

At DoorDash, experimentation is foundational to product iteration and improvement. However, traditional A/B testing — our established method — often creates significant roadblocks even though speed and scale are paramount.
In a traditional A/B test, the sample size must be pre-determined, and the traffic allocation -- the proportion of users seeing each variant, or arm — also is determined in advance, remaining fixed throughout the experiment period. This fixed-horizon design requires the experimenter to tolerate the opportunity cost, or regret, of serving traffic to suboptimal variants until the planned end date, even if one arm is clearly outperforming the others early on.
This system creates two main bottlenecks:
- Slower experimentation: We must wait until the fixed sample size is reached to declare a winner and quantify the impact. If a treatment arm shows early promise, traffic cannot immediately be sent to the winning arm, forcing experimenters to live with the opportunity cost.
- More expensive experimentation: Testing numerous ideas quickly becomes economically prohibitive. For teams with a long list of ideas, such as those tuning parameters in a machine learning model, waiting for the completion of fixed A/B tests can be tedious and time-consuming.
Experimenters ideally want an early signal, preferably automated, about whether a treatment arm has a low chance of success. Multi-armed bandits (MAB) can address these constraints by dynamically optimizing traffic allocation toward superior variants based on continuous feedback.
How MAB works to address experimentation speed
The MAB approach addresses problems where decision makers iteratively select one of multiple fixed choices when the properties of each choice are only partially known and may become better understood as time passes. For our purposes, this strategy allocates experimental traffic toward better-performing variants based on ongoing feedback collected during the experiment. The core idea is that an automated MAB agent continuously selects from a pool of actions, or arms, to maximize a defined reward, while simultaneously learning from user feedback in subsequent iterations.
A key aspect of an MAB is managing the exploration-exploitation trade-off.
- Exploitation involves choosing actions that currently appear to have the highest reward, maximizing immediate gains.
- Exploration involves choosing actions with unknown or potentially lower current rewards to gather more data, risking higher short-term regret, but creating the potential to discover superior long-term options.
The MAB agent uses a policy, or strategy, to strike this balance, becoming smarter over time as it maximizes rewards.
Because MAB continuously directs more traffic to arms showing high value while restricting traffic to arms showing lower value, as illustrated in Figure 1, it minimizes regrets. MAB accelerates learning speed, surfacing insights immediately, rather than waiting until the fixed duration experiment ends.

MAB’s ability to dynamically allocate traffic supports several experimentation goals that A/B testing cannot:
- Continuous recommendations, minimizing regret: MAB’s process constantly adapts and automatically tunes parameters, promotions, or configurations to reduce opportunity cost.
- Cost reduction: By dynamically diverting traffic away from poorly performing arms early in its process, MAB minimizes overall testing costs.
- Idea narrowing: MAB can assess many ideas quickly, narrowing down to only the most promising arms. Testing only on this much smaller subset dramatically speeds the overall experimentation process.
MAB platform infrastructure: The automated feedback loop
DoorDash’s MAB platform abstracts away the complexity of algorithm implementation and data piping, integrating its analysis seamlessly with existing systems.
As shown in Figure 2, the MAB system is composed of several core integrated components that handle configuration, computation, and allocation. Among the important definitions are:
- MAB configuration, or user interface: Where experimental parameters and the required reward function are defined.
- Reward worker: The offline compute engine where the MAB algorithm resides and calculates optimal traffic distribution.
- MAB service: Stores configurations, reward distributions, and serves the latest arm allocation results to downstream applications.
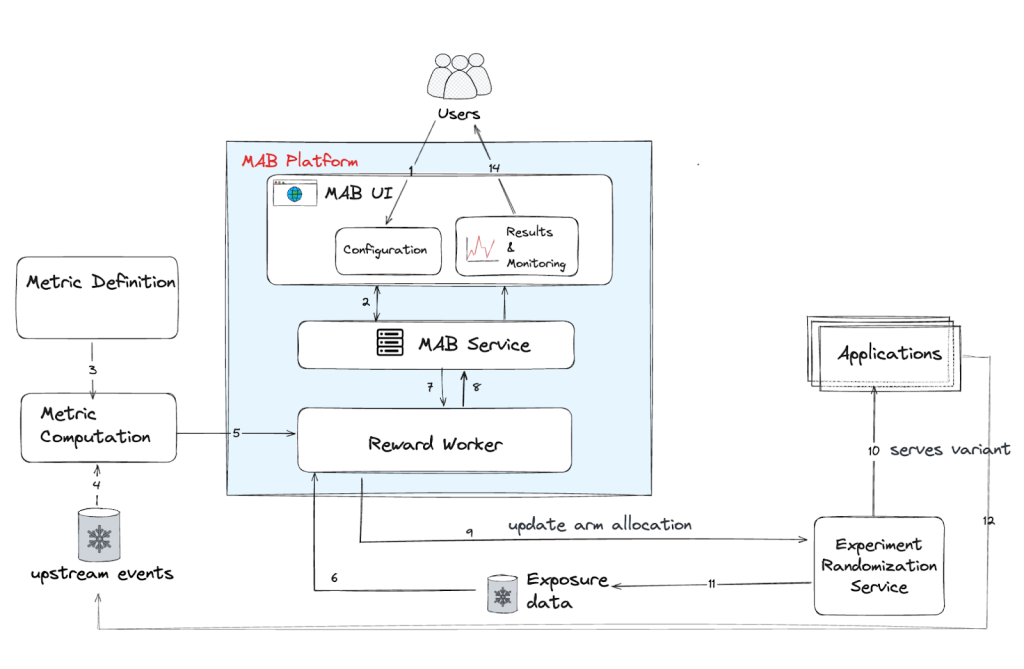
Reward worker: The core compute engine
The core decision cycle is powered by the reward worker, which runs on a batch compute schedule — typically daily — matching the cadence of the upstream metric computation pipeline.
The Thompson sampling algorithm, the industry’s most popular choice, powers DoorDash’s MAB platform. In the paper, “An Empirical Evaluation of Thompson Sampling,” this Bayesian algorithm has been proven to be asymptotically optimal, achieving smaller regret compared to alternatives like the upper confidence bound algorithm. Furthermore, according to the research paper, “A Batched Multi-Armed Bandit Approach to News Headline Testing,” Thompson sampling demonstrates greater robustness to delayed feedback introduced by batch reward computation, a common challenge in real-world systems.
Thompson sampling operates via Bayesian inference as follows:
- Priors: It maintains a probability distribution of the expected reward for each arm. For instance, the system uses a beta distribution to model expected reward for binomial metrics, and normal distribution for normal metrics.
- Sampling: In each decision cycle, a value is sampled from the posterior distribution of each arm's reward, ultimately selecting the arm with the largest sampled reward.
- Update: After receiving new data in the form of user feedback, it updates the arm’s distribution using the posterior hyperparameter formula derived from conjugate priors. As more data is collected, knowledge about each arm's reward distribution becomes increasingly accurate
This worker executes two main technical responsibilities to complete the feedback loop:
- Reward computation, or Bayesian update: This step collects metric data. If optimizing for multiple objectives, these metrics are scalarized into a single reward function. It then applies Bayesian inference rules, combining the prior distribution with the new observational data to compute the new posterior distribution parameters for each arm.
- Arm allocation computation, or sampling: Utilizing the latest posterior distributions, the worker simulates multiple scenarios to determine the probability of each arm being the best, which becomes the MAB-recommended traffic allocation.
The treatment effect versus metric value
A critical improvement we made to the algorithm involved switching from modeling the distribution of the metric value to modeling the treatment effect. Initially, the approach involved modeling the posterior distribution based on the absolute metric values that composed the reward function. However, early testing revealed this method was susceptible to false inferences caused by Simpson’s paradox. When the overall environment was non-stationary and metric values shifted — for example, when rewards were generally lower in a subsequent testing period — arms with minimal exposure in the later period had their cumulative mean heavily weighted toward the more favorable earlier period. This scenario led to counterintuitive results, suggesting poor-performing arms were superior, and creating discrepancies between the MAB's allocation recommendations and the outcomes observed in parallel traditional A/B testing.
To mitigate these statistical biases and ensure robust decision-making, a significant methodological improvement was implemented: The system shifted to maintain priors on the treatment effect of each arm relative to a control arm, rather than focusing on the absolute metric values themselves. This crucial change addresses the problem by focusing on within-period comparisons before aggregation across time, removing the non-stationary bias. By updating the posterior distribution based on the incremental treatment effect, the optimization directly targets the lift or impact that the treatment is intended to generate. We fundamentally aim to optimize for this in our experimentation — the difference in performance caused by the new variant — which then leads to unbiased estimations that consistently match rigorous experimentation criteria
Stay Informed with Weekly Updates
Subscribe to our Engineering blog to get regular updates on all the coolest projects our team is working on
Please enter a valid email address.
Thank you for Subscribing!
Challenges faced
Integrating MABs presented challenges related to statistical rigor, algorithmic fit, and aligning results with traditional shipping protocols, including:
- Inference difficulty: Unlike traditional A/B tests, in which any metric can be analyzed post-experiment, MAB makes it much harder to craft inferences on metrics that are not included in the reward function. The platform would need additional infrastructure to support measuring metrics that are not included in the reward function.
- Inconsistent user experience: In many MAB implementations, the goal is to continuously maximize reward, which can mean users may see inconsistent experiences or switch buckets upon repeated visits. This could lead to unpleasant user experiences. Addressing this challenge in adaptive experiments requires optimizing only on the new traffic to the experiment while keeping existing users in the experiment unchanged.
- Complex reward functions: Teams often use intricate reward functions that incorporate multiple correlated metrics. Addressing such scenarios within Bayesian inference necessitates more sophisticated modeling, particularly involving joint distributions.
- Modeling continuous action spaces: The Thompson sampling algorithm requires a discrete action space. This posed a problem when we attempted to tune continuous parameters, which forced experiment owners to guess a limited set of discrete arm values manually. This design choice limited the platform’s ability to learn about the full continuous action space because information could not be shared across discrete variants. This limitation, combined with the lack of contextual information, restricted the potential impact.
To address these limitations, our future plans include expanding algorithmic capabilities to pursue more complex use cases, such as contextual bandits and Bayesian optimization to handle continuous action spaces. We also plan to explore sticky assignment solutions to allow consistent user experiences while evolving the decision-making framework for adaptive experiments.
