

For complex systems such as the DoorDash assignment system, simulating the impact of algorithmic changes is often faster and less costly than experimenting on features live in production. However, building a simulator capable of capturing a complex system is a challenge in itself. Simulation feasibility should be assessed based on the predictability of the underlying dynamics that are being modeled. Considerations should be made about how simulator usage will be integrated into team development practices and the business impact should be evaluated with simulation as part of the development cycle. The technical design should focus on reusing existing infrastructure and minimizing simulation-specific behaviors in production systems. Finally, smart development and avoiding premature optimization can dramatically improve the ROI and time-to-business value when building a simulation platform.
When embarking on a simulation project, it’s important to keep in mind the following four steps that DoorDash took when we went about building ours.
1) Assess simulation model feasibility
Before embarking on a simulation project, it is important to consider whether it’s possible to accurately simulate the dynamics that are critical for the outcomes that need to be measured. Generally, the more deterministic a system is, the easier it will be to simulate.
Simulation provides particular value where the aggregate behavior may be difficult to predict, but individual components of the system are reliably predictable. Physics is a great example of predictable behavior, where atomic level interactions are well described, but how they will propagate across a larger system is less predictable.
For DoorDash, we have invested heavily in understanding individual Dasher behaviors; Dashers is what we call our delivery drivers. We collect large amounts of data about the factors influencing Dasher acceptance, including historical acceptance behaviors, and route details, allowing us to build fairly accurate predictions about Dasher acceptance. However, translating these behaviors into aggregate market metrics requires understanding the complex interactions within our assignments system.
Highly chaotic or stochastic systems, which have a lot of randomness, such as financial markets or the weather, would be very difficult to simulate, since building predictive models can be very difficult. Evaluating the predictions and behaviors needed to model is an important first step before embarking on any simulation project.
2) Understand, quantify, and evangelize the benefits of a simulator
Understanding and socializing the goals and benefits of building a simulator, such as minimizing damage to production experiences, accelerating product development, and exploring new product ideas is a critical first step when embarking on a project.
Generating fewer bad production experiences
The primary benefit of a simulator we identified was to reduce the number of failed experiments, which were costly to run as they reduce the quality and efficiency of our deliveries. This reduction can be translated directly into business value by evaluating how often failed experiments launch, the impact these experiments have on business metrics and how many of these would have been avoided through the use of simulation. As such, the most important goal for this simulation is a sufficient level of accuracy to predict failed experiments. This may mean directional accuracy without high precision is important, or it may require more. Achieving this level of accuracy will likely require an iterative learning process whereby your first simulation is unlikely to work sufficiently well, similar to developing production models.
Enabling a faster iteration speed
Simulation not only avoids failed experiments; it allows teams to iterate and learn from those failures faster. While harder to quantify, this impact on team velocity should be considered as one of the benefits of simulation. Simulation speed can also enable parameter sweeps to tune business performance across a broad range of potential settings.
Usability of simulation during development (e.g. minimal effort to configure and run a simulation) is an important factor in achieving this improved velocity, and it can be helpful to focus on usability to accelerate iteration speed and to attract early adopters who can help validate the accuracy and provide modeling insights.
Wall clock time to run a simulation (e.g. the elapsed time from starting a simulation run to results being available) is also an important goal in ensuring that simulators increase velocity. Our simulation wall clock time target is to replicate a one-week experiment overnight (<12 hours). Simulation has the potential to run much faster than production experiments due to a variety of reasons.
- Time and space can be parallelized - multiple time periods can run concurrently.
- Algorithms can run more frequently than they run in production. For example, if a system currently runs once per minute, but only requires 10 seconds to complete, it can be run at six times the speed.
- Sampling can also accelerate the time it takes to evaluate a simulation while still providing accurate results.
However, there are limits to how much we can take advantage of each of these factors. Parallelization requires provisioning more compute resources and can lead to greater compute costs if utilization is not managed carefully and some systems do not scale out efficiently and / or gracefully.
We also cannot choose arbitrarily short periods to simulate. A set of ten-thousand, one-minute long simulations for a week of delivery assignments would likely not capture the interdependencies of assignments through system state. One example of system state would be the number of available Dashers. If a particular assignment system assigns Dashers earlier, there would be fewer Dashers available later. As such, a minimum duration is required to evaluate how a system will stabilize over longer periods. In production experiments, we handle these through ‘switchback’ experiments that persist a given treatment for a minimum duration (e.g. 1 hour) to see how the system state matures. Similarly, simulations require a minimum duration, which we are currently experimenting with to get the best estimates of experimental results.
Novel product changes
Simulation can also be valuable for changes that are difficult to experiment with. This includes experiments for which there isn’t enough statistical power, or experiments that involve changes to the environment (e.g. having 20% more orders). Generally, these simulations will be more challenging to build as they may be harder to validate, so it’s best to tackle nominal cases first, before simulating novel or unusual ones.
Deeply understanding and evangelizing how simulation will reduce failed experiments, increase development velocity, and enable broader exploration will ensure alignment across the organization and help focus development over the lifespan of the project.
Stay Informed with Weekly Updates
Subscribe to our Engineering blog to get regular updates on all the coolest projects our team is working on
Please enter a valid email address.
Thank you for Subscribing!
3) Manage complexity through system design
Simulation is inherently complex and can quickly become unmanageable if not handled thoughtfully. Complexity can be managed through leveraging existing infrastructure and data formats and focusing on minimum viable models and use cases.
Leverage existing infrastructure
Utilizing your existing infrastructure can help make simulation robust to future changes throughout the rest of the system and simplify the process of testing new experiments in simulation. Our simulation works directly with a replica of our production assignments system. New changes to our production code base can be tested by deploying to the simulation cluster *without any code changes*. This feature is beneficial for both end users and for simulation management, as the interaction between simulation and production codebases will mean significant ongoing maintenance. To achieve this separation, we cleaned up our production API down to a single call that encapsulates all state and information necessary to compute assignments.
By abstracting this interface, we are left with a system where we have our core assignments system being served through a single scalable microservice, as seen in Figure 1, with individual batch simulation jobs calling that service (orchestrated by Dagster).
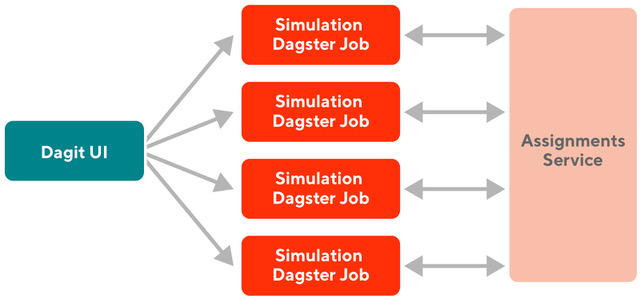
Snapshot historical calls and responses
Collecting the necessary inputs for a production system during simulation can be challenging as these are often logged across multiple data storage systems / logs. These systems also may not capture slowly changing values that are updated over time. To avoid these issues, we also snapshot the data passed in all historical calls and received in responses. This approach also enables us to easily and cleanly test that our offline simulation system is matching production behaviors; simply pass in a historical call and compare it against the historical response.
It is important to note that not all relevant experimental effects were contained within our assignments system. We experience feedback loops with supply incentives, eta estimates and other services. These loops are difficult to replicate in simulation, although it is likely a good starting point to assume historical behaviors, as collected in the snapshots.
Compare simulated treatment to simulated control
While comparing a simulation with historical metrics can be valuable for measuring and improving the accuracy of simulation, running two simulations (one for treatment and one for control) can help isolate experimental effects from simulation biases vs. historical data. This reduces the complexity by minimizing the importance of absolute accuracy and instead focusing on the effect of relative changes between treatment and control.
Simulation can be significantly easier to maintain and build by leveraging existing production code and creating and collecting data around clean abstraction interfaces. Simulation accuracy and interpretability can also be improved by always simulating both treatment and control to correct for absolute biases in simulation models.
4) Work smart by measuring progress and avoiding over-engineering
With a complex and ambitious project, it’s easy to try to tackle too much at once and then get lost along the way. To avoid this, it’s important to set tangible intermediate milestones, work towards a minimum viable product to minimize over-engineering components that have limited impact, and engage your user base early to deliver business value and improve performance around critical use cases.
Measure progress by validating functionality at each milestone
Many things need to work properly for a simulation to work well. Testing functionality through integration tests that are developed as functionality is built can ensure that the foundation is strong before building more complex components.
For example, in our assignments simulation project:
- We first confirmed that we were able to replicate production assignments from historical snapshots.
- Next, we validated our travel time and merchant wait models by confirming that our estimates had sufficient accuracy vs. historical observations.
- We then performed a small simulation on a single geographic region, validating that our batching rates and acceptance rates were roughly accurate.
- Finally, we were able to scale up to a sufficiently large sample of regions and start approximating production experiments.
Each of these stages served as excellent quarterly goals that the team could work towards and provide stakeholders quantitative measurements of progress towards building a functional simulator.
Build v0 models and evaluate before iterating
Unlike software APIs, which can have clear contracts on how they should behave, building mathematical models is rarely a binary task. Per statistician George Box, “All models are wrong, some are useful”. The challenge is to create imperfect models that sufficiently capture the desired behaviors for simulation.
However, despite past experience in developing models in this domain, there were still unknowns about what aspects of the model would be critical for simulation. As such, we biased towards simpler simulation models for travel time, wait time, idle Dasher movement and assignment acceptance, and we avoided investing time in tuning / improving these models beyond an initial v0 model until we were motivated by specific observed variances between simulated and historical data.

One example of a simpler workable model is our idle Dasher movement model, as seen in Figure 2, which predicts where Dashers will go when they are not assigned tasks. For instance, some Dashers may prefer to stay at home waiting for orders, while others will position themselves closer to specific restaurants to maximize the likelihood they receive offers. The model is a geohash Markovian model, which computes transition probabilities between geohashes, and samples from these distributions during simulation. This model was preferred for simulation as it is very easy to train, custom per geographic region, and robust to a variety of environments.
By delaying investment in these models, we were able to learn / observe some important properties of these models. While production ML models often try to approximate causal effects (e.g. how much more likely is a Dasher to accept an order if it is one minute faster for them), this aspect becomes increasingly important in simulation as it is the primary driver of accurate experimental results. While we have not pursued techniques to improve causal estimation, this will likely become an important consideration as we improve simulation accuracy. We also observed that simulation is fairly insensitive to travel time quality as most of our experiments do not result in different travel times for a specific route.
Partner with early adopters to prioritize investments with fastest returns
Finally, once a functioning simulator is built, finding early adopters and onboarding them to using simulation is critical to accelerate the simulation validation and model improvement process. We invested early in simplifying the simulation execution process and cleanly documenting how to run a simulation in a user’s guide that focused on steps necessary to run and only the minimal amount of general information about the simulation platform.
Breaking down a large project into smaller manageable chunks, incrementally validating efforts, avoiding unnecessary upfront investment in complex models or edge cases, and collaborating with early adopters can significantly improve velocity and reduce risk for a simulation project.
Case Study: Starting point optimization
DoorDash segments our geographic service area into ‘starting points’. Most deliveries within a starting point are dispatched using Dashers within that starting point. Starting points are important both for improving tractability of the Dasher to Delivery matching algorithm and for optimizing delivery quality and efficiency. However, since partitioning by starting points is built deeply into our production system, experimentation on starting point definitions can be challenging.
Simulation provides a flexible and efficient way to test new starting point definitions. Given access to all orders and Dashers within a broader geographical area, we are able to re-partition these orders and Dashers per new starting point definitions. By testing a variety of potential configurations, we are able to determine the optimal definition of starting points and improve assignment efficiency and speed.
Go forth and simulate!
Simulation has the potential to turbocharge development by providing a platform for quickly testing and iterating on new ideas. Setting clear and achievable goals collaboratively with partner teams will ensure sufficient support for the project and will leverage the knowledge across the entire organization to shape the project. Simulation complexity can also be managed by utilizing existing production infrastructure, creating clear interfaces, storing production calls and responses, and focusing on experiment effects over absolute accuracy. Working incrementally with checkpoints and minimum viable use cases will help ensure projects stay on track and ensure it’s possible to focus efforts where they will have the most impact. Simulation combines both engineering and modeling challenges that can be larger in scope than the average project in either discipline, but with thoughtful goals and management, success can come from learning and understanding the business quickly and efficiently to unlock business opportunities otherwise impossible to uncover.
Acknowledgements
Simulation is the product of a large team of folks who have supported development both through technical and thought leadership. Thank you to Ben Fleischhacker, Sameer Saptarshi,Ryan Leung, Kaike Zhang, Jianzhe Luo, Paul Brinich, Colin Schoppert, Paul Stepler-Camp, Cyrus Safaie and many others who have contributed!
