

In our previous article of this series we covered the decision we made at DoorDash to move to a microservice architecture, the technologies we chose, and how we approached the transition. As with most decisions in computer science, this one also came with its unique sets of challenges and shortcomings. This article focuses on the main pain-points we encountered in moving off of the monolith, with particular focus on the following:
- Changes in reliability patterns
- Data migration
- Workflow visibility
- Data access layer
- Overall testability
- Deployment etiquette
- Tech stack proliferation
Hopefully our summation of these challenges will be useful for those beginning the journey of migrating to a microservice architecture, as we give an overview of common gotchas of leaving the monolith as well as high-level solutions that we have or still are in the process of implementing to address them.
Changes in reliability patterns
When rearchitecting a system from a monolith to a service-oriented architecture (SOA), it is common to run into reliability challenges that can get out of control if not addressed early on in the process. These challenges are typically due to the intrinsic nature of working with an SOA instead of a monolith: when dealing with the monolith, working with cross-domain business logic is as easy as making a simple function call. When moving to microservices this kind of cross-domain interaction gets more complicated because of internal process communication being replaced by RPC, which can hurt latency and reliability unless the proper guardrails are put in place.
DoorDash’s monolith was a single big service backed by a single Postgres cluster as the most frequently accessed external dependency. As long as both components are healthy, the system can be considered functional for the most part. Once microservices are in the picture, however, anti-patterns, such as the following, begin appearing:
- Strong dependencies, where services become unable to fulfill a user request, even partially, unless one or more dependent services are also functional.
- T0 services (Golden Workflows), a new class of services that are critical to the business logic, so much so that any downtime in any one of these services results in the application becoming unavailable.
In both the cases above, the net effect is that the platform’s SLOs, either at the service level or system wide, becomes subject to uptime compound probability: if two services are part of the Golden Workflows (like order fulfillment and the dispatch logistics service are on DoorDash’s platform) and they both have a 99.9% uptime, the uptime of the workflow itself becomes 99.8%:
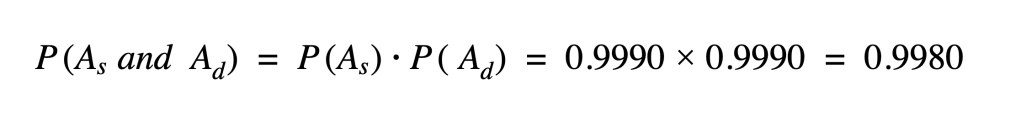
When too many services are entangled in a mesh of strong dependencies, the platform becomes a distributed monolith. A distributed monolith is strictly worse than a regular monolith in terms of reliability because failures even in seemingly unimportant flows can bring down the whole system.
In order to prevent proliferation of cases like the one described above and mitigate the negative effect of service dependencies, we introduced new access patterns for cross-service communication, such as:
- Request fallback, where we make sure there is an alternative source of critical data in case the primary source is unavailable. When this is employed, we get to compound the downtime probability instead of the uptime, hence resulting in higher availability. For example, if the main source of some particular data has 99.9% availability, and the fallback also has 99.9% availability, a service’s uptime won’t be as impacted, as shown in Formula 2, below.
- Fail open, if we can partially serve a request when a dependency is unavailable by simply ignoring the failure and applying some default behavior, we have removed a strong dependency from our microservice. For example, if we are unable to shorten a URL we wish to send over SMS to a consumer, we use the full URL instead of failing the request.

In the spirit of making these patterns widely used, we introduced libraries that take care of such patterns automatically, by service owner recommendations. We also instituted a reliability bootcamp where we help new developers become aware of the most common gotchas of building microservices.
Migrating data from monolithic storage
When migrating to a microservices architecture there’s an expectation that each individual service is the owner and sole source of truth of its data. In DoorDash’s case, the monolith wasn’t simply limited to the application code, our data storage was also monolithic. For the most part, our data existed in a single Postgres cluster which was quickly reaching its limits in terms of the primary node’s vertical scalability. As we broke down the monolithic application into microservices, we also had to perform data extraction from the monolithic storage into multiple clusters.
Extracting data from a database (DB) is a well known problem in the industry, and one with no easy solution, especially when the expectation is to have zero downtime during the migration. One of the most common approaches to data extractions is using double writes and double reads, where services gradually switch their traffic from the monolithic database instance to a new one, table-by-table, as shown by Figure 1, below:

To give a high level summary of how this works, the approach consists of writing all new rows of a specific set of tables in both the new and old DB, while a backfiller job copies the old rows. Once there’s enough confidence on the new DB, read traffic is gradually shifted to the new DB until the old one is finally decommissioned.
While this approach works in most cases, at DoorDash we found some hidden complexities in the form of race conditions that can happen depending on the specificity of the access patterns and schemas that are being migrated. Indeed, no configuration can instantly propagate to all the components of a distributed system, so for brief periods of time there was no single source of truth for a given row or partition of rows. In tables exposing multiple uniqueness constraints, this can result in data inconsistencies or conflicts that often need to be manually resolved.
Moreover, this approach would either require a common data access layer to manage the double read/writes or some work being done by all the service owners on a service-by-service basis, which would be costly. A common data access layer is usually present in a monolith, but depending on the order in which data is extracted, respective to the application logic extraction, this might not be true. At a time when stack proliferation was a problem, as new microservices were born faster than company standards were created, we opted for a different but yet successful approach: atomic swap of a single source-of-truth.
This topic alone deserves an article by itself, which we will publish in the future. And it’s going to touch on tons of interesting technical aspects of database management systems in general and Postgres specifically.
Ensuring workflow visibility and observability
One of the advantages of running a monolithic application is that, more often than not, there is a common middleware layer which intercepts all calls and can enforce all sorts of common functionalities. This is very helpful because it can monitor everything from authentication to authorization, as well as metrics and logging.
When running a monolith, metrics are predictable, dashboards can be easily replicated, and minimal domain knowledge is needed to come up with a common set of relevant indicators for workflows that are useful for creating new cross-domain measurements. For example, service level indicators (SLIs) can be identified for all workflows as they are all exposing the same metrics, with the same naming and labels, allowing a more consistent definition of per-workflow SLOs.
In the microservice-extraction frenzy, it’s easy to end up in a situation where each team adopts a different tech stack and library versions, creating their own conventions around metrics. This situation results in teams developing their own separate tribal knowledge.
When that happens, it not only becomes difficult for non-domain owners to understand other domains’ metrics, but often situations arise where it’s really hard to tell which service is involved in a given workflow. This ambiguity makes it very difficult to identify superfluous strong dependencies (as defined above) until there is a full-on outage.
To solve this domain tribalism problem, it is important to make the early effort to specify an observability standard, a set of company-wide recommendations that define what needs to be measured in every single service as well as the naming and labelling. In addition to that standard, adopting transparent solutions to distributed tracing (a la OTEL) sooner rather than later saves lots of headaches in answering questions like: “Why did the increase in p99 response time of a given service result in a huge traffic drop of a seemingly unrelated service?”
As the standardization effort becomes more substantial, and new internal frameworks are born, it’s also essential to include all the above knowledge in these frameworks so that future generations of architecture can benefit from them and once again gain that centralized layer of control for endpoint observability.
Building a data access layer
Once again in this article, it seems like we are going to praise the monolith for all of its centralized components that can be tweaked by a few expert engineers in ways that benefit everyone in the company. In this case, we refer to the monolith’s data access layer, in which even the smallest change can result in tremendous benefits for the whole team. The data access layer is a component usually found in monolithic applications that intercepts all queries to external data storages, and is able to run any custom code to observe, optimize, and redirect such queries.
While it’s risky to have a single database cluster that holds all a company's data, it is actually good to have a single codebase that handles all the storage access. This centralized access layer can be used and tweaked to obtain things like:
- Predictable query observability (described in the previous section)
- Automatic caching
- Multi-tenancy
- Automatic primary/replica routing w/ read-your-own-writes capabilities
- Query optimization
- Connection pooling
- Control over suboptimal access patterns (N+1 anyone?)
- Control over schema migrations for online tables (a simple CONCURRENTLY keyword can make the difference between an outage and a smooth index creation)
To be completely fair, one of the advantages of moving to a microservice architecture is the ability to experiment with new database technologies that might fit a specific use case better than others. But, at the end of the day, there’s a chance that most services in an engineering organization are using homogeneous DB types. And they could really use all the good stuff mentioned above.
Moving from a centralized data access layer to a distributed system is a problem that is still very much open at DoorDash, and also widely discussed. Possible solutions involve things like building a centralized schema migration tool, gated by the Storage team, that provides linting and code reviews ensuring that migrations are safe before they run in production. In addition to that, DoorDash’s Core Platform and Storage teams have recently invested in a centralized data access layer in the form of a DB gateway, which is deployed in isolation for each DB cluster and replaces the SQL interface for microservices with an abstract API served by a gRPC gateway. Such a gateway needs many precautions, such as isolated deployments, versioning, and configuration, to make sure it doesn’t become a single point of failure. Figure 4, below, shows at a high level what this data gateway looks like.

Ensuring testability
Experienced engineers will feel that sense of déjà vu every time they see a staging environment falling into oblivion at a speed that is directly proportional to the number of heterogeneous services populating it. Staging environment degradation is a process at risk of accelerating during the microservice migration frenzy: this is a time when new services are extremely fluid and change continuously, especially in staging, which often doesn’t have the same SLOs that are expected from a production environment, eventually rendering it nearly unusable. Services with many dependencies compound this degradation.
In order to grow past this problem, testing needs to evolve together with architecture. Along with introducing new testing frameworks for integration testing, synthetic monitoring, and load testing, DoorDash recently began the journey of putting in place the necessary guardrails in its production environment to allow for safe testing in production. These guardrails are based on the principle of allowing our developers to experiment with new features and bug fixes in production without the risk of polluting the real traffic or, even worse, data.
This topic is a widely covered one in the industry, and going into the details of what DoorDash is building to make this happen probably deserves its own article. For now, here is a high-level overview of the main components and guardrails that make up our production testing environment:
- Proxies that reroute test traffic from the edge into local development environments
- Standardized test traffic definition and propagation in each hop of a request through OpenTelemetry (OTEL) baggage
- Data at rest isolation through query-routing and query-filtering based on traffic tenancy (enforced by the data access layer discussed above)
- Configuration isolation through namespacing of our experiments, runtime configuration, and secrets, based on traffic tenancy (enforced by common libraries)
- Test Actors Service which provides test users to developers
- Developer console for managing testing environments and creating new scenarios
One important objective of the testing-in-production project at DoorDash is that, once test traffic is generated, all guardrails around test data are enforced at the platform/infrastructure level without requiring any knowledge from the microservices. By ensuring that our services are tenant-agnostic, we prevent the proliferation of tenant-specific branching in our services’ codebase that we would inevitably have otherwise.
Dealing with tech stack proliferation
When looking back at the challenges DoorDash faced in building the existing architecture, one simple answer would often come to mind: just build a common library.
In the monolithic world, where everything ran in a single codebase based on the Django framework, it was really easy to build new libraries for common usage as well as upgrading existing ones whenever a new feature or security improvement was released. The thought of having a single requirement file to update for all teams to benefit from was a comforting one.
As we moved to microservices, developers began experimenting with languages and solutions that felt the most appropriate for the problem at hand. In the beginning, services were born using a variety of languages, namely Python3, Kotlin, Java, and Go. On one hand, this was a really good time for the company: by getting hands-on experience with multiple languages we were able to eventually standardize on a few technologies, and started our internal standardization effort based on Kotlin. On the other hand, however, it became really difficult to share code and add new service-level functionalities. Accommodating all our different stacks now required writing libraries for multiple languages as well as relying on the deployment cadence of each service so services can pick up whichever new library version is needed.
After that initial period of experimentation, we started building internally-supported frameworks and libraries for greenfield services, added linting to all our repositories to catch dependencies that need to be upgraded, and began the effort of reducing the number of repositories, while keeping roughly the same number of microservices (some organizations are currently testing one monorepo per org). For the most part, the Kotlin Platform team at DoorDash is responsible for leading these standardization efforts, providing developers with the basic templates and frameworks that solve some of the issues discussed in the previous sections of this article.
Defining deployment etiquette
So far we have focused on a number of challenges involved in building a microservice architecture that were mostly rooted on the same principle: the shared codebase of a monolith has some advantages that microservices risk losing. Another aspect to consider, however, is how things that are normally perceived as an advantage of moving away from a monolithic architecture could in reality hide some challenges. Case in point, the ability to freely deploy services independently of each other.
With the monolith, deployments were more predictable: a single release team handled all deployments, and a new version of the whole application was released to the public at a regular cadence. The deployment freedom that microservices come with, however, can result in proliferation of both good and bad practices, with the latter causing different kinds of outages from time to time. Moreover, unpredictable deployment times can cause delayed response from oncalls of related services, such as upstream dependencies.
Mitigating these problems and establishing proper deployment etiquette required DoorDash’s Release Team to shift focus from being the deployment gatekeepers to building deployment tools aimed at enforcing those best practices, such as raising a warning whenever a peak hour deployment is attempted, or by providing easy ways to roll back code with a simple click of a button. Moreover, global kill switches have been put in place to freeze all unapproved deployments in certain critical situations, so as to prevent unaware developers from deploying new code during, for example, an outage. Finally, pipelines have been built to implement a global changelog, which gives visibility on each and every change that happens in our production environment, from deployment to runtime configuration changes. The global changelog is a powerful resource in the event of an outage, as it gives engineers the ability to identify what caused the issue and promptly roll back.
Lessons learned from migrating off the monolith
After discussing all the pain points of leaving the monolith it almost makes one question why we did in the first place. Despite all the advantages a small engineering team could get from working on a monolith the advantages that come from moving to microservices are tremendous and worth solving the pain points mentioned above. We gain the ability to independently scale and deploy single components, to reduce the blast radius of bad deployments, scale as an organization, and experiment more quickly.
To benefit from a microservice architecture, an organization needs to approach the extraction carefully. After all, losing commonly shared code can lead to inconsistent behaviors across services for things like visibility and data access, deployment freedom can become detrimental without the proper guardrails in place, tech stack proliferation can grow out of control, testability can become more challenging, and bad patterns in establishing service dependencies can lead to distributed monoliths.
At DoorDash we faced all of these challenges in one form or another, and learned that investing in standardization, good practices, testability, and common data access/observability layers will result in a more reliable and maintainable microservice ecosystem in the long run.