

When a company with millions of consumers such as DoorDash builds machine learning (ML) models, the amount of feature data can grow to billions of records with millions actively retrieved during model inference under low latency constraints.
Category Archives: AI & ML
Uncovering Online Delivery Menu Best Practices with Machine Learning

Restaurants on busy thoroughfares can use many elements to catch a customer’s eye, but online ordering experiences mostly rely on the menu to generate sales.
Solving for Unobserved Data in a Regression Model Using a Simple Data Adjustment

Making accurate predictions when historical information isn’t fully observable is a central problem in delivery logistics.
Improving Online Experiment Capacity by 4X with Parallelization and Increased Sensitivity

Data-driven companies measure real customer reactions to determine the efficacy of new product features, but the inability to run these experiments simultaneously and on mutually exclusive groups significantly slows down development.
How DoorDash is Scaling its Data Platform to Delight Customers and Meet our Growing Demand

Today, many of the fastest growing, most successful companies are data-driven.
Leveraging Causal Modeling to Get More Value from Flat Experiment Results
A/B tests and multivariate experiments provide a principled way of analyzing whether a product change improves business metrics.
Retraining Machine Learning Models in the Wake of COVID-19

The advent of the COVID-19 pandemic created significant changes in how people took their meals, causing greater demand for food deliveries.
Supporting Rapid Product Iteration with an Experimentation Analysis Platform

DoorDash’s new experimentation platform, built on a combination of SQL, Kubernetes, and Python, allows for quick iteration of data-driven feature improvements.
Using a Human-in-the-Loop to Overcome the Cold Start Problem in Menu Item Tagging

Companies with large digital catalogs often have lots of free text data about their items, but very few actual labels, making it difficult to analyze the data and develop new features.
Building a system that can support machine learning (ML)-powered search and discovery features while simultaneously being interpretable enough for business users to develop curated experiences is difficult.
Optimizing DoorDash’s Marketing Spend with Machine Learning
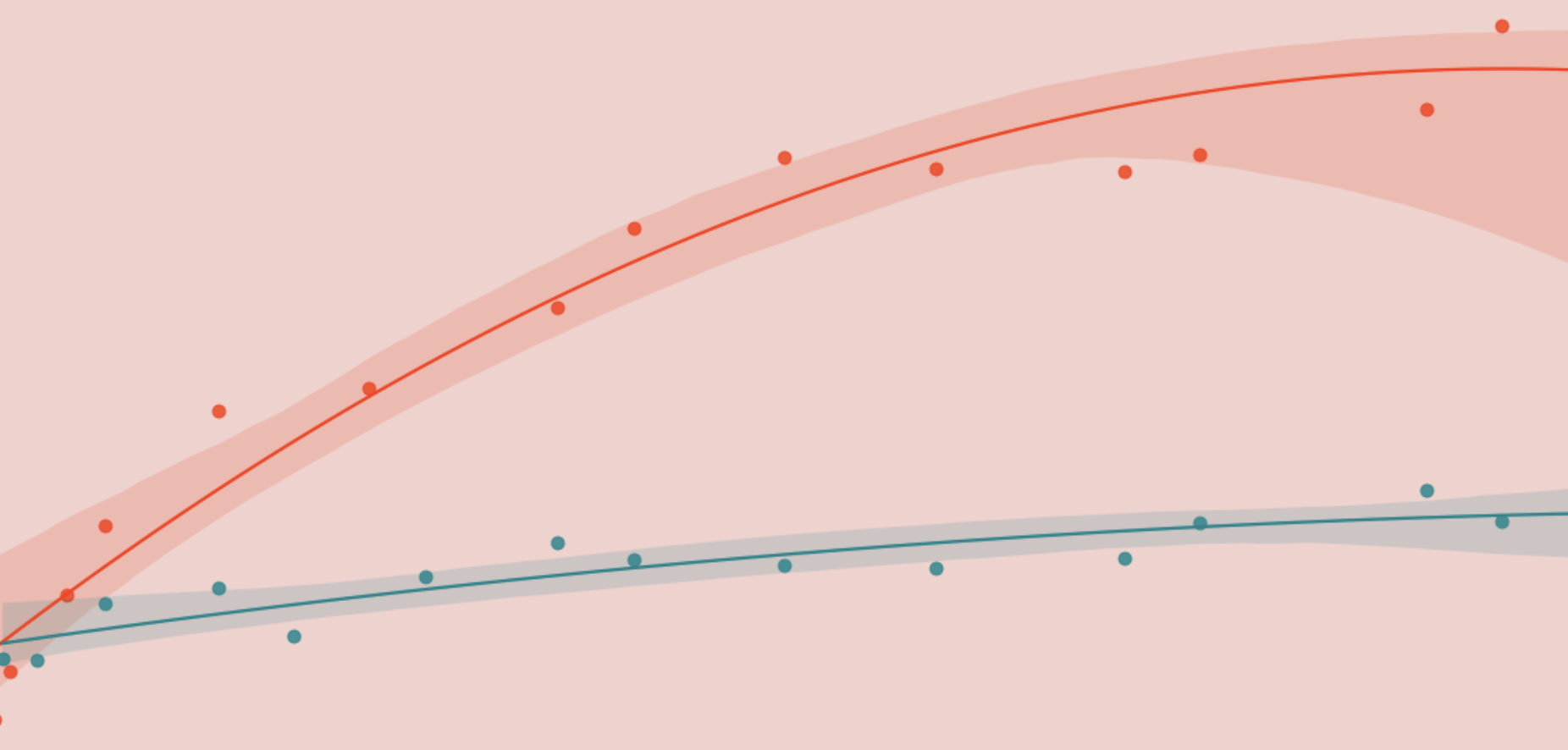
Over a hundred years ago, John Wanamaker famously said “Half the money I spend on advertising is wasted; the trouble is, I don’t know which half”.