

Building an ML-powered delivery platform like DoorDash is a complex undertaking. It involves collaboration across numerous organizations and cross-functional teams. When this process works well, it can be an amazing experience to work on a product development team, ship ML models to production, and make them 1% better every day.
The process usually starts with first identifying a product that we could improve by using Machine Learning. Once we identify an opportunity, we usually start small by testing the ML hypothesis using a heuristic before deciding to invest into building out the ML models. If the initial heuristic works, we build out and replace the heuristic with the ML models. This step is usually then followed by building out more tooling and infrastructure so that we can continue to experiment with different ML models and keep making the models 1% better.
In this post, we will outline all of the thought and work that goes into achieving that end product. As an example, we dive into how we decided to optimize when the restaurants should start preparing orders and when the Dasher should be dispatched to pick them up.
Scoping out the business problem: optimizing food prep times
Before our ML development journey starts we have to scope out the business problem and try to identify an opportunity for improvement. While different teams are focused on different aspects of our three-sided marketplace, we often create collaborations to solve joint business problems.
One example is around delayed food prep times that increase Dasher wait times. Long Dasher wait times are a negative experience because it's time Dashers could otherwise be using productively to maximize their earnings, and merchants may not want Dashers waiting for orders to be ready in a possibly small foyer. On the flip side, we don't want premature food prep times which could increase "food wait time," the time prepared food is sitting on the counter getting cold before the Dasher arrives to pick it up.
In order to achieve an optimal meal prep time and optimal Dasher wait time, we rely on both internal and external systems and operations. We aim to time the Dasher's arrival at the store with the food ready time. In most cases, we rely on the restaurants to start preparing the food ahead of the Dasher's arrival. Different restaurants start preparing food at different times - sometimes due to other pending orders, sometimes due to higher sensitivity to food waiting on the counter. In some cases, restaurants may wait for the Dasher's arrival to prepare the food, which may cause higher wait times for the Dashers. With this high-level business problem the next step is to dig into the details and figure out exactly what's going on so we can find an opportunity to optimize.
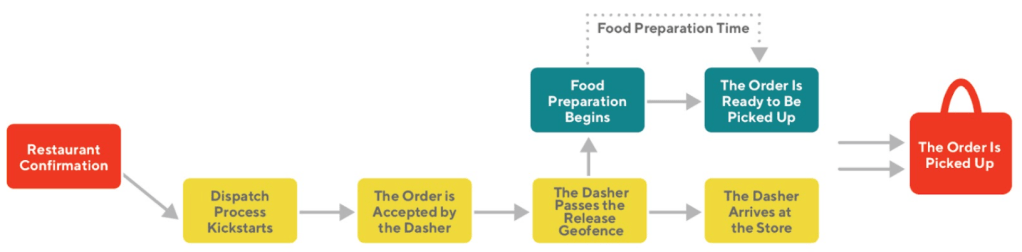
When do restaurants start preparing food?
Usually, restaurants start preparing an order once it's been confirmed (see Figure 1). At the same time, right after the order is confirmed by the merchant, we kickstart the matching and dispatch process. Once a Dasher accepts the order, they will be en route and notified when the order is ready for pickup.

One of the examples where we adjust our decisions and algorithms to the unique needs of our merchants is in the case of "quick service restaurants" - restaurants that generally require very low food preparation times and are more sensitive to food wait times. Merchants at these types of restaurants used to begin preparing these orders only when the Dasher arrived, to ensure the quality of the food upon delivery. This resulted in higher Dasher wait times and longer delivery times and led us to develop the Auto Order Release (AOR) process.
Auto Order Release (AOR)
We mentioned earlier that in a traditional dispatch flow the restaurants start preparing the food as soon as they confirm the order. In the AOR flow, the merchants confirm the order, but the order is held from being released to the kitchen (Figure 2). The order will be automatically released to the kitchen only when a Dasher is at a certain distance from the store. This distance is determined using geolocation indicators and is called the "release distance." When the Dasher enters this predefined geofence, the order is released to the kitchen so they can start preparing the food.
In order for a merchant to be onboarded on this flow, they will work directly with our merchant teams. Once the merchant is onboarded, our merchant and analytics teams will work to define which stores should be defined as AOR stores, and what the release distance should be for each store. When a store is onboarded with AOR, all of its deliveries are placed on a delayed release.
Delving into the Dasher wait-time problem:
Introducing AOR reduced Dasher wait times and delivery times compared to the earlier state where restaurants were waiting on the Dashers to arrive first since the restaurants started preparing the food a bit earlier. While this flow still protected the food quality, it did introduce some new business challenges over time:
- The delayed release setting is defined on a store level. This offers very little flexibility and caps our ability to optimize wait times
- The merchant efficiency teams started noticing that more and more merchants were notifying us about Dashers waiting at stores
- Continuous data exploration identified that we are far from optimizing the time the Dashers spent waiting on orders to be prepared. The actual variance in food preparation and Dasher arrival times was not represented well enough when relying only on hardcoded geofences
- Adding new merchants to AOR became challenging to scale since it required manually defining geofences for each store
Building a strategy and a team
We saw an opportunity to update the AOR flow from a hard-coded heuristic based flow to a more dynamic decision-making system to optimize Dasher wait times at the store without degrading the food quality. This kind of task is hard to achieve without cross-functional collaboration. It requires updating our assignment system and upstream services, as well as maintaining a deep understanding of the merchant's operation and experience.
We formed a formal cross-functional working group consisting of Strategy and Operations, Data Science & Machine Learning, Product, Analytics, and Engineering. Our end goal was to develop a feature that dynamically decides on the optimal order release time for each delivery and reduces Dasher wait times without increasing food wait times.
Defining milestones through collaboration and iteration
While our goal was to launch a new ML-based feature, to align with our "dream big, start small" mentality we had to define very well-scoped milestones and steps and divide responsibilities efficiently. We wanted to balance reaching faster short-term results and maintaining our long-term vision. To achieve that, we agreed on these high-level milestones:
MVP: heuristics-based
Starting with a simple set of conditions allows us to first implement a simple approach that we believe can perform better in production than our current solution. The MVP is driven mostly by our strategy and analytics team, and we relied on engineering to make the needed architectural updates.
- Add the infrastructure ability to decide for each order if:
- The order should be instantly released to the kitchen (traditional flow)
- The order should be placed on a delayed release (original AOR flow)
- Define and test an initial set of heuristics to decide on the order release type
Final feature: ML-based
- Develop an ML model to estimate the time needed for AOR merchants to prepare food
- Update our architecture to call ML models to decide if an order should be placed on a delayed release or an instant release
- Use ML models to define the optimal geofence
Let's go through a few of the main milestones to understand what our main considerations were at each step.
Stay Informed with Weekly Updates
Subscribe to our Engineering blog to get regular updates on all the coolest projects our team is working on
Please enter a valid email address.
Thank you for Subscribing!
New feature, starting simple
Our starting point was a flow that's hard coded on a store level. So if a store was put on AOR, we couldn't change the release strategy for an order even if we had indicators that the store needs more time to prepare the food. The first thing that we had to do was to change the architecture and add the ability to dynamically decide for each delivery, if the order should be placed on a delayed release (regular AOR) or released to the kitchen immediately (if we anticipate the store needing more time to prepare the food).
To get started, we defined a new set of simple conditions (heuristics) to trigger the decision for each order. For example, we know that larger orders at certain times require longer to prepare. This way, even if a store is placed on AOR, if we believe that the required prep time will be longer than a threshold, releasing the food immediately will allow more time and therefore reduce Dasher wait times. Our analytics and merchant teams identified some stores with high Dasher wait times and partnered with some merchants to launch an experiment to examine if we can lower Dasher wait times without degrading any of our core food quality metrics. Once the MVP was ready, we were able to start experimenting in production.
Launching experiments as soon as possible
Kickstarting experimentation as soon as possible enables us to start gathering insights and keep the development going at the same time. Incorporating ML required additional development, both on the architectural and research side (we need to connect to more services to make calls to get our ML predictions and we need to develop and add new models to our training and prediction pipelines). Taking this simple, heuristics-based approach first allowed us to start gathering insights and answering questions such as:
- Does the feature work in the production environment as expected?
- Are merchants following the new process as expected?
- Can we observe the anticipated dasher wait time reduction in the production environment? Are there any unknowns that we did not account for?
In our case, we immediately saw a reduction in the wait times that the Dashers were experiencing. Adding the ability to decide on a release strategy for each delivery vs. on a store level resulted in higher prep time orders being released earlier, giving merchants more time to prepare food. This bias for action paid off, and when concluding this experiment, we already had:
- A working, simple MVP that can be shipped in production (the result of our initial experiments)
Also, since we used the time we ran the experiment to keep developing a more dynamic solution we were also ready with:
- A testable system that can connect to multiple services to get real-time predictions
- A set of ML models that are good candidates to replace our initial heuristics
And beyond the technical progress, getting the MVP out as soon as possible got us:
- Improvement in our core metrics
- Buy-in from stakeholders that gained us more time to incorporate ML models into our feature
Adding an ML layer to better optimize Dasher wait times
Once we have established our MVP and shipped it in production, we started gradually introducing more complexity and sophistication into our system.
Building a set of new predictors
In order to decide when to release an order to the kitchen, we developed a set of new predictors to estimate the time needed for the restaurant to prepare the food against the time needed for a Dasher to arrive at the restaurant and pick up the food. We relied on a few existing models to estimate the Dasher arrival time. While we already have various prep time models, we had to develop a new predictor for the AOR purpose since there are a few unique features in this case that were not captured in the general marketplace models. We used a LightGBM model that reached both great performance offline and proved to work and scale well in similar use cases at DoorDash.
Evaluating the model's performance against business metrics
One of the main challenges of selecting the best model offline is the limited predictability of the business metric impact. Our core model predicts the food preparation time and the product goals were reducing the Dasher wait times without degrading the end-to-end delivery time and without increasing food wait times. Moving quickly to experiments helped us determine how to tune our loss function to capture these unique business requirements. One of the great advantages of using LightGBM was the ease of adjusting the loss function to bias and tuning the model's performance to our unique business needs.
Through the finish line
After a few months of work, we have reached the majority of our original plan - a new feature that leverages ML models to dynamically decide when an order should be released to the kitchen. We had a few more hypotheses we wanted to test and a goal of leveraging the above architecture and models to dynamically define the optimal release distance for each order that was placed on a delayed release. One of the surprising challenges was defining when our work is complete and when we move to a different type of development life cycle - continued maintenance and monitoring. We decided to scope some additional work to test a new Dasher speed estimation model. This new model improved our accuracy and provided another incremental win to wrap up our development work.
Conclusion
In this post we described how we applied a few important practices to design and ship a new feature; start simple, break it down into milestones and work iteratively. While these are relatively common practices, there are a few unique work characteristics here at DoorDash that enabled our success:
- Strong bias for action: it might be difficult to define what "good enough" actually means and not be paralyzed by all the different ways we can make something better. We are a very experimentation-oriented team and we encourage each other to ship as soon as we can make a positive impact
- We operate in a unique way that allows us to construct teams around great ideas to see them mature and ship them in production. This team was constructed from the bottom up - solid analysis and cross functional collaborations led us to build a formal team
- Providing incremental results was the fuel that we needed to get time and buy-in to reach our longer term goal. Building ML infrastructure and developing models that can perform in production takes time and can be a risk. We constantly maintain some balance between these short term and long term bets
- Building out the necessary tooling to support the feature as it grows - operations tooling for easily onboarding stores, tooling for faster debugging, and frameworks for rapid experimentation
We hope these steps and approach can pave a path for others who are facing similar challenges and sheds some light around ML development at DoorDash.

