy grows, we do not want to be training models independently for each tag. Apart from being difficult to maintain in production, training a separate model for each tag is extremely sample-intensive and expensive. Instead, we use our taxonomy to train our model in a sample-efficient manner. For our first iteration, we trained multiple models on each mutually exclusive category in a hierarchical fashion. Each model (one per attribute group) was a simple 1-layer LSTM model with FastText word embeddings. However, there is a risk here of not preserving correlations between attribute groups (e.g. burgers are rarely vegan) so we also maintain a set of hard-coded rules to deal with some of these edge cases. As our taxonomy gets more complex and we collect more labeled samples, we’re condensing the models into a multi-task objective architecture, allowing us to learn tags for multiple attributes simultaneously, which helps preserve correlations between tags.Generate calibrated, representative predictions
While we don’t need calibrated probabilities to generate tags, we do need them to be calibrated in order to select new samples for annotation. Essentially, our strategy will be to use these model predictions to select samples with high uncertainty. To ensure our probabilities are well-calibrated, we preserve the naturally occurring class balance during training. Given our biased process for selecting new samples for annotation, we will also need to supplement our training data to maintain class balances. In particular, we chose a self-training strategy by training a simple model with high precision to generate supplemental samples for training.Setting up a human-in-the-loop
Now that we have a taxonomy, clear task design, and a strategy for building a model, we can put these together into a human-in-the-loop flow: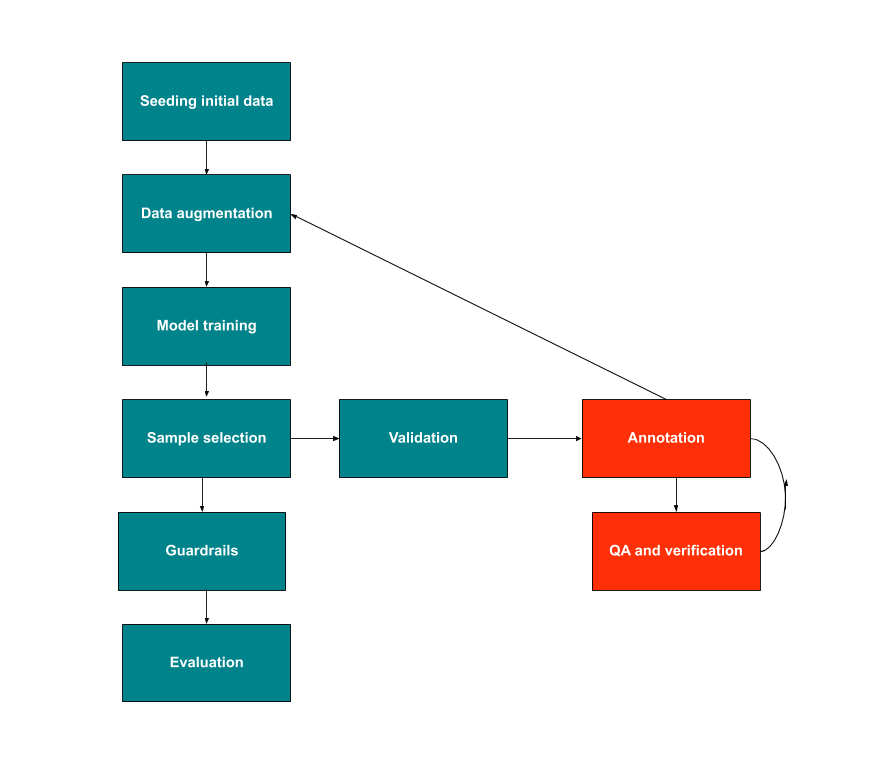
Seeding the initial data
We first need to have a source of seed data to generate samples for annotation. While we actually used a simple classifier to select samples before sending them to annotators (since we could confidently generate enough high-precision samples by selecting a suitably high probability threshold), if we had a higher budget or lower turnaround times, we could also just directly send these to annotators to label. For our use case, we trained semantic embeddings in an unsupervised manner to use as the baseline for our sample selection. In our application, these were especially helpful in generating ambiguous samples like “pepperoni,” which in a menu context would be understood to likely be a pizza and not just the meat topping.Data augmentation
Earlier, we described our self-training strategy to generate new training samples and maintain class balances. We also supplemented our training data with a mix of nearby samples in terms of edit distance and embedding cosine similarity as well as random text augmentation (randomly varying the sentence ordering in a description or removing information like a menu category). In practice this data augmentation also simulates the variation in menus where merchants sometimes don’t have detailed descriptions or menu categories. For some very simple cases, using some rule-based heuristics was highly effective (all items with “sushi” in the name are probably sushi). However, these heuristics generated datasets with a large number of samples that focused on particular keywords. Training models on these biased datasets, ,led to issues where the model essentially overfit on the keywords and missed edge cases (incorrectly tagging “non-alcoholic beer” as alcohol). In these situations, using the sample along with a description, if available, while removing the keyword, was an effective way to use the data without overfitting.Model training
Since we have a combination of item names, menu categories, and full-text descriptions available, LSTMs with pre-trained FastText embeddings was the obvious approach. However, due to the sample intensive nature of these models, we were dependent on good data augmentation (we had a ratio of 100:1 for synthetic:labeled samples) for accurate training, requiring us to adjust sample selection in order to maintain class balances. Our data augmentation methods couldn’t preserve correlations between tags as easily. So as described earlier, we initially needed to train a single task (multi-class) LSTMs on each set of exclusive tags. We found that multi-task models initially underperformed, since our sampling didn’t preserve the natural tag distribution and we had too few samples to only train on labeled data. However, as we collected more annotations multi-task methods became more effective.Selecting annotation samples
We selected samples for annotation with a view towards improving either precision or recall:- To improve precision we selected samples similar to those where the model prediction conflicted with the annotator label.
- To improve recall, we first used the model to label new samples from our unlabeled dataset. We then selected samples that the model had low confidence in (predictions close to the decision boundary) for annotation.
Validation
Crucially, this sample selection strategy is biased, meaning we couldn’t evaluate model precision or recall on these samples. We needed an unbiased validation set to be able to understand model blindspots, so to solve this we also separately annotated a dataset selected uniformly at random.Annotation
The actual annotation process involved working with multiple vendors (an operational component that is still evolving). We used a mix of professional annotators as well as Mechanical Turk. The actual task designs were extremely similar, but we got a first pass from Mechanical Turk in order to focus on sending the professional annotators more ambiguous cases. To get better throughput, we also varied the amount of consensus required by tag, so we only required higher consensus from tags with lower cross-rater-agreement.Verification
We also needed to understand our annotation quality to be able to improve this process and improve sample efficiency. Our initial (primary) metric for annotation quality for a tag was cross-rater-agreement, but this would fail if a set of annotators was systematically biased. We use the following heuristic to address the potential systematic bias:- verified annotation agreement between different vendors
- used annotated samples to bootstrap a small set of “golden data.” These were samples we were extremely confident were accurately labeled, so as we onboarded new annotators we would mix in golden data to understand baseline annotator accuracy.
Guardrails
In spite of all our sampling some terms were still too rare for us to select with high probability. In particular, we found this to be the case with brand names. For example, while Kirin Ichiban is a beer and should be tagged alcohol, there are very few merchants on the platform selling this item, and the words are too infrequent for the model to learn from the rest of the data. To handle this issue without depending on more sample generation, and especially in some sensitive contexts (e.g. age-restricted items) we set some hard-coded rules before making these tags available to consumers.Evaluation
Since this project feeds into multiple downstream applications, our target performance metric was the macro-F1 score. Using this metric lets us ensure that the model is accurate even on tags that have very low base rates. We also manually check the impact on our search results for some of the most frequently used tags in key markets to check that the tags and annotations are relevant.How much does this process improve tag quality?
Through this approach we’ve been able to almost double recall while maintaining precision for some of our rarest tags, leading directly to substantially improved customer’s selection. Below is an example of the difference between the old tags (where only items labeled “dessert” were returned) and the new tags, where a query for “desserts” can be expanded by a query-understanding algorithm that walks down the taxonomy. Figure 3: Adding additional tags improves product discovery since user search is expanded beyond simple string matching.
As opposed to the initial query which only indexes items with the keyword “dessert,” we were able to select far more items we actually considered to be desserts without modifying the search algorithm.
We’re also able to power use cases such as screening for restricted items (21-plus or alcohol) relatively easily. Below is a sample of items our model recognizes as alcohol:
Figure 3: Adding additional tags improves product discovery since user search is expanded beyond simple string matching.
As opposed to the initial query which only indexes items with the keyword “dessert,” we were able to select far more items we actually considered to be desserts without modifying the search algorithm.
We’re also able to power use cases such as screening for restricted items (21-plus or alcohol) relatively easily. Below is a sample of items our model recognizes as alcohol:
 Given the sensitivity of this application we have multiple further guardrails and rules, but having good tags significantly improves baseline accuracy, reducing the complexity of the rules we need to maintain.
We can also use these tags in other contexts (merchandising, curation) to develop minimum viable products immediately. Launching a merchandising solution for “best desserts near you” becomes a matter of a simple query instead of a bespoke machine learning project.
Given the sensitivity of this application we have multiple further guardrails and rules, but having good tags significantly improves baseline accuracy, reducing the complexity of the rules we need to maintain.
We can also use these tags in other contexts (merchandising, curation) to develop minimum viable products immediately. Launching a merchandising solution for “best desserts near you” becomes a matter of a simple query instead of a bespoke machine learning project.