

DoorDash's Engineering teams revamped Kafka Topic creation by replacing a Terraform/Atlantis based approach with an in-house API, Infra Service. This has reduced real-time pipeline onboarding time by 95% and saved countless developer hours.
DoorDash's Real-Time Streaming Platform, or RTSP, team is under the Data Platform organization and manages over 2,500 Kafka Topics across five clusters. Kafka is the pub-sub layer of the Iguazu pipeline, which provides real-time event delivery at DoorDash. Almost six billion messages are processed each day at an average rate of four million messages per minute, which sometimes peaks at double that rate.
The RTSP team constantly looks for ways to speed up Iguazu onboarding. The slowest step in that process was provisioning Kafka Topics, which involved on-call engineer approval and was prone to failure, further increasing the on-call load. To improve this, RTSP partnered with DoorDash's storage and cloud teams to automate Kafka resources creation by integrating with an internal infrastructure resource creation service.
Key terminology
Here are definitions and links to further documentation about the tools we used. We address how these tools are used and their pros and cons in the main article.
- Terraform: Infrastructure-as-code (IaC) platform. It uses the unique HashiCorp Configuration Language (HCL) for configuring infrastructure resources. To provision infrastructure, create an execution plan, called a Terraform plan, and then execute the plan through Terraform Apply.
- Atlantis: A Terraform automation tool. Runs Terraform Plan and Apply. Merges Terraform pull requests on successful runs.
- Pulumi: Similar to Terraform, this is also an IaC platform, but without HCL. Pulumi instead leverages existing programming languages to manage infrastructure.
- Prometheus: A monitoring and time-series database. Designed for monitoring application and infrastructure metrics. Exposes query language PromQL for writing alerts on metrics.
- Chronosphere: Cloud-native observability platform. Built atop Prometheus.
- Cadence Workflow: Fault-tolerant, stateful workflow engine capable of executing directed acyclic graphs (DAGs).
Understanding the legacy architecture
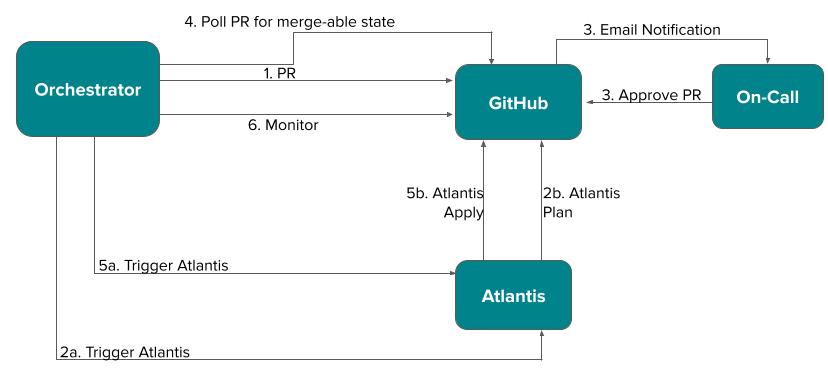
As shown in Figure 1 below, DoorDash's legacy approach to Topic creation involved several steps within a Cadence workflow.
- Orchestrator service triggers an API call against the GitHub repo for Kafka Topics, creating a pull request, or PR, for a new topic and corresponding access control list (ACL) entry.
- Orchestrator service triggers Atlantis to run Terraform Plan against the topic.
- On-call receives an automated email notification about the PR.
- Orchestrator service polls the PR status to check for on-call approval.
- Once approved and in a mergeable state, Atlantis Apply is triggered against the PR.
- Orchestrator services monitors for successful PR merge. In the event of failure, the PR is deleted and the process begins again from Step 1.
Unfortunately, the Topic creation workflow often would fail for any of several reasons:
- GitHub merge conflicts upon PR creation when multiple PRs are cut off the same commit
- Terraform state drift against Kafka state
- Atlantis sometimes would time-out on clusters with hundreds of topics and completes in a nondeterministic amount of time
- Atlantis state drift against Terraform state. Terraform is applied but Atlantis did not merge the PR
- Because reviewing and approving PRs is time-consuming, on-call sometimes would miss the email notification, causing time-outs. Note: The volume of new Topic-created PRs could exceed 20 per hour during product launches.
Furthermore, it is difficult to programmatically audit Kafka clusters and perform scale-up operations such as adding partitions or migrating to dedicated clusters without manual intervention.
Developing a new architecture
Initially, we considered a number of potential approaches, including:
- Creating durable in-memory state to track fine-grained progress and to synchronize between workflows. State would be recovered from disk on Orchestrator restart.
- Using the online transaction processing database (OLTP) to persist the state mentioned above.
- Writing a custom Terraform provider
- Increasing workflow retries.
All four solutions would have been duct-tape solutions unable to completely address the underlying issues: State synchronization across Terraform as hosted on Git, Atlantis, Cadence workflow, and Kafka. Although the first two might have solved some of the issues mentioned, they would have run the risk of further complicating state management by introducing new states to keep in sync. As the authoritative source of truth, Kafka must be consistent with any solution we choose.
Capturing a small win: A use case for Kafka Super Users
While exploring these solutions, we identified that merge conflicts were only occurring in the ACL files for Iguazu users. Each consumer and publisher in the Iguazu pipeline has a separate Kafka user account. Upon each Topic creation, an Iguazu user's ACL file was updated with an ACL entry for that topic. Eventually, the ACL files grew to have hundreds of permissions, significantly slowing Atlantis applications.
Our "eureka" moment was when we realized that this was a perfect use-case for super-user accounts. Permissions-related pitfalls meant that we usually shied away from setting up super users. But if each Iguazu user - REST proxy or upstream and downstream Flink jobs needed access to every single topic in a cluster, it would be ideal to give these users full read or read-write access as needed, eliminating the ACL file and its related issues. Additionally, the existing workflow could be further improved, as we will outline shortly.
Stay Informed with Weekly Updates
Subscribe to our Engineering blog to get regular updates on all the coolest projects our team is working on
Please enter a valid email address.
Thank you for Subscribing!
Going for the big win: Streamlined Kafka resource creation
Infra Service is an internal platform that provides an API to perform CRUD operations on infrastructure components. It is built and maintained by the Infrastructure organization at DoorDash. It replaces the traditional approach of using infrastructure-as-code and GitOps to provision infrastructure. Infra Service replicates the important features provided by Git and GitHub, including version control and change reviews. It's also plugin-driven, allowing teams to add support for resources that they would like to manage programmatically. Most of the work required to implement an Infra Service plugin involves writing an underlying Pulumi program.
Infra Service uses Pulumi to handle infrastructure provisioning under the hood. Pulumi is an infrastructure-as-code tool similar to Terraform, but unlike Terraform Pulumi allows for using general programming languages to define infrastructure. It has robust support for testing and an extensive provider catalog. Infra Service handles programmatically invoking Pulumi when a change is requested and propagating any outputs resulting from the Pulumi execution back to the end user.
To create Kafka and database resources, we've developed a component within Infra Service called Storage Self-Serve Platform. This is shown below in Figure 2.
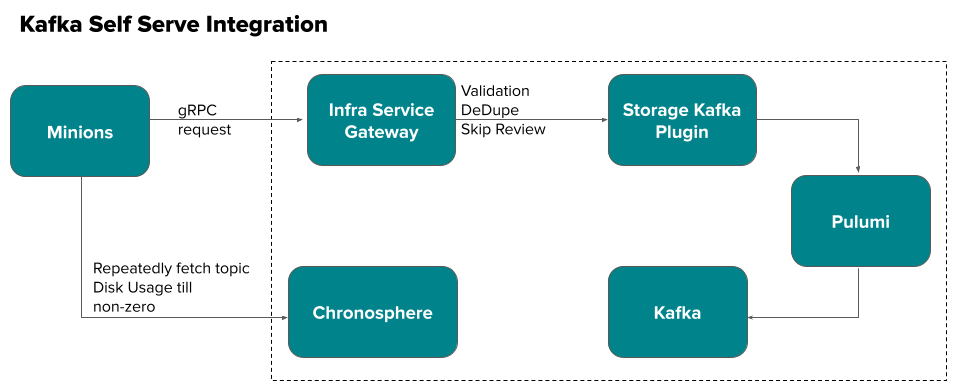
In Figure 2, still wrapped in a Cadence workflow, the Topic provisioning is reduced to a two-step process:
- Orchestrator service Minions fires a gRPC request to the Infra Service gateway to provision the Kafka Topic. Minions receive a synchronous response on whether the topic create request is persisted. At this point, the topic creation might not have been completed. From Minions' perspective, everything behind the Infra Service Gateway is a black box that handles dedupe, validation, and retries.
- Because a Topic is considered created when it shows up with non-zero disk usage, Minions continuously polls the Prometheus metrics platform Chronosphere for that state. All Topics, even those without any messages, include some metadata that is backed up to disk. We use Chronosphere for two reasons: First, it independently corroborates the state of the Infra Service black box and, second, DoorDash runs Chronosphere at at four nines (99.99%) availability. This means that Chronosphere outages essentially don't exist. If Kafka doesn't report topic metrics for a few minutes, it is improbable that this will continue any longer -- unless there are bigger issues with Kafka. When the metrics eventually show up in Chronosphere, they will be pulled by Minions.
Savoring the win
This new architecture allows provisioning roughly 100 new topics every week without manual intervention. With this API-based topic workflow, we reduced Iguazu onboarding time by 95%. Previously, customers were guaranteed onboarding within two business days, or about 48 hours. Now onboarding completes within an hour of request submission and often within 15 minutes. And there's a bonus: Manual on-call intervention has been reduced about four hours per week.
Each topic created using the new architecture includes rich metadata on ownership, throughput expectations, and message size, which will ease enforcing reliability guardrails in the future.
Ultimately, by integrating with the standard Storage Self-Service Platform within Infra Service, we have access to admin controls including overriding topic configurations, retrieving user passwords, and developer friendly access to Kafka cluster state.
Exploring a storage self-service future
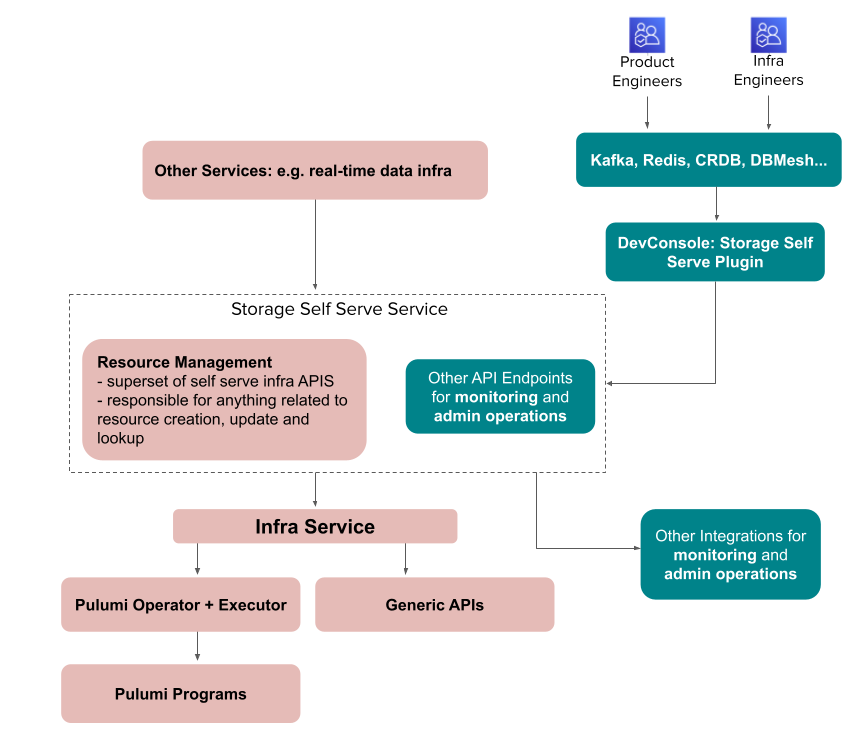
Building on the success of Infra Service and the Storage Self-Serve Platform, we plan to add the following features to improve our guardrails and customer experience. Figure 3 illustrates the high level architecture of the future design.
- Centralized validation logic, which will be maintained by the storage team. Such validation logic can be continuously tuned to match business needs.
- Smart default values. Partition count and replication factor can be computed based on customer request. This simplifies user input to provision a topic.
- Catch duplicate requests earlier in the provisioning process through deduping logic that is specific to Kafka. Return API errors to users.
Acknowledgments
This engineering win has been a team effort across several teams: Real-Time Streaming Platform, Storage. and Cloud. Special thanks to all the engineers who helped realize this: Roger Zeng, Luke Christopherson, Venkata Sivanaga Saisuvarna Krishna Manikeswaram Chaitanya, Basar Hamdi Onat, Chen Yang, Seed Zeng, Donovan Bai, Kane Du, Lin Du, Thai Pham, Allen Wang, Zachary Shaw and Varun Narayanan Chakravarthy.


