

The challenge of building machine learning (ML)-powered applications is running inferences on large volumes of data and returning a prediction over the network within milliseconds, which can’t be done without minimizing network overheads.
Category Archives: AI & ML
Meet Sibyl – DoorDash’s New Prediction Service – Learn about its Ideation, Implementation and Rollout

As companies utilize data to optimize and personalize customer experiences, it becomes increasingly important to implement services that can run machine learning models on massive amounts of data to quickly generate large-scale predictions.
Improving Experimental Power through Control Using Predictions as Covariate (CUPAC)
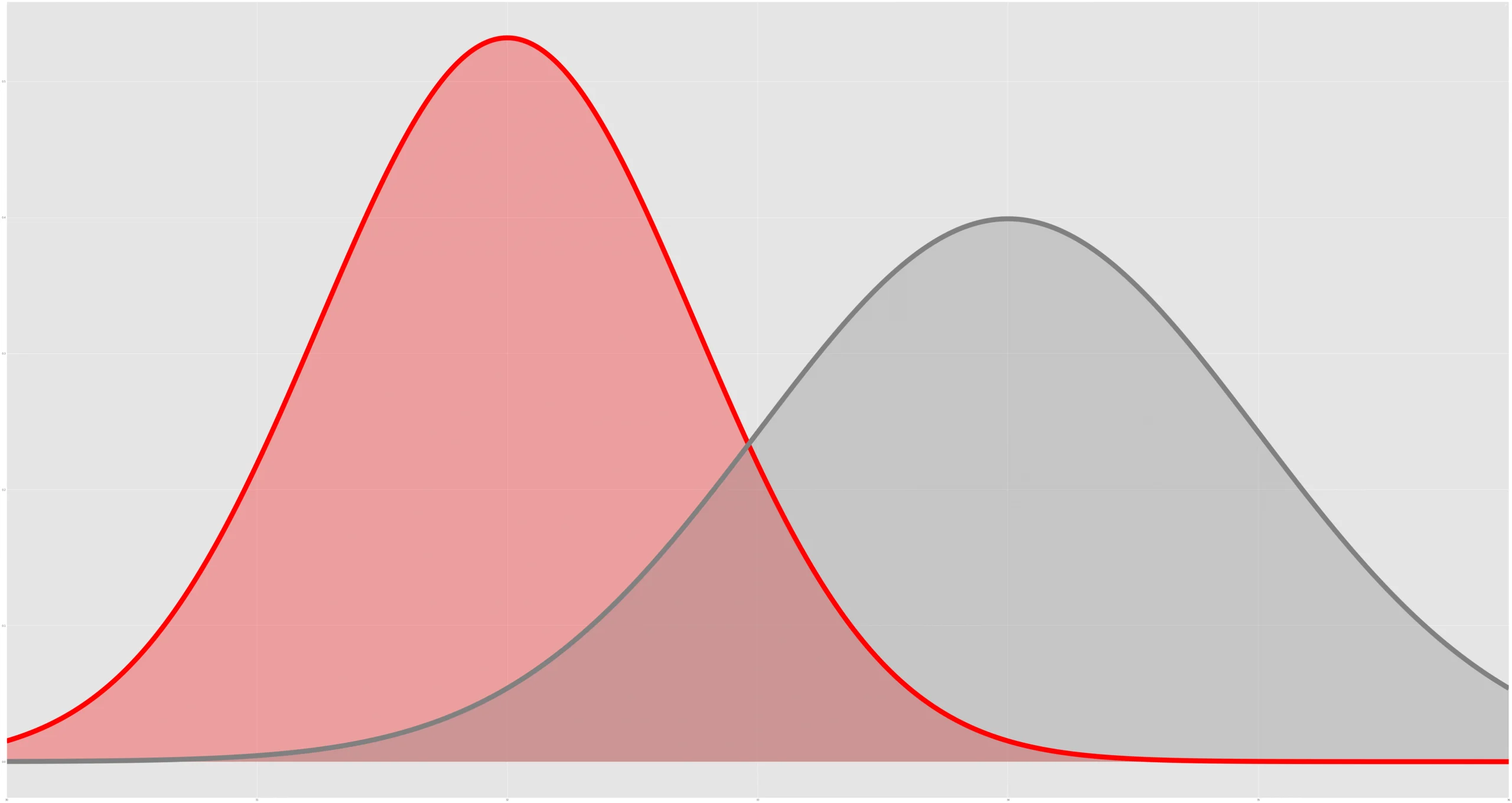
In this post, we introduce a method we call CUPAC (Control Using Predictions As Covariates) that we successfully deployed to reduce extraneous noise in online controlled experiments, thereby accelerating our experimental velocity. 
Rapid experimentation is essential to helping DoorDash push key performance metrics forward.
DoorDash’s ML Platform – The Beginning

DoorDash uses Machine Learning (ML) at various places like inputs to Dasher Assignment Optimization, balancing Supply & Demand, Fraud prediction, Search Ranking, Menu classification, Recommendations etc.
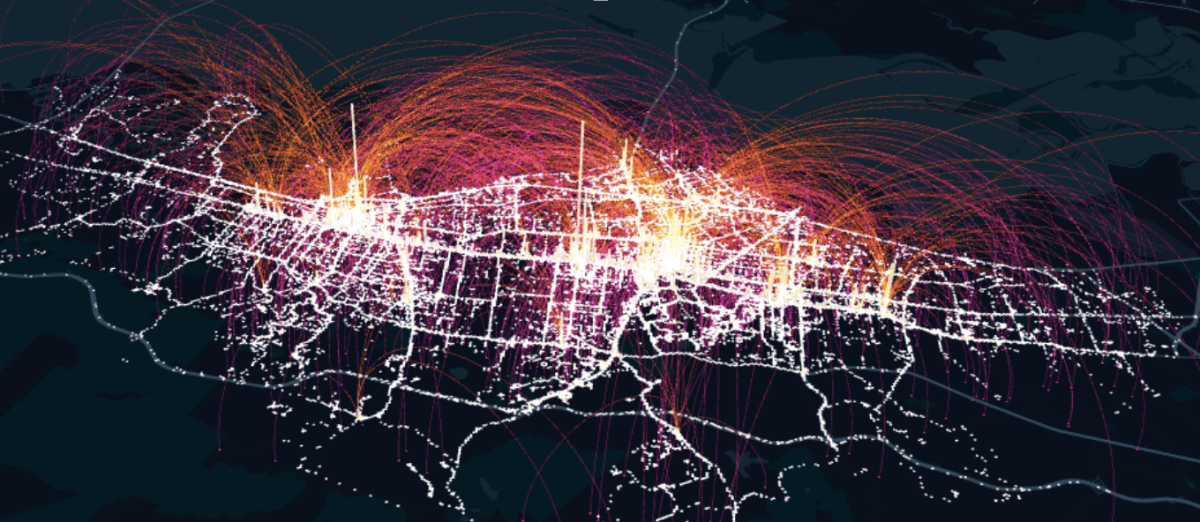
Supercharging DoorDash’s Marketplace Decision-Making with Real-Time Knowledge

DoorDash is a dynamic logistics marketplace that serves three groups of customers:
Merchant partners who prepare food or other deliverables,
Dashers who carry the deliverables to their destinations, 
Consumers who savor a freshly prepared meal from a local restaurant or a bag of groceries from their local grocery store. 
For such a real-time platform as DoorDash, just-in-time insights from data generated on-the-fly by the participants of the marketplace is inherently useful to making better decisions for all of our customers.
Next-Generation Optimization for Dasher Dispatch at DoorDash

At DoorDash, our logistics team focuses on efficiently fulfilling high quality deliveries.
Organizing Machine Learning: Every Flavor Welcome!

DoorDash’s principles and processes for democratizing Machine Learning
Six months ago I joined DoorDash as their first Head of Data Science and Machine Learning.
Personalized Cuisine Filter

The consumer shopping experience is a key focus area at DoorDash.
Analyzing Switchback Experiments by Cluster Robust Standard Error to Prevent False Positive Results

Within the dispatch team of DoorDash, we are making decisions and iterations every day ranging from business strategies, products, machine learning algorithms, to optimizations.
Experiment Rigor for Switchback Experiment Analysis
At DoorDash, we believe in learning from our marketplace of Consumers, Dashers, and Merchants and thus rely heavily on experimentation to make the data-driven product and business decisions.