

DoorDash's retail catalog is a centralized dataset of essential product information for all products sold by new verticals merchants - merchants operating a business other than a restaurant, such as a grocery, a convenience store, or a liquor store. Within the retail catalog, each SKU, or stock keeping unit, is represented by a list of product attributes. Figure 1 shows an example SKU and some of its attributes as it is stored in the retail catalog.

Having high-quality, complete, and accurate product attributes for each SKU is a critical part of a first-class shopping experience, providing:
- Better selection & fulfillment - Customers can find an item on DoorDash easily, confident that what they order matches what they want. Dashers, the service's delivery drivers, have comprehensive information to find the correct product in the store.
- Better personalization. Product attributes allow DoorDash to group products based on commonalities, building a product profile for each customer around their affinities to certain attributes. These are the building blocks for providing highly relevant and personalized shopping recommendations.
When a merchant comes onboard at DoorDash, we add their internal SKU data - raw merchant data - to our retail catalog. SKU data from different merchants come in varying formats and quality; they may, for example, have missing or incorrect attribute values. To ensure our catalog's quality does not degrade, we standardize and enrich raw merchant data. Historically, this SKU enrichment of extracting and tagging attributes has been a purely manual process led by contract operators. But outsourcing this task leads to long turnaround times, high costs, and so many inaccuracies that a second human must audit the results generated by the first. As our catalog expands, we seek new approaches driven by machine learning to auto-enrich SKU data.
Extracting attribute-value information from unstructured data is formally known as named-entity recognition; most recent approaches model the extraction task as a token classification. For instance, given the item name "Dove Silk Glow Body Wash 500 ml," a token classifier would tag each entity in the item name as shown in Table 1.

Building an attribute extraction model
Building an in-house attribute extraction/tagging model from scratch requires a significant amount of labeled training data to reach the desired accuracy. This is often known as the cold-start problem of natural language processing, or NLP. Data collection slows model development, delays adding new items to the active catalog, and creates high operator costs.
Using LLMs to circumvent the cold-start problem
Large language models, or LLMs, are deep-learning models trained on vast amounts of data. Examples include OpenAI's GPT-4, Google's Bard, and Meta's Llama. Because of their broad knowledge, LLMs can perform NLP with reasonable accuracy without requiring many, if any, labeled examples. A variety of prompts can be used to instruct LLMs to solve different NLP problems.
We will highlight here how we use LLMs to extract product attributes from unstructured SKU data, allowing us to build a high-quality retail catalog that delivers the best possible experience for users in all new verticals. In the following sections, we describe three projects in which we used LLMs to build ML products for attribute extraction.
Brand extraction
Brand is a critical product attribute used to distinguish one company's products from all others. At DoorDash, a hierarchical knowledge graph defines a brand, including entities such as manufacturer, parent brand, and sub-brand, as shown in Figure 2.

Accurate brand tagging offers a number of downstream benefits, including increasing the reach of sponsored ads and the granularity of product affinity. Because the number of real-world brands is technically infinite, DoorDash's brand taxonomy is never complete. As the product spectrum expands, new brands must be ingested to close any coverage gaps. Previously, brand ingestion was a reactive and purely manual process to fulfill business needs. This limited the volume of new brands that could be added, often failed to address much of the coverage gap, and led to duplicate brands, making it difficult to manage the taxonomy system.
To this end, we built an LLM-powered brand extraction pipeline that can proactively identify new brands at scale, improving both efficiency and accuracy during brand ingestion. Figure 3 shows our end-to-end brand ingestion pipeline, which follows these steps:
- Unstructured product description is passed to our in-house brand classifier
- SKUs that cannot be tagged confidently to one of the existing brands are passed to an LLM for brand extraction
- The extraction output is passed to a second LLM, which retrieves similar brands and example item names from an internal knowledge graph to decide whether the extracted brand is a duplicate entity
- The new brand enters our knowledge graph and the in-house classifier is retrained with the new annotations

Organic product labeling
Consumers care about dietary attributes when building their carts and are more likely to engage with a product if it tailors to their personal preference. Last year, we stood up a model to label all organic grocery products. The end goal was to enable personalized discovery experiences such as showing a Fresh & Organic carousel to a consumer whose past orders showed a strong affinity towards organic products.
The end-to-end pipeline takes a waterfall approach, leveraging existing data where applicable to boost speed, accuracy, and coverage. This process can be broken down roughly into three buckets:
- String matching: We find exact mention of the keyword “organic” in the product title. This approach offered the highest precision and decent coverage, but it missed cases where “organic” is misspelled / dropped or has a slightly different presentation in the data.
- LLM reasoning: We leverage LLMs to determine whether a product is organic based on available product information. This information could come directly from merchants or via optical character recognition extraction from packaging photos. This approach improved coverage by addressing major challenges faced by string matching and has better than human precision.
- LLM agent: LLMs conduct online searches of product information and pipe the search results to another LLM for reasoning. This approach further boosted our coverage.
Figure 4 shows the LLM-powered pipeline for tagging our catalog SKUs with organic labels.
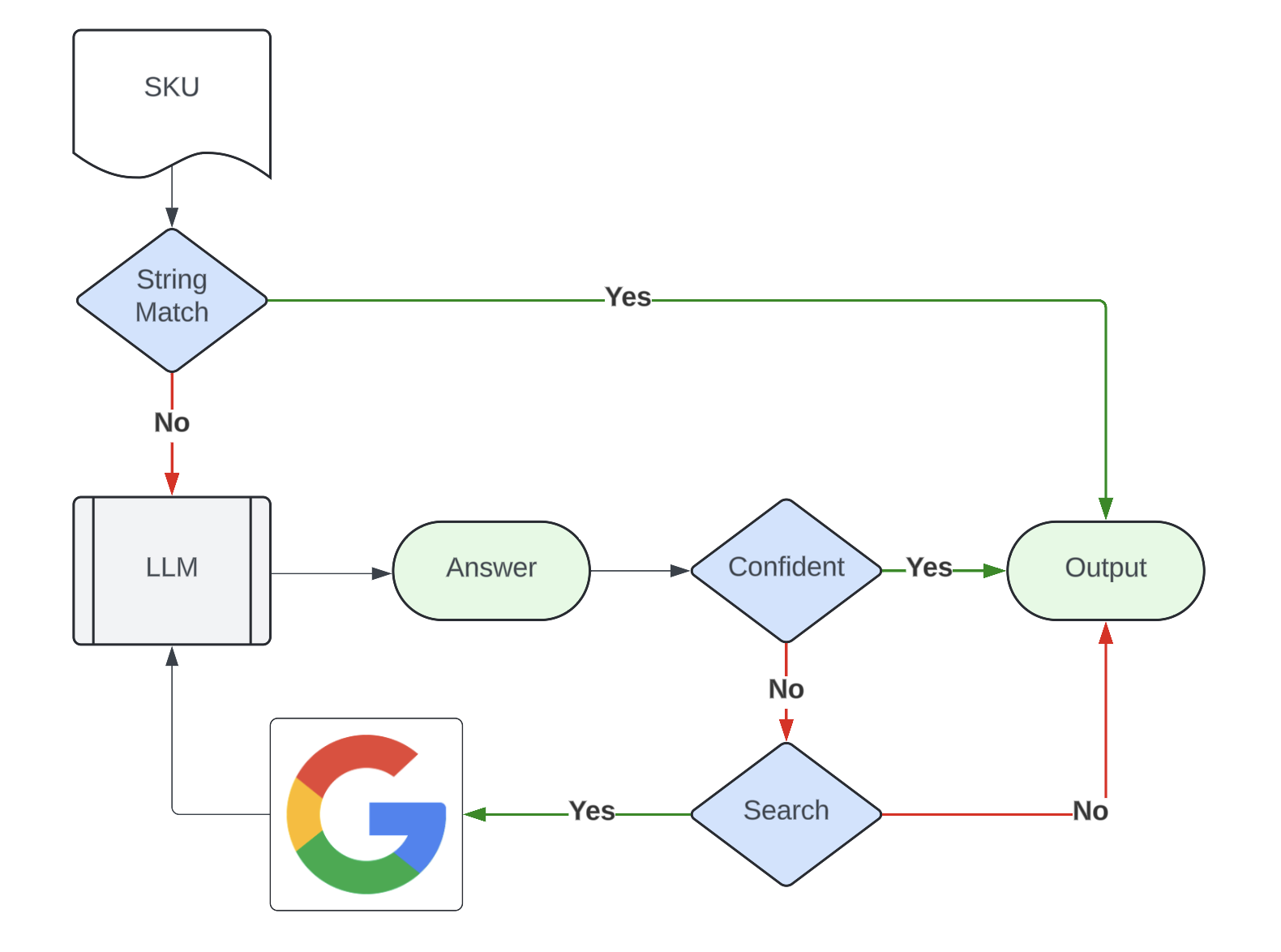
By leveraging LLMs and agents, we overcame the challenge of insufficient data and answered inferential questions via searching and reasoning using external data. Enhancing coverage of organic labels enabled us to launch item carousels that target customers' with strong organic affinity, which improved our top-line engagement metrics.
Generalized attribute extraction
Entity resolution is the process of determining whether two SKUs refer to the same underlying product. For example, “Corona Extra Mexican Lager (12 oz x 12 ct)” sold by Safeway is the same product as “Corona Extra Mexican Lager Beer Bottles, 12 pk, 12 fl oz” sold by BevMo!. We need accurate entity resolution to build a global catalog that can reshape the way customers shop while unlocking sponsored ads.
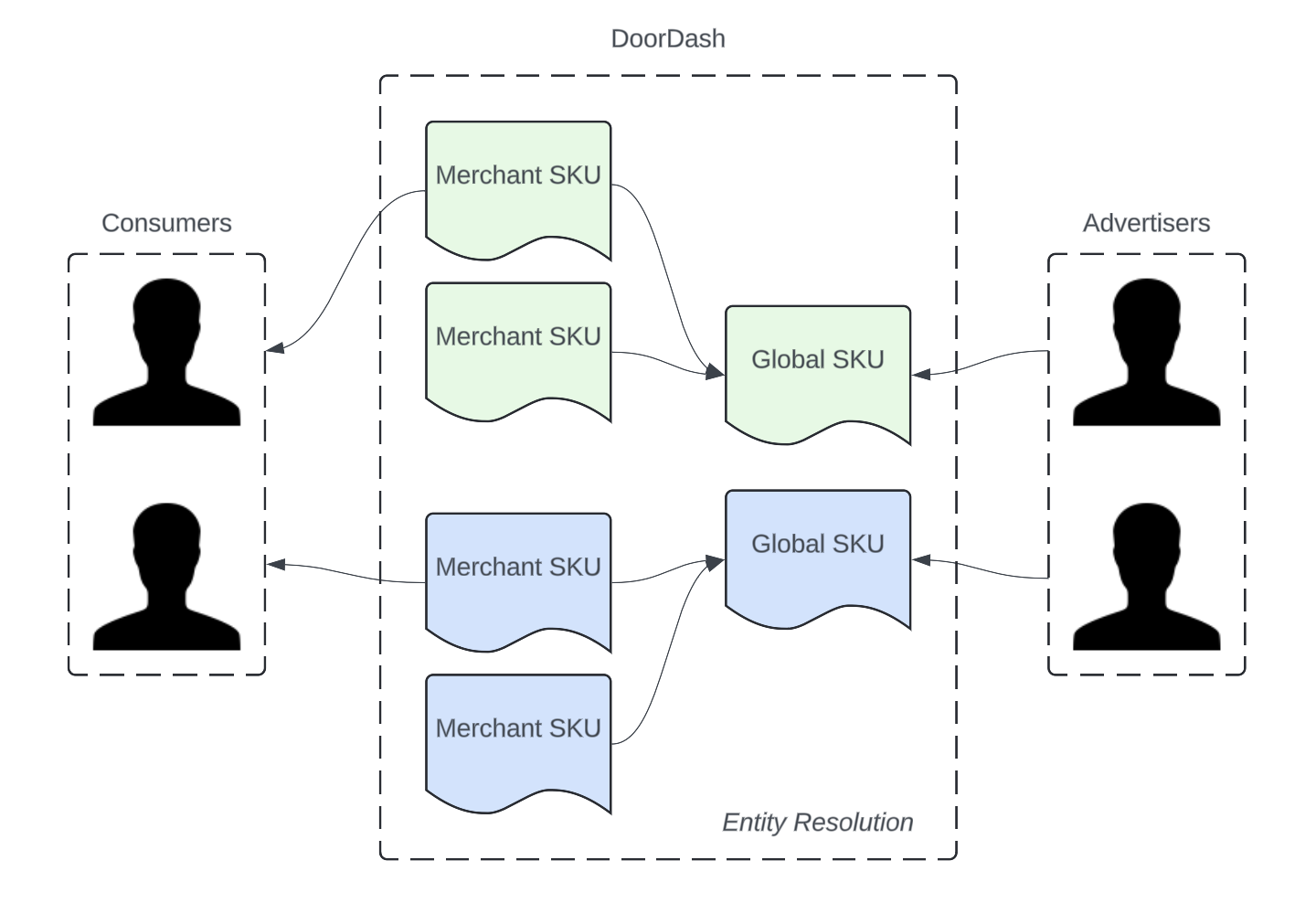
Determining whether two SKUs refer to the same underlying product is a challenging problem. It requires validating that both SKUs match all attributes exactly, which means there must be accurate extraction of all applicable attributes in the first place. Products from different categories are characterized by different sets of uniquely defining attributes. For example, an alcohol product is uniquely defined by attributes such as vintage, aging, and flavor. Starting with limited human-generated annotations, we used LLMs to build a generalized attribute extraction model.
We used LLMs and retrieval augmented generation, or RAG, to accelerate label annotations. For each unannotated SKU, we first leverage OpenAI embeddings and the approximate nearest neighbors technique to retrieve the most similar SKUs from our golden annotation set. We pass these golden annotation examples to GPT-4 as in-context examples to generate labels for the unannotated SKU. Choosing examples based on embedding similarity is advantageous over random selection because the selected examples are more likely to be relevant to the assigned task and reduces hallucination. Ultimately, the generated annotations are used to fine-tune an LLM for more scalable inference.
This approach enabled us to generate annotations within a week that would otherwise require months to collect, allowing us to focus on the actual model development to de-risk our goal.
Downstream impacts
Attribute extraction not only allows us to better represent each product in the catalog but also empowers downstream ML models that improve a customer's shopping experience. Attributes such as brand and organic tag are important features in our personalized ranking models, which recommend items that reflect a consumer's unique needs and preferences. And attributes such as product category and size enable recommending more relevant substitutions when the original item is out of stock, giving customers a smooth fulfillment experience.
Looking into the future
So far, most of our attribute extraction models are built on top of text-based inputs. A challenge with this approach, however, is the presence of abstraction and abbreviations within written product descriptions. Fortunately, product image quality varies less across merchants. We are actively exploring recent advances in multimodal LLMs that can process text and images together; currently, we are experimenting with multimodal attribute extraction through Visual QA and Chat + OCR. Our Engineering team is also building foundational technologies and infrastructures to allow Dashers to take product photos so that we can perform attribute extraction directly on in-store items.
As we identify more areas where LLMs can be used, we are also working with our ML Platform team to democratize their use across DoorDash through a centralized model platform where anyone can easily prompt-engineer, fine-tune, and deploy LLMs.
Acknowledgments
Special thanks to Aparimeya Taneja, JJ Loh, Lexi Bernstein, Hemanth Chittanuru, Josey Hu, Carolyn Tang, Sudeep Das, Steven Gani, and Andrey Parfenov, who all worked together to make this exciting work happen!

