

Today, many of the fastest growing, most successful companies are data-driven. While data often seems like the answer to many businesses’ problems, data’s challenging nature, from its variety of technologies, skill sets, tools, and platforms, can be overwhelming and difficult to manage.
An added challenge is that companies increasingly need their data teams to deliver more and more. Data’s complexity and companies’ increased demand for it can make it challenging to prioritize, scale the team, recruit top talent, control costs, maintain a clear vision, and satisfy internal customers and stakeholders.
At DoorDash we have been able to navigate a number of these hurdles and deliver a reliable data platform that enables optimal business operations, pricing, and logistics as well as improved customer obsession, retention, and acquisition.
This has only been possible through a series of technical considerations and decisions we made when facing the typical challenges of scaling a data organization.
This article sheds light on the challenges faced by organizations similar to ours and how we have charted the course thus far. We share a few tips and ideas on how similar challenges can be navigated in any large, growing, data-driven organization.
Data platform beginnings: collecting transactional data for analytics
We captured the beginnings of the data infrastructure and solutions at DoorDash in this article published a few years ago. With a scalable data infrastructure in place, we could proceed to leveraging this data for analytics, which lets DoorDash make data-driven decisions about everything from customer incentives to technology vendor choices.
When growing a data platform organization, the first task is to take stock of the transactional data (OLTP) solution(s) used in the company. Once the attributes, such as data schemas and products used are known, it’s possible to start the quest for the right data analytics stack.
It's not atypical for many organizations to tap into the existing transactional databases for their analytical needs, a fine practice when getting started but one that won't scale long term. It's more typical to ETL the data from transactional databases to an appropriate data warehouse system.
Collecting all the transactional and external data needed for analytics is the first step. Once we had this, we then looked into the emerging data needs of DoorDash as described in the sections below.
Ways of conceptualizing data organization growth
The needs of an organization can also be seen in the same light as Maslow’s hierarchy of needs, as shown in Figure 1, below:
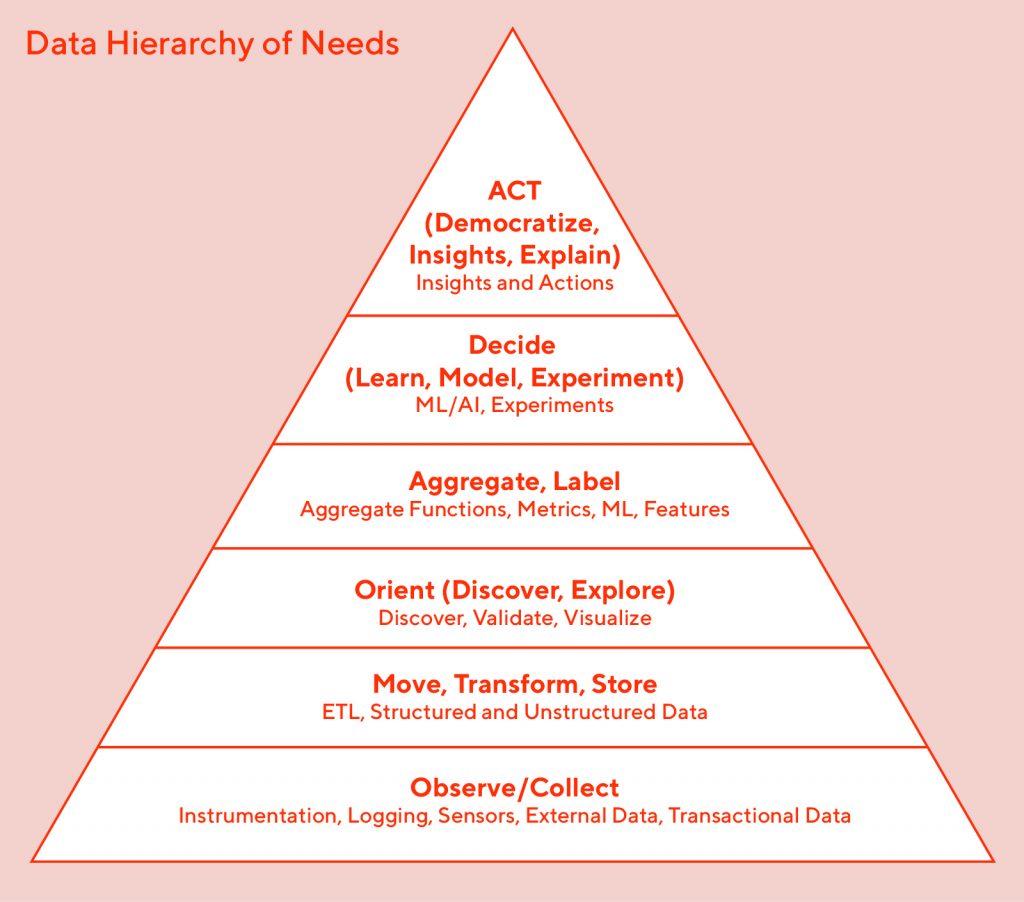
At every level of the pyramid there are more advanced data operations.
Beginning with the need to simply collect, compute, and analyze data for business intelligence needs, growing companies will evolve and will need to venture into other needs on the pyramid, such as machine learning and artificial intelligence based inferences, data-driven experiments, and analysis.
As the size and complexity of the business increases, the data team's responsibilities will grow to include such tasks as data discovery, lineage, monitoring, and storage optimizations until they have reached the top of the pyramid.
Stay Informed with Weekly Updates
Subscribe to our Engineering blog to get regular updates on all the coolest projects our team is working on
Please enter a valid email address.
Thank you for Subscribing!
Another method of addressing the growing needs of an organisation is to look at the time taken for insights to be computed and available from the time data was collected (ingest) from various sources.
In other words, how quickly is the data collected (as shown in the bottom of the pyramid) and made available to end users such as analysts and product/business leads?
How quickly can end users act on this insight/information and positively impact the business?
This is a continuous process, and is better envisaged using an OODA Loop (Observe, Orient, Decide, and Act), shown in Figure 2, below:
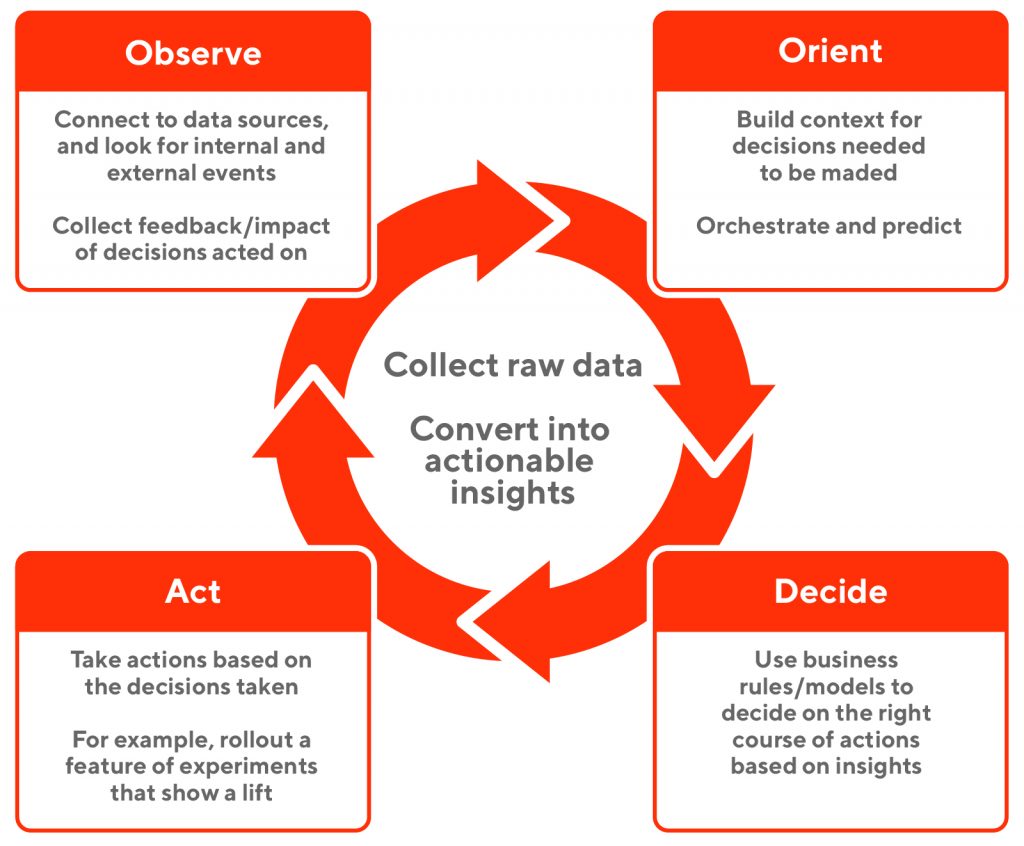
In a marketplace such as DoorDash, the speed at which we can observe growing demand trends (from our customers via orders placed), the better we can station all the measures needed to meet that demand. Another example could be about the amount of time it will take to launch experiments, understand the results (success or failure), and roll out successful features.
A growing data organization always strives to provide the right solutions to help the growing needs as described in the data needs pyramid. It also aims to provide all the solutions needed to execute on the OODA loop as speedily as possible.
Providing these solutions comes with challenges. The next section describes some of the challenges that we addressed as DoorDash grew.
The challenges of a rapidly changing and growing data organization
As shown in the data needs pyramid, DoorDash’s needs began growing, and with that came a few challenges we had to navigate.
- Focus and prioritization: figuring out the right things to build with limited resources
- Scale and complexity: managing data on a massive scale and for a wide variety of users with different skill sets
- Controlling costs: storage, compute, vendors, and licensing costs add up and need to be managed
- Audience and adoption: knowing who we are building the solutions for and ensuring data and models can be trusted
- Establishing a platform strategy and roadmap: understanding the immediate and long-term data needs of the company
- Hiring and retaining the right team: strategies for hiring engineers with the skill sets required to implement the solutions
Let's go through some of these challenges in detail.
Focus and prioritization: figuring out the right things to build with limited resources
A data organization within a growing company is always going to be under constant pressure to work on multiple projects. As is typical in the industry, the product organizations usually have higher visibility in terms of important product and business needs that translate into data requirements. If we are not proactive in anticipating the needs of our internal customers, we will always be caught scrambling and likely succumb to the pressure of providing many one-off, ill-designed solutions that later turns into a technical debt or failure waiting to happen.
This is why defining the charter of the data platform organization and its responsibilities are paramount. Once defined, it becomes easier to focus and prioritize. The pressing needs and request for help will never go away—our goal is to have a clear vision of what to tackle first.
It's important to practice the art of saying “no”. Always ask the right questions. See the “Lessons learned” section on some tips on how to overcome prioritization challenges.
Scale and complexity: from terabytes to petabytes and beyond!
Big Data is about volume, variety, and velocity. Data organizations describe these attributes in terms of millions and billions of messages processed per day or terabytes and petabytes of storage in their data storage solutions. Other indicators of large data volume and scalability are expressed in terms of thousands of ETL pipelines, thousands of metrics, and the never-ending logs and telemetry data (app and user events generated by user actions).
Scalability and the growing need for more compute and storage power are ever present challenges for any growing company. As the delivery volume grows at DoorDash, so does the amount of data that needs to be analyzed in a data warehouse.
In addition to the volume, the types of online data systems are varied. For example, in addition to Postgres, we now have online data in Apache Cassandra, ElasticSearch, and a few other data storage systems. For analytical purposes all these transactional data need to be transferred to our data warehouse via CDC pipelines. It's difficult to find a scalable, generalized CDC solution that meets every need, which adds to the overall complexity of building these pipelines.
Data collected for observability (such as event logs, metrics, and traces) is another massive contributor to any tech company’s data volume scalability challenges. The popularity of microservices architectures and the ease of launching large clusters of services have only increased the desire to measure, observe, and monitor these services.
Another typical contributor of data volume in most companies are experiments such as A/B tests of new features, that produce huge volumes of data from clickstream logs, feature impressions, and telemetry. For example, Curie, DoorDash’s experimentation analysis platform, processes billions of raw experimentation logs per day to analyze hundreds of experiments on a daily basis.
Other areas of complexity include various compliance needs, such as CCPA and GDPR, that must be satisfied depending on the market.
Cost: With increased scale and complexity, the costs increase!
With the growing scale and the need for processing, storing, and analyzing data comes the increasing costs. Increased costs come from expenses generated by the data center or cloud services, the vendor product licenses that may be part of the organization’s solutions, and from the engineers or other human resources needed to staff the team.
DoorDash uses Amazon Web Services (AWS) as our cloud vendor (for EC2 compute resources and other needs). We also use many data vendors to help address some of our data needs. Understanding the expenses of our data needs is an important part of how we can sustain and grow our organization in a cost effective manner.
Processing data and gaining insights from it has a cost, but how should a data team keep track of them? These data processing costs come in the form of compute costs from a cloud provider, vendor licensing fees or usage charges, support costs for operations, etc.
Cost models are typically different for different solutions and tools, and can be priced in ways such as per developer seat, per volume, or per container. These different models and types of costs makes the budgeting and accounting challenging.
Audience and adoption: Who are we building this for, and how can we help them?
As DoorDash grows, so have the number of teams and the various personas that need access to data and insights.
The skills that a product engineer has in terms of contributing to or consuming data is very different from that of a data analyst or a product manager. Let's take the example of experimentation. Who are the personas in an organization that define the experiments and the hypothesis? How are the experiments analyzed? Can data analysts run these experiments with the click of a button? Does it require an engineer with “Big Data” expertise to compute and analyze the results of the experiments?
With a plethora of tools, solutions, and technologies, how does the team cope with educating the users of the data ecosystem?
Platform strategies and roadmap: leveraging vs building solutions
As described earlier, data at DoorDash in its early stages focused on the most important and common of data hierarchy needs: namely, the ability to collect, load, and analyze data for business intelligence.
However, as DoorDash’s business grew, and the complexity of the data grew, we had to march up the hierarchy of data needs that included the need for faster, fresher data (near real-time), machine learning data, experiment analysis, and more.
For most companies, cloud providers such as AWS offer a lot of services and products to leverage. In addition, there are many external vendors that can also be leveraged for building out solutions for some of these needs.
The challenge, though, is that there are many solutions to any given problem.
Take for example the need for an OLAP storage solution. One could use Apache Pinot, Apache Druid, or a combination of ElasticSearch and perhaps Cassandra, just to name a few. Similarly, one could use Apache Flink, Apache Beam, Apache Spark Streaming, or a few other solutions for processing real-time events.
There is no one-size-fits-all solution in this case and each organization should devise a strategy that best fits its needs.
Hiring and retaining the right team: strategies for hiring the skill sets required to implement the solutions
As is evident, with increased scale, complexities, and various data needs, DoorDash had to invest in growing its data platform organization. Although our strategy has been to leverage and use whatever we can from cloud providers and other vendors, we still had to build out quite a few parts of the puzzle ourselves. This would require building a diverse and highly skilled team of engineers capable of rising to the many challenges that we faced.
The Big Data domain is large enough that there are now specialists focusing on particular sub-domains such as stream processing, machine learning, query optimizations, and data modeling. A simple glance at a Big Data infographic will convince you that not everyone will be an expert in every data-related subject. Hence, it becomes a challenge to ensure that the right team is built with the right skills and diversity of experience.
Lessons learned while addressing these challenges
Given the challenges described above, how did we navigate these challenges at DoorDash? Here are some tips that helped our organization and can be utilized to help other growing data-driven companies:

Let’s go a bit deeper into each of these.
Build audience personas and cater to their specific needs
A data platform is a product. It's always best to use the same principles as one would while building a product that will be used inside or outside the company.
A typical data platform organization caters to the following personas and skills:
- Product/functional engineers
- Product managers
- Business intelligence/data analysts
- Data scientists
These personas cover a wide range of skill sets and it's critical to make sure that they can be productive using the solutions provided by the data platform. For example, many data scientists tend to prefer using R or Python compared to working with Scala and Java. If the batch processing solution that is offered is a Scala-based Spark platform, then data scientists would likely be less productive building solutions using this service.
The second consideration when approaching a target audience is designing the service interfaces. Is it worth investing in a well-designed user interface (i.e. internal data tools/consoles) for operations that are regularly carried out by non-engineers? Or does using solutions require the use of YAML/Kubernetes and the mastery of Git commands?
These are important factors to consider when building out the solutions offered by a data platform.
At DoorDash, our initial team was very technical, but as we grew and the number of users who are not coders increased, we had to invest more in simpler user interfaces to increase productivity and usability.
Another audience are the stakeholders and sponsors of a business unit. The best way to move forward is to ensure a strawman proposal is sent out, feedback obtained, iterated on, and a minimum viable product (MVP) lined up before more investment is lined up.
Define the charter and build a logical framework for approaching typical problems
The key to addressing the ever-increasing business demands is to define the surface area, or the challenges the platform organization will address.
At DoorDash, the data platform is essentially responsible for all post processing and the OODA loop that helps compute, infer, feed-back, and influence the online operations as efficiently, speedily, and reliably as possible.
Once the charter or the focus area (aka surface area) is defined, it becomes easier to know what challenges to focus on.
Ask the right set of questions while prioritizing what needs to be built. A sample set of such questions are:
- Is this solution meant for products that drive revenue vs products that are experimental? (tighter SLA, higher priority vs not)
- Can the data that is collected be used by multiple teams/use cases?
- What quality and SLA of data do they desire?
- How often will they use this data? What happens if this data is unavailable for a time period?
- Is the data to be consumed by a program or by humans?
- How will the volume grow?
Once we gather answers to these questions, we can then analyze the right solution to be built.
When to build point solutions vs generalized platforms
Know when to build one-off solutions (aka point solutions) and when to invest in generalized solutions. It's usually best to build specific solutions, iterate, learn, and only then generalize.
Often a functional or product team requests some ability/feature to be developed and made available. While very tempting to offer a solution assuming that it falls within the focus area of the organization’s charter, it still is important to know if this is a one-off request that needs a point solution or a generally applicable use case that requires a broader, generalized solution.
DoorDash invested in a point solution for some early use cases, such as predicting ETAs (estimated time of arrival for deliveries). While it was intuitive that there will be many more machine learning models that would need to be built at DoorDash, we still took the path of first building a point solution. Only once that was successful and there was an increased demand from various teams that wanted to use ML solutions did we invest in building out an ML platform as a generalized solution.
We now continue to iterate on this ML platform by building a general purpose prediction service supporting different types of ML algorithms, feature engineering, etc.
Define a Paved Path
Often, the answer to whether a point solution should be built by the data platform team should really be “no”. If the solution cannot be generalized and adopted by a wider audience, it's best to leave it to the specific team that needs the solution to own and build it themselves.
The challenge to look out for here is future fragmentation (i.e multiple one-off solutions built by different teams).
For example, while only one team needs a certain solution at the moment, they may choose to build it themselves using, say, Apache Samza. Soon enough another team embarks on another use case, this time using Spark Streaming. This continues over a period of time until the company is left with multiple solutions that then need to be supported. This can be a drain on an organisation and is ultimately inefficient.
Hence, it's best to work with teams that need a point solution since it gives awareness to any new use cases and allows the data team to guide other teams towards the Paved Path. What do we mean by a Paved Path?
It's simply the supported, frequently treaded path established by the first few teams that worked together in a certain area.
In order to help ensure innovation and speed, functional product teams should be able to build their own solutions. However, this development should be done with the knowledge that being outside of the Paved Path will make any team responsible for their own support and migration going forward. If the separate solution built by the functional team gains success, we can then work together to make it part of the Paved Path.
Build versus buy
The Big Data landscape has grown tremendously. There are many available vendors and product solutions.
Often many companies fall into the trap of not-invented-here-syndrome. They often cite some feature currently not available in a given third party solution and choose to build the solution themselves. While there are many good reasons to build something in-house, it's a weighty decision that should be considered more carefully.
As leaders at AWS coined the term “undifferentiated heavy lifting”, it's important to focus on what is critical, germane, and important for the business and build that in-house and simply leverage whatever else is available. Using various open source technologies is a good start, but sometimes, it does make sense to go with an external vendor.
How to decide which route to take?
Consider these questions to figure out the best course of action:
- Is there a strategic value in the solution that’s tied to the main business?
- Is the vendor’s solution cost effective? Given the growing needs of our organization, how does the cost scale?
- What are the operational characteristics of the solution? (For example, it’s not easy to operate an HDFS environment or a very large set of Kafka clusters reliably, even if done in-house it comes with a cost.)
- Does the solution need a lot of integration with internal systems? Often it's harder to integrate external vendor solutions.
- Are there any security or compliance requirements that need to be addressed?
Once we have answers to similar questions, it's a lot easier to choose the best path forward.
At DoorDash we have crafted a cost-effective solution with a mix of cloud, vendor, and in-house built solutions. Most in-house solutions utilize multiple open source technologies woven together. For example, our ML Model Training solution relies on PyTorch. Building a solution in-house makes sense if it's cost-effective and can bring in efficiencies.
Prioritize trust in data or your impact will be minimal
Focus on reliability, quality, and SLAs
Reliability and uptime are very important for most services. However, when it comes to analytical/data solution services, some characteristics are different from typical online systems.
For example, in most offline analytical cases we should strive for consistency of data rather than availability, as discussed in the CAP theorem.
It's important to detect/monitor the quality of data and catch problems as early as possible. When microservices go down there are methods, such as blue/green deployments or cached values, that can restore the functionality provided or reduce the impact of the outage. At the very least a rollback to the previous best version can come to the rescue.
For large data processing pipelines these techniques do not apply. Backfilling data is very expensive and recovery usually takes a longer time.
The lesson we learned here is to focus on data quality, understand the failure modes of the solutions stationed, and to invest in monitoring tools to catch errors as early as possible.
Trust in data is essential to the usefulness of the data. If people suspect the quality is faulty, that will likely translate downstream to lack of trust in the models and analytics the data produces. Therefore if this trust is not maintained the data team cannot be effective.
Be obsessed with your internal customer
There is an adage in the product world or any business that states, “Always treat your customers as royals”. The same lesson applies to how internal customers should be treated. Just because the internal customers are forced to use internal services does not mean they should not be treated like an external customer.
If there has been a breach of SLA, a data corruption, or missing data, it's important to share this information as early and as clearly as possible with stakeholders and the user base. This ensures that we keep their trust and demonstrate that we believe their data is important to us and we will do our best to recover any data lost.
Define the team’s North Star, measure and share the progress
Setting a North Star
We strive to set forward-looking and ambitious goals. For example, the North Star goal for Curie, our experiment analysis platform, is to be able to perform a certain number of analysis per month by the end of the fourth quarter in 2020.
Measure what matters!
John Doer wrote a book titled, Measure What Matters, about setting objectives and key results (OKRs). In the case of a data organization, the same principle applies.
At DoorDash, we measure various metrics, such as reliability, quality, adoption, and business impact. As Ryan Sokol, our head of engineering reminds us, “You can’t fix what you can’t measure”.
Share the progress
It's also important that we share our North Star and our metrics on a regular cadence with our stakeholders and user community. Sharing the progress in terms of new features available for use in a regular manner via newsletters or tech talks increases visibility of the direction in which the roadmap is headed and allows our user base to influence the roadmap.
Launch early and iterate in collaboration with the user base
This is a well accepted learning in any consumer based product — especially the internet or app-based ones. Rather than building a product with all the bells and whistles and having a big reveal/launch, most companies prefer to build a minimum viable product and iterate from there. The same tip holds for internal platform organizations.
As described in the Point solutions vs generalized platform section above, it is usually best to work on a point solution for a hero use case (i.e. a high impact, highly sought after need) along with the product team that can adopt this solution. This ensures that the teams who will use this product have skin in the game and multiple teams can collaborate on a solution. In addition to this, the learnings while building this joint solution will then be available as a general offering for all the other teams that want to adopt the solution in the future.
For example, at DoorDash, the Data Platform team partnered with the Logistics team to build a real-time feature engineering pipeline for a few logistics ML use cases, as those described in the article Supercharging DoorDash’s Marketplace Decision-Making with Real-Time Knowledge. Once this was successfully launched and other teams wanted to use real-time features, we then embarked on a new project to generalize the feature engineering pipeline for ML.
Build a healthy data organization by hiring and nurturing the right talent
None of the challenges described can be built without a well-functioning team of passionate, skilled engineers. The data field can be very unforgiving. Oftentimes, some teams drown in operational and support tasks and can barely keep up with the growing needs of the company.
Grow the team organically and with the right skills
Growing the team to address the growing needs of the company is critical. At DoorDash, we ensured we first hired the right senior engineers and leaders — i.e. engineers who have gained valuable experience in the industry — to set the seed and build the foundation for the rest of the team as it grows.
It was valuable to initially hire engineers that can help architect the big picture. Someone who is hands on and can work on fast iterative solutions. Once a foundation is built, it's good to invest in specialists in certain areas. For example, we started with engineers that could build simple A/B tests, and as the needs of the organization grew, we invested in hiring data scientists and engineers with specialization in various experimentation methodologies.
Diversity in terms of gender, race, thoughts, culture, and, of course, skill sets and experience is also important for a growing organization.
Enable the growth and success of the team
It's one thing to hire and grow an organization, but it's also important to keep the existing team productive and happy. It's important to ensure that the team members are exposed to interesting challenges and have the freedom to experiment with and contribute to the growing needs of the company.
As a growing company DoorDash has many interesting challenges, and a supportive organization that invests in the continuing education and well-being of its employees. We achieve this via various internal and external programs such as mentoring, learning sessions, attending conferences, and sharing knowledge in various tech talks and forums.
We typically measure the growth and happiness of the team using NPS scores and internal surveys to understand areas of improvement.
Never stop learning and adapting to progress innovation
All said and done challenges never end and we must continue to learn. The Big Data ecosystem is always changing and evolving. MapReduce was the latest craze about eight years ago. It is no longer the darling of the distributed computing world. Lambda architectures are giving way to Kappa architectures in the data processing arena. The infographic of product offerings in the data platform field continues to grow complex and is forever changing.
A healthy organization has to be able to discard old ideas and usher in new ones, but do so responsibly and efficiently. As anyone who has ever led large migration efforts can attest, adopting and deploying new ideas is not something that can be done easily.
At DoorDash we have adapted. We continue to learn and iterate over our solutions, but we aim to do so responsibly!
Conclusion
A data platform team is a living organization — it evolves and learns via trial and error. At DoorDash, we have evolved and learned our lessons through the challenges that we encountered.
DoorDash continues to grow, and we are in many ways still getting started. For example, there is still a lot to accomplish in terms of developer efficiency so that our data analysts and data scientists can obtain the insights they want to gather via real-time data exploration. Our ML models can benefit greatly from the use of real-time features. Our experimentation platform aims to not just run A/B tests reliably and smoothly, but indeed make headway in terms of learning from the experiments already launched and tested via deep statistical and behavioral insights.
If you are passionate about building highly scalable and reliable data solutions as a platform engineer and enabling products that impact the lives of millions of merchants, Dashers, and customers in a positive way, do consider joining us.
I hope that these challenges resonate and would love to know how you have navigated similar challenges in your organization. Please leave me a comment or reach out via LinkedIn.
Acknowledgments
As the saying goes, it takes a village to raise a child. Building and nurturing a data organization is similar - it takes a lot of help, guidance, support and encouragement. I wish to acknowledge the following folks for laying the foundation: Jessica Lachs, Rohan Chopra, Akshat Nair, and Brian Lu. And many others that support and collaborate with the data platform team, including Alok Gupta, Marta Vochenko, Rusty Burchfield, and of course the Infrastructure organization via Matan Amir, who makes it possible to run cost-effective and well supported data solutions.
Header photo by JESHOOTS.COM on Unsplash