

In 2020, DoorDash engineers extracted the consumer order checkout flow out of our monolithic service and reimplemented it in a new Kotlin microservice service. This effort, part of our migration from a monolithic codebase to a microservices architecture, increases our platform’s performance, reliability, and scalability.
The consumer checkout flow is one of the most critical flows on the DoorDash food ordering platform. The flow is responsible for submitting consumers’ order carts, processing payments, and connecting the order to our logistics system. Our legacy consumer checkout flow was built in 2016 in our monolithic service.
To improve the system, we re-engineered the consumer checkout flow. The new consumer checkout flow is implemented in a Kotlin microservice and utilizes a newer tech stack based on technologies such as Apache Cassandra, Apache Kafka, Cadence, and gRPC.
The new architecture has proven its reliability and scalability allowing DoorDash to ensure a smooth ordering experience to more and more users.
Our motivation for building a new checkout flow
The migration to a microservices architecture gave us the opportunity to improve our new flow, including getting better:
- Performance: Faster consumer checkout
- Scalability: Being able to process more orders concurrently
- Reliability: Avoiding orders getting lost or stuck in the middle of processing
- Development productivity: Adding features to the flow more quickly and efficiently
Performance
Our legacy checkout flow was not performant and was frequently criticized by users. The legacy consumer checkout flow was written in Python. Tasks in the flow were executed sequentially and there was no parallelism between tasks. In addition, the database access pattern consisted of performing reads and writes without caching results. This degraded performance since each query usually would take 10 to 100 milliseconds to execute.
Scalability
The database was preventing the scalability of our legacy checkout flow. The order data was stored in a Postgres database that lacked any sharding mechanism. Though there were read replicas to offload the read load, database writes were always forwarded to the single primary database, which cannot be easily scaled horizontally. This issue was amplified further when the legacy consumer checkout flow updated the database too frequently.
Reliability
There were some reliability issues in the legacy checkout flow where an order could be lost during the order processing. The consumer checkout flow contains many steps. Ideally, those steps should run in a transaction to ensure either all of these steps or none are executed, so there are no orphaned parts of the process.
For example, if a customer’s order fails to create a new delivery in our logistics systems then we won't be able to assign a Dasher, our name for delivery drivers. A failure like this should cause the whole consumer checkout to fail and every operation we have already completed in the process would need to be reversed. In this case, we would need to refund the consumer the amount that was charged, because their order failed.
Unfortunately, the legacy consumer checkout flow didn’t handle the failure process properly. If the order fails in the middle of the process, the order is left in limbo and usually needs some human intervention to fix it. This type of manual intervention is not scalable or efficient.
Iteration velocity
We also wanted to improve the development velocity of the consumer checkout flow so that we can iterate faster.
DoorDash built its legacy platform with a monolithic codebase, where the legacy consumer checkout lived. This codebase helped DoorDash move fast in its early stages. But as the codebase and our business grew, more issues emerged:
Slow deployments: Deployments were only operated by the site reliability engineering (SRE) team. This meant individual teams didn’t have the flexibility to deploy their changes. The deployment process took quite a bit of effort and time since it impacted everything in the monolithic codebase. If there was a failure, the whole release would need to be rolled back, which would delay engineers working on other features by at least one day.
Lack of ownership: Many legacy features and business logics were implemented many years ago. Components in the monolithic codebase sometimes don’t have a clear ownership. Many flows were lacking documentation and were not well monitored. Not having clear ownership and knowledge of the system had negative consequences. Some flows were disrupted by accident when new features were added to the consumer checkout flow. These issues were hard to detect. Sometimes we only discovered them when consumers reported issues or our core business metrics were degraded.
Inefficient testing: The monolithic codebase lacked an efficient way to test code changes because the unit tests run on the staging environment instead of the production environment.
These issues made the iteration speed really slow. Sometimes making a tiny change in production could take a week or longer.
Checkout process architecture
Given the issues we mentioned above, we decided to rewrite the checkout flow using a new tech stack.
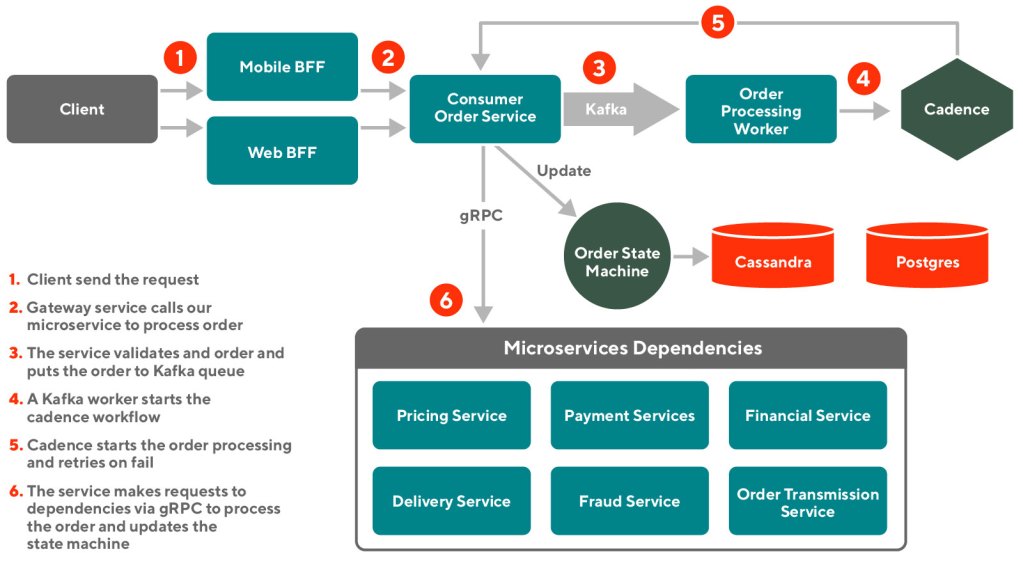
The lifecycle of the new consumer checkout flow is the following:
- The clients (web/mobile) send requests to our gateway microservice to checkout an order.
- The gateway microservice calls the newly built order service.
- The order service fetches data associated with the order and validates the item, merchant, and delivery availability. Then it materializes the order into a Cassandra database and drops off a Kafka message in the queue, indicating the order has been submitted.
- The Kafka consumers poll order submission events and create a Cadence workflow to initialize the order processing.
- Cadence calls an order service endpoint to start the order processing.
- The consumer order service starts its state machine to process the order. In each state machine step, such as performing a payment or creating a delivery within our logistics systems, the consumer order service interacts with a related microservice using gRPC and updates the order we stored in the Cassandra database.
- The client checks the order processing state using a pull model. The client polls an endpoint on the order service, which looks up the order state in the Cassandra table and returns a success if the order processing has finished all of the state machine’s steps. If the order processing fails, Cadence retries it.
The technologies we used to ensure reliability
We want to avoid losing orders or leaving them in a limbo state during the checkout process and we consider this as the most important reliability feature we need to support in the consumer checkout flow. This essentially requires us to be able to:
- Retry and resume the processing on recoverable failures (e.g. when dependencies are temporarily unavailable)
- Cancel the side effects created during processing on non-retryable failures (e.g. when a consumer’s credit card was declined by their bank)
We reviewed the dependencies of order processing and divided them into retryable idempotent steps. Then we designed an order state machine based off of these steps. We persist and update the state machine state into the Cassandra database whenever the state machine finishes an individual step. If the order processing fails, Cadence calls our microservice again to retry the order processing. The order state machine can restore all the order data needed from Cassandra and resume the processing. When the order state machine encounters fatal errors, it cancels side effects to bring the order into a “clean failed state”.
Cassandra: We use Cassandra as our primary data storage to persist order-related data. To maintain backward compatibility, data is also written back to the Postgres database. Cassandra's high availability, scalability, and multiple-AZ replication empower us to scale horizontally. The support of the KV model allows persisting order data in a more efficient and flexible way.
Cadence: We use Cadence for fault-tolerant workflow management. Cadence provides the resilient retry mechanism on order processing failures. The order information won’t be lost when our microservice is down because Cadence will retry once this microservice is healthy again.
State machine: We developed a state machine backed by Cassandra and Cadence. The state machine is resilient to failures and handles errors in an elegant way. The order processing contains many state machine steps, such as fraud check, payments, delivery creation, and sending orders to merchants. If any step fails and the order is unable to submit, we need to revert all the state machine steps completed so far to eliminate any negative side effects. The state machine develops that in sync with the Cassandra state and Cadence retries, providing this state reversal out-of-the-box.
How our new checkout process boosted performance
We improved the performance of the checkout flow by writing concurrent code and caching database results.
Coroutines improve concurrency
In a consumer checkout flow, we need to fetch a lot of data from either multiple databases or other microservices. We did this sequentially in the legacy flow, which was very inefficient. To address this problem, we developed a Kotlin coroutine-based workflow utility to maximize task concurrency. The workflow utility can identify and execute an optimal execution plan given each task's dependency relationship. Such concurrency tripled our performance in executing these tasks.
Caching database results reduces unnecessary queries
The new flow also achieved performance improvements by reducing unnecessary queries. In the legacy flow, database reads and writes were made whenever the flow needed to access the data. In the new flow, we run all of the queries in parallel at the beginning of the flow and cache the data in memory, so that most of the database reads are cut off. In addition, we maintain an in-memory order model and only do one flush into the database at the end of the flow.
Sandbox testing enables faster changes
We also introduced sandbox testing, a mechanism that allows developers to test their changes easily in production environments.
When working with microservices, testing is easier said than done. Microservices usually interact with many databases and other microservices. Local testing cannot replicate the production environment, while testing in production usually requires a service deployment. Neither testing approach is efficient enough for developers to iterate with agility.
To address this issue, we created production sandboxes for our microservices. These sandboxes are a list of special production pods which do not accept regular production traffic. We set up a routing logic in the upstream services of our microservice, based on certain routing rules defined in our configuration files. To test this testing solution we deployed the build to a sandbox and changed the configuration files to route certain requests (usually based on the consumer ID) to the sandbox and test the change. This has improved the development efficiency greatly and ensures that we never deploy a full outage to production for all consumers.
Results
After we launched the new checkout flow, engineers worked with data scientists to analyze the impact of the extraction and found many positive improvements in some of the key business metrics.
Improved latency
We define the checkout flow latency to be the time it takes after the consumer clicks the place order button until they are navigated to the order tracking page. The new flow is faster than the old flow. The average checkout flow p95 latency decreased by 48%, from 13.5 to 7 seconds.
Conversion rate
In the new consumer checkout flow, we display a more friendly error message to consumers. Consumers can take better actions correspondingly to unblock themselves in the checkout process, for example, switching to a different credit card if the first one was declined, or removing an unavailable item from the cart. With the help of this improvement, we’ve observed a significant conversion rate improvement on mobile and on web.
Fewer order cancellations
The legacy flow had no retry mechanism for downstream failures. Any database or downstream service blip could cause order processing to fail and the whole order to be canceled. In the new flow, failures are handled more gracefully with retries and default fallbacks. As a result, around 1% of the orders are saved daily on average.
Database load reduction
The old flow reads from the primary database deliberately throughout the checkout flow to ensure consistency. Some tables were read and updated multiple times in one request. The new flow loads data once into memory and flushes the data into the database at the end of the checkout flow.
As a result, the Postgres database primary reads on order related tables, in queries per second (QPS) were reduced by 96%, while the write QPS was reduced by 44%. The overall database primary QPS reduced was 20%.
Conclusion
To summarize, a Kotlin and gRPC microservice architecture with a tech stack consisting of Cassandra, Kafka, and Cadence can help improve the reliability, performance, and scalability of the checkout flow.
Any company growing out of their monolith and facing similar problems with checkout or similar flows should consider the results shown by our migration.
Photo by Ramiro Mendes on Unsplash