

New service releases deployed into DoorDash’s microservice architecture immediately begin processing and serving their entire volume of production traffic. If one of those services is buggy, however, customers may have a degraded experience or the site may go down completely.
Although we currently have a traffic management solution under development for gradual service rollouts as a long-term solution, we needed an interim solution we could implement quickly.
Our short-term strategy involved developing an in-house Canary deployment process powered by a custom Kubernetes controller. Getting this solution in place gives our engineers the ability to gradually release code while monitoring for issues. With this short-term solution we were able to ensure the best possible user experience while still ramping up the speed of our development team.
The problems with our code release process
Our code release process is based on the blue-green deployment approach implemented using Argo Rollouts. This setup gives us quick rollbacks. However, the drawback is that the entire customer base is immediately exposed to new code. If there are problems with the new release, all our customers will find a degraded experience.
Our long-term answer to this problem consists of a service mesh that can provide more gradual control of the traffic flow and a special purpose deployment tool with a set of custom pipelines. This solution would allow us to release new code gradually so that any defects do not affect our entire customer base. However, this new system will take several cycles to build, which meant we needed to come up with a short-term solution to manage this problem in the meantime.
A quick overview of the blue-green deployment pattern
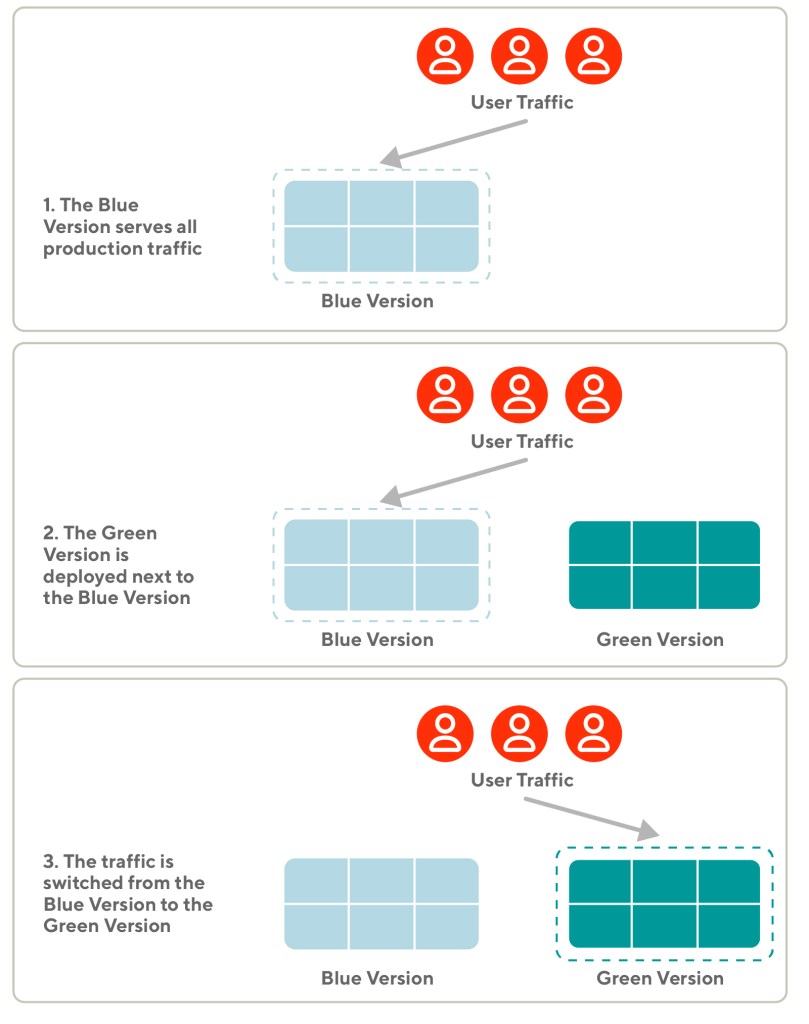
At DoorDash, we release new versions of our code following the blue-green (B/G) deployment pattern, as shown in Figure 1, below. B/G reduces the risk of downtime by keeping two versions of the same deployment running simultaneously. The blue version is stable and serves production traffic. The green version is idle and considered the new release candidate.
The actual release happens when the production traffic is switched from the blue version to the green version. After the switch, the blue version is still kept on hold as a backup in case there are problems with the green version. Rolling back to the blue version is instantaneous and immediately resolves any issues coming from the green version.
Utilizing Argo Rollouts for B/G deployments
Argo Rollouts is a framework that provides a set of enhanced deployment strategies, including B/G deployments, and is powered by a Kubernetes controller and some Kubernetes Custom Resource Definitions (CRDs). The Kubernetes objects created as part of the Argo Rollouts B/G CRD are called Rollouts. Rollouts are almost identical to Kubernetes Deployment objects, to which they add more advanced functionalities needed in scenarios such as B/G deployments.
The Argo Rollouts B/G implementation in detail
The Argo Rollouts B/G implementation is based on the Rollouts Kubernetes controller, a Kubernetes Rollout object, and two Kubernetes Services: one named Active Service and another named Preview Service. There are two separate versions of the Rollout: the blue and the green. Each version comes with a rollouts-pod-template-hash label that stores the (unique) hash of its specs and is computed by the controller.
The controller injects a selector into the Active Service with a value that matches the blue hash, effectively causing the Active Service to forward production traffic to the blue version. In the same way, the Preview Service can be used to target the green version in order to perform all tests needed to qualify it as production ready. Once the green version is deemed ready, the Active Service selector value is updated to match the green hash, redirecting all production traffic to the green version. The blue version is then kept idle for some time in case a rollback is needed.
The ability to almost instantaneously switch the incoming traffic from the blue version to the green version has two important consequences:
- Rolling back is very fast (as long as the blue version is still around).
- The traffic switch exposes the production traffic to the green version all at once. In other words, the entire user base is affected if the green version is buggy.
Our objective is a gradual release process that prevents a bug in the new release candidate code from negatively affecting the experience of our entire customer base.
A gradual deployment strategy requires a long-term effort
The overall solution to the deployment process problem we faced was to pursue a next-generation deployment platform and a traffic management system that can provide us with a more granular control of the traffic flow. However, the scope of such a workstream and the potential impact over our current setup make these changes only feasible within a time range spanning multiple quarters. In the meantime, there were many factors pushing us to find a short-term solution to improve the current process.
Why we needed to improve the current process
While our long-term strategy for gradual deployments was in the works, our systems were still at risk of disappointing all our customers at every deployment. We needed to ensure that customers, merchants, and Dashers would not be negatively affected by future outages that could erode their trust in our platform.
At the same time, our strong customer obsession pushed many of our teams towards adjusting their deployment schedules to minimize the potential customer impact of a buggy release. Late-night deployments became almost a standard practice, forcing our engineers to babysit their new production instances until early morning.
These and other motivations pushed us towards finding a short-term solution to provide our engineers with gradual deployments capabilities, without having to utilize non-optimal working requirements.
Our short-term strategy for gradual code releases: an in-house Canary solution
A Canary solution would be a fast, easy-to-build short-term solution that would allow teams to monitor gradual rollouts of their services so that buggy code would have minimal impacts and could be rolled back easily. This process involved figuring out our functional requirements, configuring our Kubernetes controller, and avoiding obstacles from Argo Rollouts.
Short-term solution requirements
We started by laying down a list of functional and non-functional requirements for our solution. It had to:
- leverage native Kubernetes resources as much as possible to reduce the risk and overhead of introducing, installing, and maintaining external components
- use exclusively in-house components to minimize the chance of our schedule getting delayed by factors, such as external dependencies not under our control
- provide an interface that is easy to use and integrated with tools our engineers were already familiar with
- provide powerful levers to control gradual deployments, but at the same time put guardrails in place to prevent potential issues like excessive stress on the Kubernetes cluster
- lay out a streamlined adoption process that is quick, easy, and informed
- avoid the additional risks of changing the existing deployment process, and instead integrating it as an additional step
Core idea: leverage the Kubernetes Services forwarding logic
Our solution was based on the creation of an additional Kubernetes Deployment, which we called Canary, right next to the Kubernetes Rollout running the blue version serving our production traffic. We could sync the labels of the Canary Deployment with the selectors of the Kubernetes Active Service, causing the latter to start forwarding a portion of production traffic to the Canary Deployment. That portion could be estimated starting from the fact that a Kubernetes Service load balances the incoming traffic among all the instances with labels matching its selectors. Therefore, the approximate percentage of incoming traffic hitting the Canary Deployment was determined by the following formula:
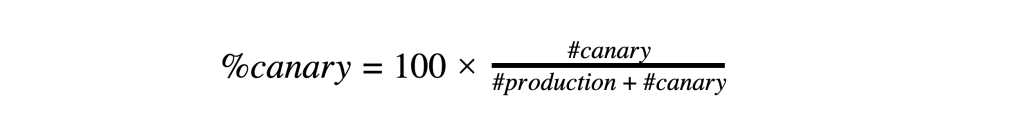
where #canary and #production represent, respectively, the number of instances belonging to the Canary Deployment and to the existing production Rollout. Our engineers can increase and decrease the number of instances in the Canary Deployment, respectively increasing and decreasing the portion of traffic served by the Canary Deployment. This solution was elegant in that it was simple and satisfied all our requirements.
The next step was to figure out how to sync the labels of the Canary Deployment with the selectors of the Active Kubernetes Service in order to implement the Canary solution.
Building a custom Kubernetes controller to power our Canary logic
One challenge to implementing our solution was to come up with a way to inject the Canary Deployment with the right labels at runtime. Our production Rollouts were always created with a predefined set of labels which we had full control over. However, there was an additional rollouts-pod-template-hash label injected by the Rollouts controller as part of the Argo Rollout B/G implementation. Therefore, we needed to retrieve the value of these labels from the Kubernetes Active Service and attach them to our Canary Deployment. Attaching the labels forces the Kubernetes Active Service to start forwarding a portion of the production traffic to the Canary Deployment. In line with the Kubernetes controller pattern, we wrote a custom Kubernetes controller to perform the label-syncing task, as shown in Figure 2, below:

A Kubernetes controller is a component that watches the state of a Kubernetes cluster and performs changes on one or more resources when needed. The controller does so by registering itself as a listener for Kubernetes events generated by actions (create, update, delete) targeting a given Kubernetes resource (Kubernetes Pod, Kubernetes ReplicaSet, and so on). Once an event is received, the controller parses it and, based on its contents, decides whether to execute actions involving one or more resources.
The controller we wrote registered itself as a listener to create and update events involving resources of type Kubernetes pods with a canary label set to true. After an event of this kind is received, the controller takes the following actions:
- unwraps the event and retrieves the pod labels
- stops handling the event if a rollouts-pod-template-hash label is already present
- constructs the Kubernetes Active Service name given metadata provided in the pod labels
- sends a message to the Kubernetes API server asking for the specs of a Service with a matching name
- retrieves the rollouts-pod-template-hash selector value from the Service specs if present
- injects the rollouts-pod-template-hash value as a label to the pod
Once the design of our Canary deployment process was concluded, we were ready to put ourselves in the shoes of our customers, the DoorDash Engineering team, and make it easy for them to use.
Creating a simple but powerful process to control Canary Deployments
With the technical design finalized, we needed to think about the simplest interface that could make our Canary Deployment process easy to use for the Engineering team we serve. At DoorDash, our deployment strategy is based on the ChatOps model and is powered by a Slackbot called /ddops. Our engineers type build and deploy commands in Slack channels where multiple people can observe and contribute to the deployment process.
We created three additional /ddops commands:
- canary-promote, to create a new Canary Deployment with a single instance only. This would immediately validate that the new version was starting up correctly without any entrypoint issues.
- canary-scale, to grow or shrink the size of the Canary Deployment. This step provides a means to test out the new version by gradually exposing more and more customers to it.
- canary-destroy, to bring down the entire Canary Deployment.
Once the interface was ready to use, we thought about how to prevent potential problems that may come up as a result of our new Canary Deployment process and build guardrails.
Introducing guardrails
During the design phase we identified a few potential issues and decided that some guardrails would need to be put in place as a prevention mechanism.
The first guardrail was a hard limit on the number of instances a Canary Deployment could be scaled to. Our Kubernetes clusters are already constantly under high stress because the B/G process effectively doubles the number of instances deployed for a given service while the deployment is in progress. Adding Canary pods would only increase this stress level, which could lead to catastrophic failures.
We looked at the number of instances in our services deployments and chose a number that would allow about 80% of services to run a Canary Deployment big enough to achieve an even split between the Canary and non-Canary traffic. We also included an override mechanism to satisfy special requests that would need more instances than we allowed.
Another guardrail we put in place prevented any overlap between a new B/G deployment and a Canary Deployment. We embedded checks into our deployment process so that a new B/G deployment could not be started if there were any Canary pods around.
Now that the new Canary Deployment process was shaping up to be both powerful and safe, we moved on to consider how to empower our engineers with enough visibility into the Canary metrics.
Canary could not exist without proper observability
Our new Canary Deployment allows our engineers to assess whether a new release of their service is ready for prime time using a portion of real-life production traffic. This qualification process is essentially a comparison between metrics coming from the blue version serving production traffic and metrics coming from the Canary Deployment running the new release candidate. Looking at the two different categories of metrics, our engineers can evaluate whether the Canary version should be scaled up further to more customer traffic or should be teared down if it's deemed buggy.
The implementation of this observability aspect was completely in the hands of our engineers, as each service had their own naming conventions and success metrics that could vary substantially based on the nature of the service. A clear separation between Canary and non-Canary metrics was possible thanks to specific labels injected only to the Canary pods. This way, teams could just replicate the queries powering their dashboard, adding an additional filter.
We designed adoptions to be easy, quick, and informed
The next and final step was to plan for helping the Engineering team adopt the Canary Deployments. As always, our objective was a quick and painless adoption. At the same time, we were providing our engineers with a powerful tool that was using our production traffic as a testbed, so we needed them to be empowered with knowledge about potential pitfalls and how to act in case things went wrong.
To onboard engineers quickly and safely, we designed a four-step adoption process that they could follow without any external help, as it was simply re-using concepts they were already familiar with. In this case we tried to stay away from fully automating the adoption process as we wanted them to understand its details. We also added a validation step at the end of the process that required explicit approval. This validation step enabled us to sit down with first-time users and guide them through their first Canary Deployment, explaining what was happening under the hood and what to do in case of failure.
The adoption campaign went better than anticipated
Initially, we prioritized adoptions for about a dozen services on the golden path of our workflows. Reducing the chances of those services suffering from a full outage meant improving by a great deal the reliability of the core customer flows that power our business.
We had a lot of positive feedback about the adoption procedure and the new Canary process overall, and what we observed was that additional teams onboarded their services and scheduled time with us to review their configuration. We ended up onboarding about twice the number of services we anticipated before the end of the year, which was a huge success, taking into account a deploy freeze during the holiday season.
Conclusion
Releasing new code carries risk and associated costs that can be mitigated using a gradual rollout strategy. However, Kubernetes does not provide this capability out of the box. All the existing solutions require some form of traffic management strategy, which involves significant changes at the infrastructure level and an engineering effort that can last multiple quarters.
On the other hand, the Kubernetes controller pattern is a simple but extremely powerful technique that can be used to implement custom behavior for Kubernetes resources, like advanced deployment strategies.
Thanks to our new Canary Deployment process powered by a custom Kubernetes controller and other company-wide efforts towards improving the reliability of DoorDash services, our customers, merchants, and Dashers can put their trust in our platform while our engineers work with greater velocity.
Interested in taking on challenging problems with practical solutions in a collaborative team environment? Consider joining DoorDash engineering!
Acknowledgements
The author would like to thank Adam Rogal, Ivar Lazzaro, Luigi Tagliamonte, Matt Ranney, Sebastian Yates, and Stephen Chu for their advice and support during this project.