

At DoorDash, our logistics team focuses on efficiently fulfilling high quality deliveries. Our dasher dispatch system is a part of our logistics platform that has substantial impact on both our efficiency and quality. Through optimal matching of dashers to deliveries, we are able to ensure dashers get more done in less time, consumers receive their orders quickly, and merchants have a reliable partner to help them grow their businesses. In this blog post, we will explore:
- The background of the dispatch system
- Our prior and current optimization approaches and how we wanted to re-frame them
- Modifying a tier-zero service with zero downtime
- Future work to build on top of our optimizer
Background
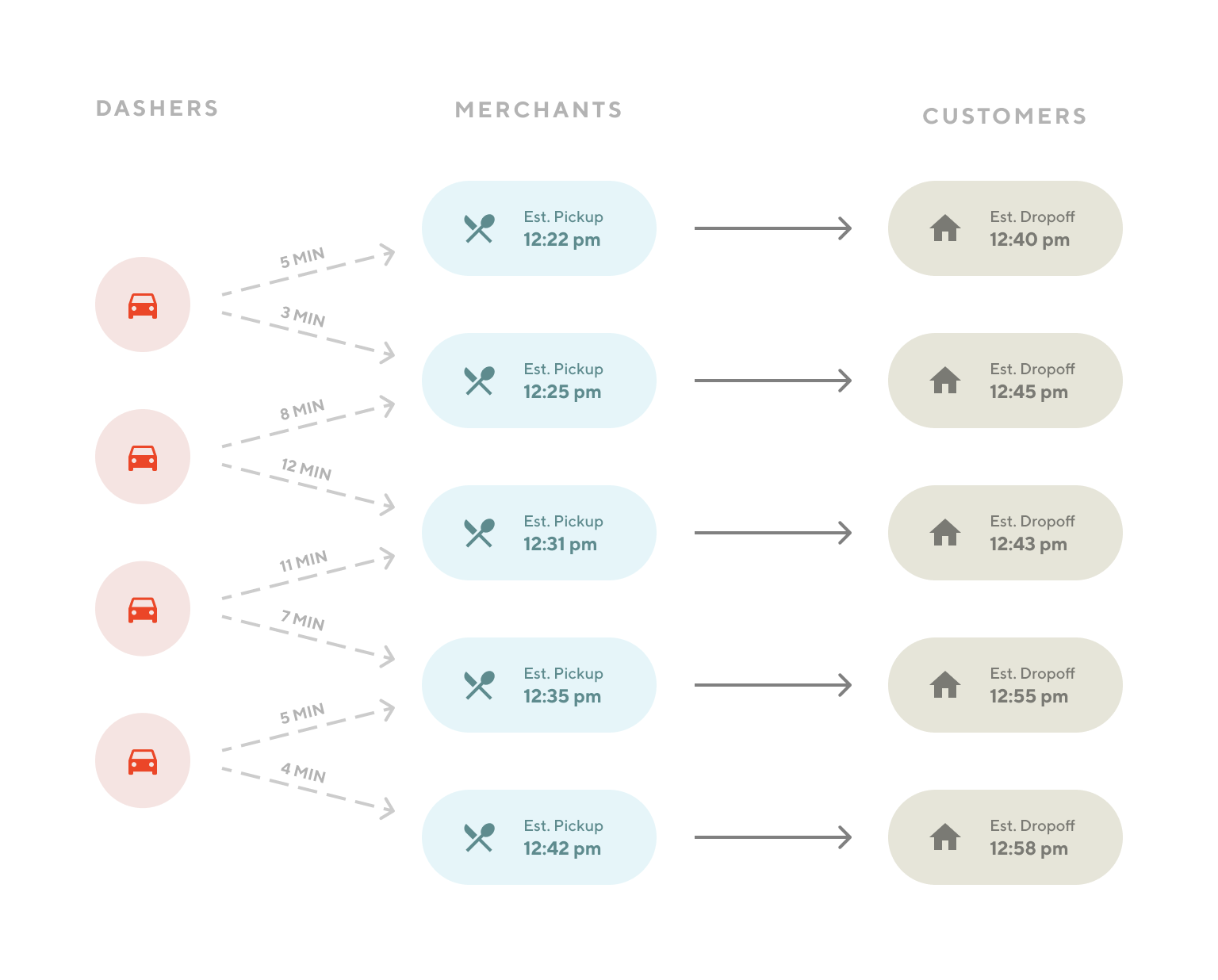
DoorDash powers an on-demand marketplace involving real-time order demand and dasher supply. Consumers ask for goods to be delivered from a merchant to their location. To fulfill this demand, we present dashers with delivery routes, where they move between picking up orders at merchants and delivering them to consumers.

Our dispatch system seeks high dasher efficiency and fulfillment quality by considering driving distance, time waiting for an order to be ready, delivery times as seen by the consumer, and more. Given incomplete information about the world, the system generates many predictions, such as when we expect an order to be ready for pickup, to model the real-world scenarios. With this data, the dispatch system generates future states for every possible matching and decides the best action to take, given our objectives of efficiency and quality.
Optimization
With the current statuses of available dashers in the network (such as waiting to receive an order, busy delivering an order), and information of all outstanding consumer orders, we need to generate possible routes for each order, and choose the best route to assign in real-time. Our prior dispatch system assigned one delivery to a route at a time, so we framed it as a bipartite matching problem. The problem can then be solved using the Hungarian algorithm. There are two limitations with this approach: 1) though the Hungarian algorithm is polynomial, the runtime of large instances is excessive for our real-time dynamic system; 2) it doesn’t support more complicated routes with 2 or more deliveries.
Formulating the problem as a mixed-integer program (MIP) and solving it with a commercial solver can address both issues. First, we find that commercial solvers like Gurobi are up to 10 times faster at solving the matching problem than the Hungarian algorithm. This performance enhancement enables us to solve larger problems, based on which we can refine our models to drive business metrics. Furthermore, the solver provides flexibility in formulating the problem as a vehicle routing problem, which allows multiple deliveries in a route.
Stay Informed with Weekly Updates
Subscribe to our Engineering blog to get regular updates on all the coolest projects our team is working on
Please enter a valid email address.
Thank you for Subscribing!
As for the mathematical formation of the problem, binary variables are used to represent dasher-to-order matching decisions. The objective function is formulated to optimize both delivery speed and dasher efficiency, which are represented by the score coefficients in the model. There are two sets of constraints used to define dasher availability and routing preferences. The optimizer is run on several instances distributed based on regional boundaries multiple times a minute.
Notation

Formulation

Optimization solvers
There are multiple choices of optimization solvers that we could use to solve our problem. We experimented with the open source solver CBC, and commercial solvers including XPress, CPLEX, and Gurobi. We ultimately decided to license the Cloud service offer from Gurobi for our production system. The decision was based on the speed (benchmarks on our particular problems indicates that Gurobi is 34 times faster on average than CBC) and scalability of the solvers, ease of abstracting feasible solutions when optimality is hard, ability to tune for different formations, relatively easy API integration to Python and Scala, flexibility of the prototype and deployment licensing terms from the vendors, and professional support.
Implementation
Since dispatching a dasher for an order is an essential component of our delivery product, switching over to the new optimization solution had to be done with zero downtime and no impact on the fulfillment quality. Typically, we run experiments for new functionality and measure the impact on quality metrics, but since optimization is such a fundamental part of the algorithm, an experiment is both higher risk and not granular enough to understand the change at the lowest level of detail. Fortunately, an initiative to refactor our codebase had finished up around the same time. One of the changes was to move the optimization code into a separate component behind an extensible interface, so we tried a different approach.
Instead of running an experiment, we implemented the MIP logic as another optimizer behind the existing interface, along with code to convert the standard optimizer parameters into MIP solver inputs. We then built a third optimizer that combined the other two and compared the outputs of each. The combined optimizer would return the original optimizer’s results, throwing out those of the MIP optimizer, and then generate logs listing the differences between the two solutions and which was better. With this data we found that the two optimizers’ output matched more than 99% of the time, and the only mismatches were due to situations where there were multiple equally-good solutions. This gave us the confidence to adopt the new optimizer without further testing and resulted in a seamless transition.

Results and future work
After deploying the MIP formulation, we can now solve more flexible and complex models faster. Combined with our experiment framework, we can iterate on our models at a much faster pace. We are exploring various improvements to the model and our dispatch system.
The first is that we can simply solve a bigger problem. Since the MIP optimizer is up to 10 times faster, we can solve the matching problem for a larger region in the same amount of time. This has the advantage of being simpler, as we have fewer regions to process, but also is more optimal. With a larger problem size, we increase the number of tradeoffs the optimizer considers and reduce edge effects caused by the boundaries between regions, leading to higher-quality decisions.
Another feature the new formulation has enabled is offering multiple deliveries at a time in more complicated routes, as mentioned before. This was a limitation of the Hungarian algorithm, but the flexibility of MIP allows us to consider those routes, and the formulation’s constraints ensure we still correctly match every delivery. Matching these more complex routes helps us give additional, and more desirable deliveries to dashers, and also paves the way for building out new types of products.
Finally, we’re working on even more complex formulations that combine historical data and future predictions to consider the state of the world over time. There are often cases where it is better to wait to offer a delivery instead of doing so right away. With the MIP formulation, we can build these kinds of tradeoff considerations directly into the model and amplify the efficiency and quality of the system.
Success factors and lessons learned
It is vital that the model we built can closely represent the business problem at hand, which requires an accurate understanding of the business logic and flow. The coefficients in the objective functions also need to be accurately predicted in order for the model to truly provide optimized results for our business. We were able to achieve this by working closely with our machine learning models to provide accurate predictions.
Another factor that helped us make a project like this successful is the close interaction between our data scientists and software engineers. Having a deeper understanding of the codebase that the model is built on top of was a huge benefit for the successful deployment of the method we chose.
Lastly, we need our company's management team’s alignment since a project that involves a new data science method requires a longer-term strategic vision for it to be successful. These projects generally need a longer than regular feature development cycle for their fruition. Luckily, at DoorDash, our management team bought into investing in short-term as well as long-term bets.
Conclusion
We have seen the role optimization plays in ensuring every delivery at DoorDash is high quality, and fulfilled efficiently. We discussed the motivations for re-framing optimization from the matching problem to a MIP formulation, and how we surgically performed the swap. With our new optimization method in place, we highlighted several new improvement areas we unlocked as well as where we’re looking towards for the future.
If you are interested in real-time algorithms at the intersection of engineering, machine learning, and operations research, reach out! We are hiring for roles on the dispatch team. Visit our careers page to learn more: https://www.doordash.com/careers
And, a very special thanks to Richard Hwang for your contributions and guidance on this project.