

In today’s data-driven world, there is a significant advantage to being able to support a polyglot data environment in which different storage and processing technologies are used to handle various needs. Modern data ecosystems handle diverse data types and workloads. At DoorDash, we use a variety of tools and frameworks to meet our wide-ranging data requirements. This naturally introduces different query engines and numerous SQL dialects.
Human errors can arise during SQL dialect translations as we use data collaboratively across these tools. Even subtle differences in a translated query can significantly impact job results, performance, and cost.
Interoperability becomes essential to leverage data seamlessly across various platforms and technologies. SQL translators play a key role by enabling data applications to interact with multiple sources without major code changes, making them portable across different database backends. Transaxle, our internal SQL translation service built in collaboration with Databricks, helps us achieve this interoperability.
DoorDash’s data interoperability needs
We work with diverse data types and processing needs at DoorDash, from real-time analytics to large-scale machine learning. For example:
- Business intelligence workloads use stream processing such as Apache Kafka or Flink alongside fast querying with Trino over data lakes that use modern formats like Iceberg and Delta Lake.
- Machine learning workloads rely on Spark SQL and MLlib to handle large, complex datasets with iterative, in-memory processing.
To support this smorgasbord, we’ve adopted a lakehouse architecture that combines the scalability of data lakes with the performance and structure of data warehouses. It separates storage, for example S3 and Parquet; metadata, for example Iceberg or Delta; and compute, for example Snowflake, Spark, Trino, and Flink. This allows multiple engines to operate on the same data efficiently, which promotes flexibility, cost control, and scalability.
However, working across multiple engines introduces a challenge: SQL dialect fragmentation. Teams often need to translate between Trino, Snowflake SQL, and Spark SQL, a process that costs time, requires training, and introduces room for error.
To solve this, we support automated SQL translation, enabling seamless interoperability:
- Trino ↔ Snowflake SQL
- Snowflake SQL ↔ Spark SQL
- Spark SQL ↔ Trino
This empowers teams to collaborate easily, reuse queries across platforms, and work with the engine best-suited for their workload — all with familiar SQL.
Transaxle service overview
Transaxle serves as the one-stop shop for SQL translation needs throughout DoorDash. Figure 1 illustrates the - components of the Transaxle service, showing how it handles SQL translation and integrates with various systems. It demonstrates the framework's ability to manage different types of translations and improve translator accuracy over time.
In any type of SQL dialect translation, work is required on the query both before and after. We can organize this work into three steps: pre-processing, validating the SQL syntax of the translation, and post-processing.
Pre-processing involves preparing an SQL query so it can be correctly interpreted by the designated translator. Most SQL queries that users would submit for translation have custom macros, table names from an old catalog, and/or placeholder variables. Translators do not have the context to handle these components and often break when encountering them. By having Transaxle take on this pre-processing work, dialect translation becomes seamless because Transaxle makes the query parsable by the translator, as shown in Examples 1 and 2 here:


As shown in Example 3, post-processing involves restoring the custom macros and placeholder variables in the translated SQL. That way, the final result has the contextual variables that users expect. Post-processing also handles persisting the translation results in Transaxle’s internal storage layer. Transaxle’s report generator reads from this storage layer and gives an effectiveness rating for each of the translators used. These reports kick off a feedback loop to improve the translators, identifying which queries have encountered issues so that developers can address them in the next translator version.

Transaxle’s framework does these pre- and post-processing tasks to ensure proper translation and to establish the feedback loop needed to improve the translators. While these tasks are specific to DoorDash’s SQL needs, we partnered with developers at Databricks Labs for the source-to-source conversion of these queries; together, we created a powerful SQL translator from source dialect to Spark SQL dialect. The result of this collaboration laid the groundwork for the Remorph Project, which assists migrations to Datalake by automating code conversion and migration validation.
Stay Informed with Weekly Updates
Subscribe to our Engineering blog to get regular updates on all the coolest projects our team is working on
Please enter a valid email address.
Thank you for Subscribing!
Integration
Transaxle is exposed as a flexible API, allowing it to be invoked programmatically from any codebase or service that requires SQL translation. In addition to API access, Transaxle also provides a user-friendly interface that lets users input ad-hoc SQL queries and receive translated outputs. This dual access pattern enables both automated and manual workflows across diverse teams and use cases.
Transpiling
We leveraged the techniques that underpin a code transpiler to build the SQL translator for Transaxle. A transpiler, also known as a source-to-source compiler, is a tool that converts source code written in one programming language into equivalent source code for a different language. The key aspect of transpilation is that both the input and output are high-level languages, typically with similar levels of abstraction.
A code transpiler first converts the source code into an abstract syntax tree, or AST. The AST is a language-agnostic representation of the intention of the original code. With the AST in hand, the transpiler can then convert each abstract construct into its target code representation. Figure 2 outlines the steps during which a source code script is tokenized, parsed, converted into an intermediate representation, and ultimately converted into its target dialect.
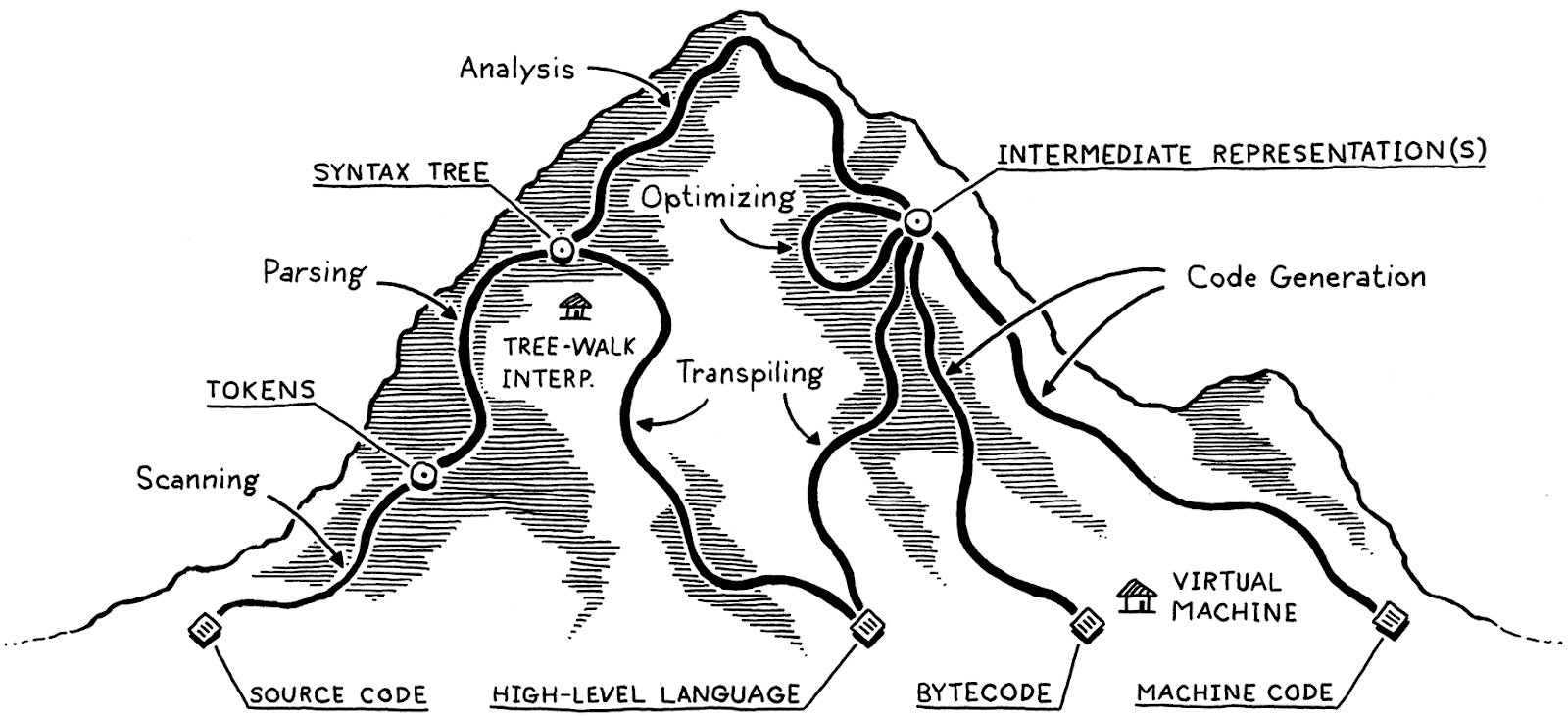
Let’s trace through each of those trails and points of interest. Our journey begins on the left with the bare text of the user’s source code:
- Lexical analysis (tokenizer): The initial step in understanding source code is to read it and convert it into a series of tokens.
- Syntax analysis (parser): The parser builds the tokens into an AST tree structure based on the programming language’s grammar.
- Transformation (intermediate representations): The parser tree is transformed into an intermediate representation of the target language
- Code generation: Intermediate representations can then be used to generate the corresponding code.
To see how this works in action, consider the following Snowflake SQL query, which leverages the TRY_TO_NUMERIC function:

There is no one-to-one corresponding function in Spark SQL, because Spark does not have a NUMBER or NUMERIC datatype. These types are, however, aliases for the DECIMAL type that Spark does have. The corresponding output becomes:

Notice that the Spark SQL function TRY_TO_NUMBER has a different signature from the TRY_TO_NUMERIC. Specifically, it does not set the precision and scale of the resulting DECIMAL type. The transpiler needs to be aware of this difference and add those features as part of an additional function call (for example, calling the function CAST with a defined precision and scale). It also needs to have the insight to move the 5 and the 2 from the original model signature to their corresponding places in the call to CAST.
There are several publicly available SQL translation tools, such as SQLGlot from Tobiko Data and Apache Calcite. You may instead create a parsing framework using tools like ANTLR (see, for example, How to write a transpiler). We found during initial testing that SQLGlot can convert a large portion of source SQL queries to Spark SQL because it has existing support for both dialects. The SQL translator at the heart of Transaxle and Remorph is based on SQLGlot's framework, although that is scheduled to change soon. The DoorDash and Databricks development teams have extended the original framework to handle additional edge cases — for example, custom Databricks dialect tests — and have partnered with the SQLGlot development team.
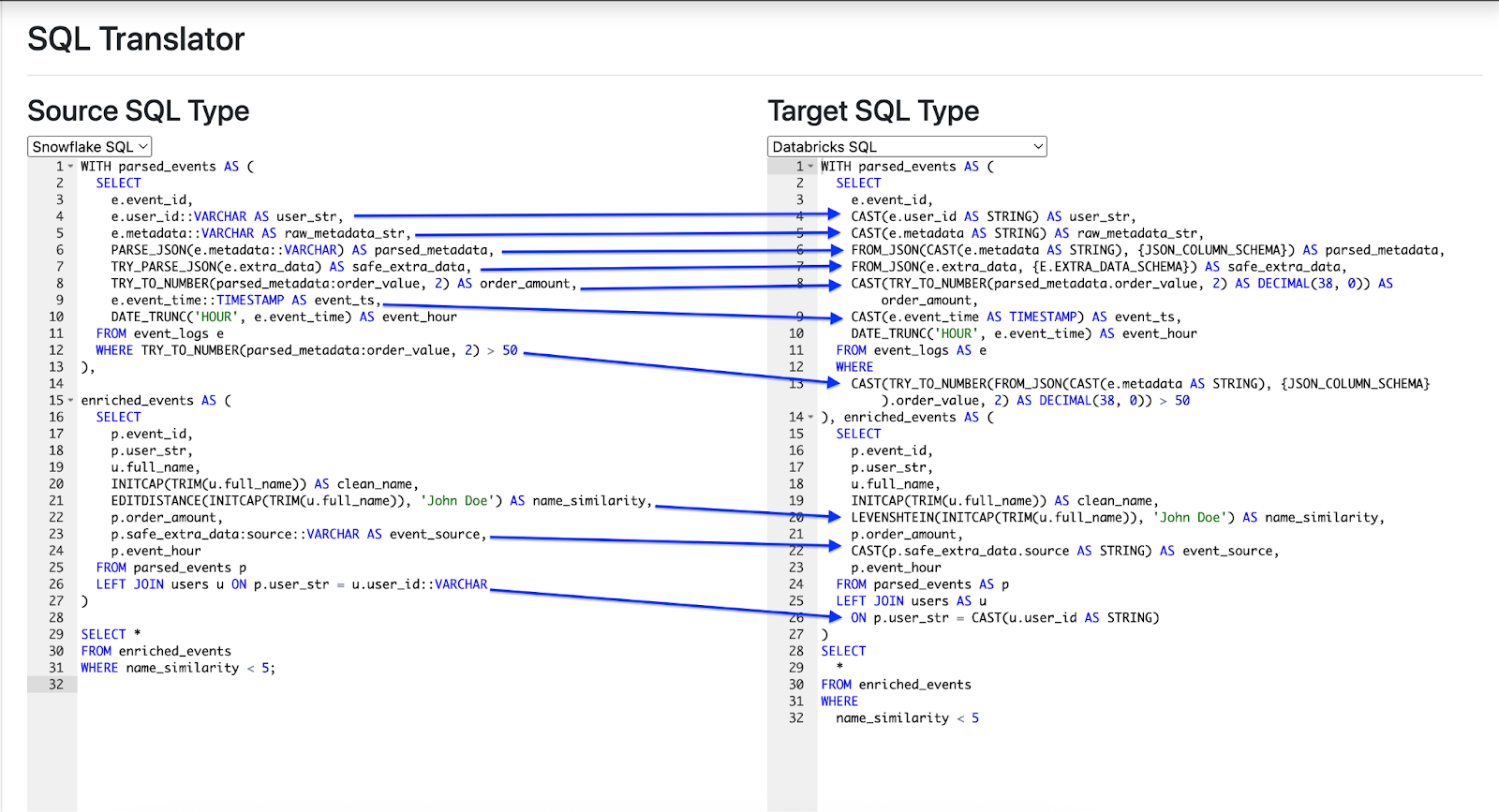
Let’s now examine a complex query translation, where the tool modifies 10 distinct elements of the source query, as shown in Example 4.
Results and findings
We launched Transaxle at the beginning of 2025 to help data engineers translate SQL across engines, enabling them to use different tools and platforms on the same underlying data — a key principle of the lakehouse architecture.
Initial translation accuracy was around 70%. Analysis of Transaxle logs revealed that success wasn't just about the transpiler; it also depended on how SQL was written in our extract, transform, and load processes and the state of our internal table catalog mappings.
Through the creation of Transaxle’s feedback loop, we have addressed two key issues:
- Lightweight fixes: Unmapped functions, for example Snowflake’s EDITDISTANCE to Spark’s levenshtein, and missing syntax such as INTO in MERGE INTO.
- Complex cases: Incorrect handling of nested lateral column aliases and missing precision/scale in CAST operations for Spark SQL.
We also resolved catalog-related preprocessing issues, including:
- Missing mappings, in which tables had no equivalent in the target catalog, and
- Duplicate mappings, in which one table name pointed to multiple targets, creating ambiguity during translation.
An early issue was the inconsistent use of SQL template variables across teams. While Transaxle handled common patterns like ${} and {}, we later added support for others, including {{}} (Jinja2).
As illustrated in Figure 3, Transaxle continues to evolve through the identification of new patterns, enhancements to transpiler logic, and improved cross-platform query portability.

We are constantly identifying new patterns, errors, and feedback, and refining our transpiler logic accordingly.
Future integrations
A key future application of our SQL translation service will involve integrating it with AskDataAI, our internal natural language AI data assistant. This integration will enable AI-assisted SQL translation, allowing users to formulate queries in plain English and have them automatically translated into optimized SQL tailored to the appropriate compute engine.
To support this, we will deploy a model context protocol server that acts as the intermediary between AskDataAI and the Transaxle API. This architecture will also allow seamless integration with a variety of other tools and frameworks across the organization that require on-the-fly SQL translation based on the target compute engine, including Snowflake, Databricks, and Trino.
This blog has walked through our SQL translation service’s version 1 implementation, which has created the foundational layer to power this upcoming capability and sets the stage for future advancements in intelligent data interaction.
Final thoughts and takeaways
Data interoperability is essential in a modern lakehouse architecture. It enables seamless data access across different engines and teams without compromising on performance, consistency, or developer velocity. SQL translators like Transaxle are critical components in making this interoperability a reality. They bridge dialect gaps, reduce human error, and unlock faster, more collaborative use of shared data assets.
From our work with Transaxle, we’ve learned that a successful SQL translator needs to be:
- Accurate in handling syntactic and semantic differences between dialects;
- Extendable for evolving dialects and organization-specific SQL constructs; and
- Integrated into the broader data platform so users don’t need to think about translation — it “just works.” This includes providing APIs that frameworks and tools can use on the fly to convert and execute queries dynamically.
Despite our progress, challenges remain. We continue to research column-level verification between translated and original queries. We also continue to expand support for variable templating formats and reduce dependency on perfect catalog mappings.
Looking ahead, we’re excited to continue evolving Transaxle. As more teams move toward real-time analytics and machine learning use cases, the need for accurate, scalable SQL translation only grows.
Ultimately, building an SQL translator isn’t just about converting queries; it’s a litmus test for how interoperable, modular, and ready your organization is for the lakehouse future.
Acknowledgements
Derek Yi - Senior Software Engineers at Doordash
Nick Senno, Sundar Shankar, and Pavan Nissankararao - Senior Software Engineers at Databricks

