

There has never been a technology revolution bigger than the one we are experiencing right now. AI is everywhere, both in the tools we leverage to improve velocity and in the products we build to enable features not possible without machine learning. Large language models (LLMs) create boundless potential that excites the imagination of engineers working to apply them to what once were seen as intractable problems. Although it is easier by the day to demonstrate value, it remains profoundly challenging to apply LLMs to a production workload at scale. Building reliable, performant, and efficient infrastructure that scales to support immense data velocity and volume has become a primary challenge in this space.
This blog focuses on one critical component of that pipeline: the feature store database. Solving challenges at the database layer provides broad benefits across the organization, and spending the past year building our new machine learning (ML) feature store has provided us with valuable insights we want to share.
DoorDash ML platform overview
DoorDash’s service reaches over one billion consumers globally, offering millions of items. In the food delivery segment alone, these items are highly customizable — for instance, favorite pizza toppings, hold the mayo, favorite drink — and dynamic, with things like variable stock availability, constantly changing business hours, and fluctuating delivery times. This inevitably demands a massive amount of data correlation to merge preferences and product catalogs into an intuitive experience that feels delightful for each user. Our new ML feature store serves as a foundational data layer for DoorDash’s ML platform. Its success is vital to the performance of our Sibyl Prediction Service (SPS), which at its peak supports around 900,000 ML evaluations per second.
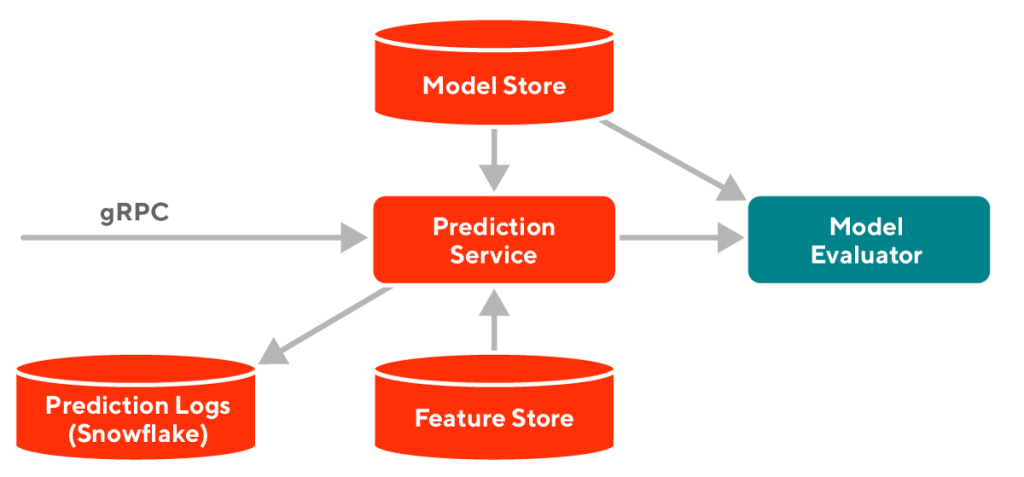
ML feature store evolution
The outcome of an ML model's predictions is only as good as its input data. For the highest quality results, this data must be refreshed with minimal delay and served with extremely low latency—and doing so cost-effectively is crucial for the business. Redis is often the first tool that comes to mind for these requirements, making it a natural starting point for many teams, including ours at DoorDash. We achieved great success with this design initially. However, once we reached a level where per-instance vertical scalability was no longer an option, the cost of maintaining the entire dataset in memory began putting pressure on our efficiency targets.
Our first attempt to relieve this scalability limitation involved migrating some of this data from Redis to a horizontally scalable relational database. We selected a subset of data for which the reduced query performance would not have a detrimental impact on either the user experience or the value of the resulting prediction. This hybrid approach allowed us to overcome a looming Redis bottleneck while continuing to support the product roadmap demand to leverage ML innovations.
The next scalability limitation came when this data set doubled, once again exposing the vertical scalability limits of Redis, but now coupled with the complexity of operating a 1,000-plus-node relational database cluster. DoorDash’s relentless drive to improve our service, coupled with a need to operate an efficient, future-proof platform, prompted us to reinvent the feature store design for the future.

ML feature store: A new platform
The guiding principles informing the scope and requirements for the ML feature store we sought to create included:
- Drop-in replacement: Allow the team to move quickly and independently with a solution that requires little or no changes to adjacent systems. This included API contracts from clients invoking ML services, as well as using existing source data to avoid migrations.
- Favor low-cost hardware: Keeping costs down required factoring in the fact that RAM is 100 times more expensive than SSD storage. We also ruled out depending on vertical scalability via expensive rare/large hardware instances.
- Platform approach: It’s best to solve problems at the lowest level possible without exposing the topology or complexity of the datastore implementation to clients.
- Build for 100x scale: A robust horizontal autoscaling mechanism helped to future-proof against the likelihood of fast growth. Such a mechanism should include query performance, while also supporting rapid, hourly periodic data refreshes as an initial target.
- Stateless Design: Reliably sharing cluster state through a peer-to-peer updating system (like a gossip protocol) almost always becomes a bottleneck at scale. To avoid this limitation, we built a truly stateless system: a distributed Redis cluster using instance store disks.
Architecture overview
The clusterless ML feature store serving layer is based on Apache Kvrocks, which provides a Redis Serialization Protocol (RESP) interface on top of the battle-tested RocksDB. Our main challenge was to facilitate efficient data bulk loading and to effectively enable infinitely horizontal scalability. Kvrocks natively implements Redis clustering, but the overhead of clustering and state management would not have allowed us to reach our goal of building a distributed stateless Redis cluster.
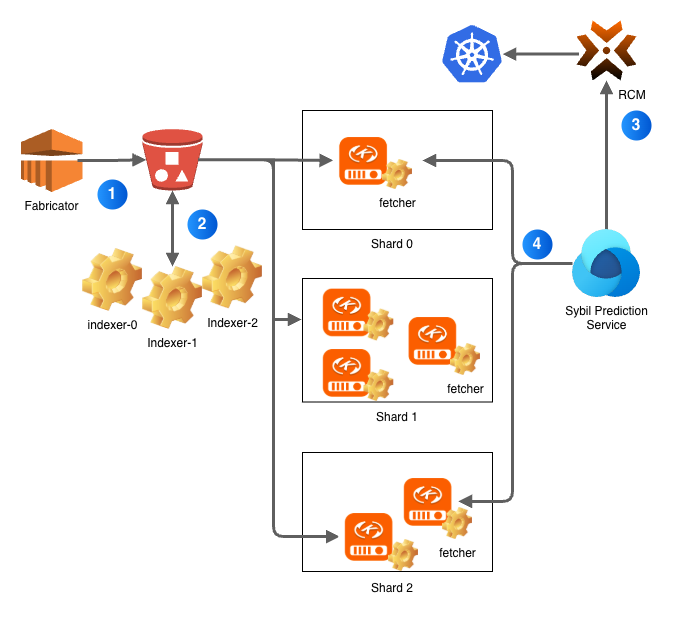
Figure 3 shows our clusterless feature store for a Redis cluster with three shards. As annotated on the diagram, the high-level steps include:
- All interesting feature data is consolidated from various sources via batch job and uploaded in parquet format to an S3 bucket.
- A set of indexers — one per shard — processes this data, checkpointing the load progress into S3 in the form of a RocksDB backup.
- The serving layer fetchers download a needs-based designated RocksDB shard backup and serve the data via RESP.
- Redis Cluster Manager (RCM) implements the Redis cluster protocol to provide topology transparency to the clients.
RCM: The critical ingredient
RCM is the secret sauce that allows our clusterless feature store to scale “infinitely.” Drawing from our expertise in networking, we applied a fundamental principle of internet-scale operations by separating the data from the control plane.
The Redis client/server protocol expects the client to query a discovery endpoint — typically any of the Redis nodes in the cluster — to obtain the cluster details. In our design RCM is this endpoint and its response contains only a subset of all target shards information from which the client can directly fetch keys. The subset of relevant nodes for a given client may be a small percentage of the total number of nodes deployed.
Deployed as a Kubernetes Service, RCM leverages the K8S Pod Watch API to generate a dynamic response to a client’s “cluster nodes” request to route and distribute connections appropriately. RCM maintains the cluster topology information and allows the clients to behave as if they were interacting with a standard Redis cluster; all back-end data pods act as stateless singletons and serve the data they have custody of.
This design meets our intended criteria, providing a mechanism to automatically scale up the instance count for any individual shard in isolation from existing topology. This is accomplished in the time required to instantiate the data from S3, requiring no clustering overhead of a shared state.
Stay Informed with Weekly Updates
Subscribe to our Engineering blog to get regular updates on all the coolest projects our team is working on
Please enter a valid email address.
Thank you for Subscribing!
It’s not real until it’s real
Thanks to RCM, we achieved our goal: A distributed, stateless Redis cluster running on commodity disks. We then had to prove that our datastore was production-ready. We designed a two-phase rollout plan to introduce this new design safely without disrupting existing functionality or client workflows.
- Phase 1: Shadow validation: In this phase, the SPS client is configured to double-read features from both the existing native Redis cluster and our clusterless data store in parallel. Clients emitted key metrics describing such things as fetch latency, fetch value distribution, and error rate. This allowed an objective comparison in performance, accuracy, and reliability of interactions across both domains, and allowed the system to mature under real production load with a failsafe mode.
- Phase 2: Migration: Using transport level routing controls, we began moving traffic exclusively to our feature store without the shadowing option. Occurring over a number of weeks, this migration built confidence while we continuously observed and addressed changing trends in metrics.
Although the phase 2 migration was successful overall, it exposed a couple issues of note:
- The client demonstrated an imbalance with its slight preference toward using the first node returned in the “cluster nodes” response. This was not ideal, but the variance was slight enough that we could simply note it and deem it manageable within our autoscale triggers.
- During the hourly data batch refresh, we noted an increase in fetch latency. This, too, was manageable, but we wanted to decouple refresh from query operations completely, so we addressed the latency by adding support for SST (Sorted String Table) sideloading to Kvrocks.
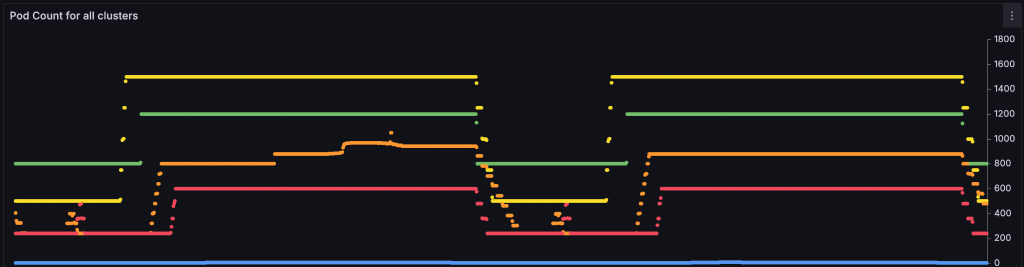
We were far more concerned, however, with an increase in fetch latency correlated with the number of nodes added to a shard: the more nodes a shard had, the higher the latency we recorded. This trend demanded attention because it directly contradicted our goal of infinite scaling. We put significant effort into understanding its cause, including tuning client configurations, adjusting coroutine pools, adding more telemetry, and modifying instance sizing. Ultimately, we went back to first principles. Large Redis clusters are problematic on the client side due to the vast number of connections and cluster metadata the clients must manage. If we couldn’t make the client perform well with a massive cluster—in this case, more than 2,000 Redis nodes—maybe we could make it see a smaller one.
As a result, we decided to have RCM return a smaller subset of nodes composing the cluster during discovery. Based on the source IP address of the client, a subset of target shard instances are returned in the cluster nodes response, optimizing performance while ensuring distribution of the query load and limiting the connectivity from each client. This last implementation unlocked the infinite scalability we sought for the ML feature store.




As of this blog post, our clusterless feature store is in production, supporting a peak per-second load of over 130M HMGETs for 1.6B retrieved features, within a 50ms P999 latency target. We are particularly pleased that the capacity required to achieve this peak load is dynamically deployed and will continue to grow with business demand.
Final thoughts
Building this clusterless ML feature store over the past year has been an amazing experience! Engineering outcomes are enabled by technology, but it’s the people and team collaboration that ultimately make these outcomes possible. None of this fun would have been possible without Arbaz Khan, Rabun Kosar, Hebo Yang, and Vasily Vlasov.
The feature store scalability and cost savings have been so well received that we’re already working on the second version to extend support to any kind of offline-to-online data use case.
You can follow our DoorDash Engineering Blog to watch how the feature store evolves. And if you want to work on exciting, large-scale systems like this, we’re hiring!
