
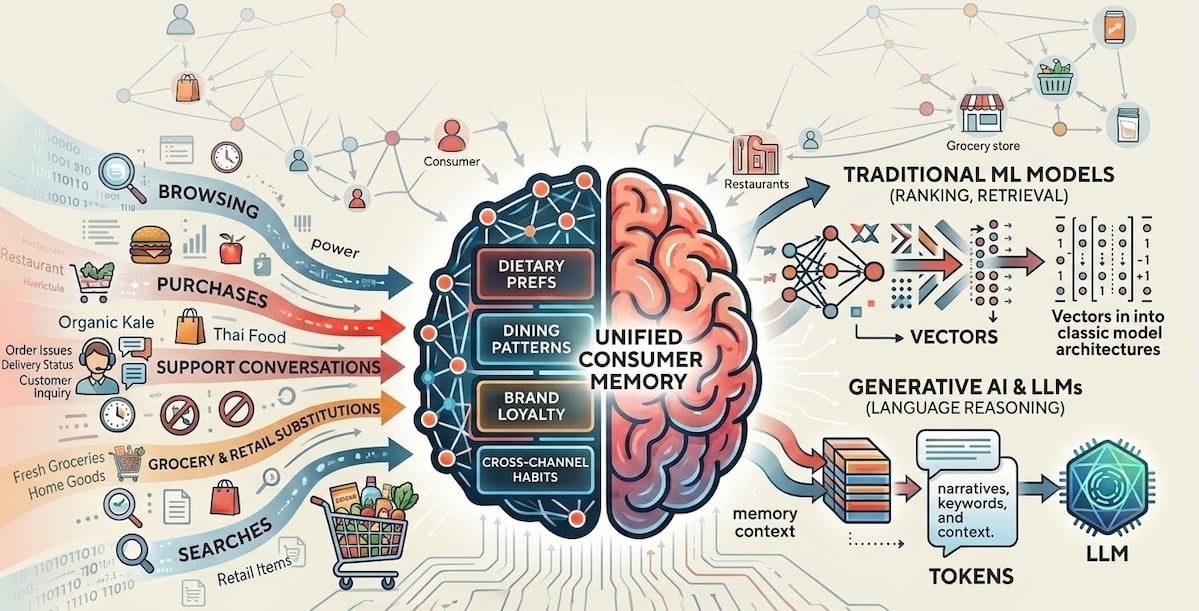
DoorDash's marketplace spans restaurants, groceries, convenience stores, retail outlets, and more. Across these verticals, we encode rich signals about consumer preferences: What they browse, what they buy, what they reject, and what they substitute, among many other behaviors. This data contains latent understanding of the consumer such as dietary habits, price sensitivity, and brand loyalty.
We leverage all of these signals in our deep learning models at scale through rich sequence and multimodal representations. But these representations encode statistical patterns, not semantic understanding. An embedding can capture that a consumer frequently purchases organic produce, but it cannot express why, distinguish a dietary restriction from a casual preference, or communicate that understanding to a large language model (LLM).
As a result, it has not been feasible as we invested in AI experiences to develop personalization through learned representations alone. LLMs, for example, reason in language, not in learned representations. At the same time, it was not practical for every surface and model to independently extract consumer understanding from raw behavioral data.
To contend with this, we built a unified memory platform that systematically extracts semantic understanding from behavioral signals and makes it available across every personalization surface for generative retrieval and ranking models. Rather than treating behavioral data as only a feature engineering problem, this system treats it as a semantic extraction problem, producing representations that both traditional machine learning (ML) models and LLM systems can consume directly.
For ML models, memory blocks are encoded into dense embeddings and graph-based features that plug into existing ranking and retrieval architectures, enriching two-tower models and multi-task rankers with signals that go beyond engagement history.
For generative AI-driven experiences, the same memory blocks serve as natural language context, grounding reasoning in what we actually know about a consumer, rather than re-deriving it from raw data for each turn.
Gaps addressed
Collaborative filtering and engagement-based models are the backbone of our personalization stack. They excel at patterns such as “users who bought X also bought Y.” But often there are nuances in the intention and attributes of the purchase that cannot be captured implicitly through engagement signals. A consumer who buys organic kale and almond milk likely has a broader plant-forward, health-conscious preference that likely would influence their experience across categories they have yet to browse. Engagement models cannot make this inference because they operate on item-level signals, not consumer-level semantics.
Embedding-based user representations, such as user towers in two-tower models, learn dense vectors from engagement sequences. These capture latent patterns effectively, but the representations are opaque; they are useful for similarity search but not inspectable and not interpretable by LLMs.
We wanted to produce a shared, semantic, language-native understanding of the consumer that works for both traditional ML systems and LLM-driven systems.
Three memory layers
As shown in Figure 1, the memory system maintains three complementary memory types, each optimized for different timescales:

The long-term memory engine turns raw behavioral signals such as orders, search, browsing, and support into a durable, interpretable memory for each consumer. It does this by generating memory blocks — for example, dietary preferences — made of versioned components, or atomic payloads, persisting them, and assembling them into a single long-term memory manifest for downstream systems.
In-session context captures real-time signals about current intent, such as cart contents, active searches, browsing patterns, items viewed and rejected, and time spent in categories. This layer has a high recency weight; what a consumer is doing right now overrides or supplements historical patterns.
Explicit context and memory captures preferences and constraints that consumers state; this knowledge is fundamentally different from inferred preferences. When a consumer mentions brand preferences or substitution preferences during a support session, for example, we capture that as explicit preference in memory. Unlike behavioral inferences that update gradually, explicit preferences are more stable and require explicit modification.
Graduating memory across layers
These layers are not static silos. In-session patterns that recur across multiple sessions — for instance, a consumer consistently browsing Mexican restaurants every Thursday — are candidates for promotion into long-term memory. Similarly, captured explicit preferences feed into the consolidation pipeline that updates long-term memory blocks on the next batch cycle. This graduation process ensures that any short-lived signals which prove to be durable are captured permanently, while one-off behaviors naturally decay. The consolidation pipeline validates, deduplicates, and merges incoming signals before promoting them, preventing noise or misinterpreted interactions from corrupting the long-term profile.
This post focuses on long-term memory: How we generate it, how we build a consumer context graph from it, and how we encode it into ML-ready representations.
Stay Informed with Weekly Updates
Subscribe to our Engineering blog to get regular updates on all the coolest projects our team is working on
Please enter a valid email address.
Thank you for Subscribing!
Long-term memory engine
We use LLMs to synthesize behavioral patterns into semantic memories and keywords as natural language descriptions grounded in catalog data, such as:
- "Strong affinity for organic produce; prefers premium brands in fresh categories; price-conscious on packaged goods"
- "Weekly bulk shopper; consistent weekend ordering pattern; average basket $40-50"
- "High loyalty to 3 to 4 specific stores; explores new merchants for South East Asian dishes."
Unlike static tagging systems that rely on fixed categories, memories capture nuance and serve both ML models via embedding conversion and LLM systems via direct natural language reasoning.
We compute long-term memory offline via batch processing at a daily or weekly cadence. The batch approach is intentional; LLM-based memory generation is compute-intensive, and real-time generation would create unacceptable latency. Additionally, long-term memory captures durable preferences and hence is ill-suited to minute-by-minute updates.
Memory blocks
Long-term memory is organized into memory blocks, modular, domain-specific groupings that each capture a different dimension of consumer understanding. Each block contains multiple components, which are atomic units with strict schemas that can be versioned and updated independently, as shown in Table 1.
Examples of Memory Blocks
| Memory Block | Components | What It Captures |
| Dietary Preference | narrative, type, strictness | Dietary, cuisine preferences and food choices |
| Dining Patterns | cuisine preferences, behavior, food types | Restaurant and ordering behavior |
| Item Brand | brand narrative, brand ID, keywords | Brand level affinities (per entity) |
| Item Taxonomy | taxonomy narrative, substitute signals, support signals, keywords | Category level preferences (per entity) |
| Store Preferences | primary stores, loyalty type, reorder tendency | Merchant loyalty and shopping patterns |
| Cross Channel Patterns | complementary behaviors, substitution patterns, seasonal trends | Multi-channel and cross-vertical behavior |
Each narrative is a statement grounded in behavioral evidence. Brand and taxonomy blocks also carry extracted keywords and substitute signals using both approved and disapproved substitution patterns. This richness is what makes the downstream encoding pipeline possible; there is enough structured semantic content to build both dense representations and a graph.
Versioned components and manifests
Components are defined with strict Pydantic schemas, versioned independently, and carry full lineage, including model ID, generation timestamp, prompt hash, and response hash.
Memory assembly is controlled via manifests that specify which component versions to use:
version: 3a
blocks:
dietary_preference:
dietary_narrative:
schema_version: v1.1
model_id: dietary_llm_v2
item_brand:
brand_narrative:
schema_version: v1.0
model_id: brand_llm_v1
item_taxonomy:
taxonomy_narrative:
schema_version: v1.2
model_id: taxonomy_llm_v2Manifests decouple generation from consumption. For example, we can deploy manifest version 3a to 10% of consumers and version 3b to 90% with independent metrics, and revert if quality degrades. This allows us to reconstruct any consumer's memory as of any date.
The encoding challenge for ML models
Memory blocks convert raw behavior into semantic intent and attributes. This allows us to represent consumers beyond purely engagement-based signals — such as "user clicked item x, y, z" — and instead capture a summarization of attributes and intent — such as "plant-forward, organic, prefers premium brands in fresh categories" — in a form that can be directly aligned to catalog semantics.
This matters because many of our hardest personalization problems are semantic matching problems, not purely co-engagement problems:
- Consumers want items that match attributes and constraints, not just similar items to what they bought before.
- Our catalog has incomplete structured tags for many of these semantics such as "plant-forward" or "weekend indulgence".
- Engagement history alone is sparse and non-compositional. It does not generalize cleanly from individual purchases to higher-level preference patterns.
Memory blocks fill this gap by producing human-meaningful semantics that can be mapped to marketplace entities, including brands, taxonomies, attributes, and keywords, before being aligned back to the item catalog.
However, memory blocks are not ML-ready out of the box:
- They are semantically rich, which also makes them hard to represent as a single feature. Each consumer has dozens of preferences across brands, taxonomies, substitute rules, and lifestyle signals — far beyond a single embedding or a small set of scalar features.
- They need to map cleanly onto the catalog. The value is unlocked only when we can reliably translate memory semantics into item-level signals.
- They must support both training and online inference, including fixed-shape tensors and sparse features compatible with our existing model architectures, fetchable from the feature store at serving time.
Memory signals provide the most lift where existing behavioral signals are insufficient, such as consumers with thin engagement histories, new users, or those who have only ordered across a single vertical. For consumers with dense behavioral data, memory complements and enriches existing signals without replacing them.
We address this through two complementary encoding approaches: dense embeddings from memories and a consumer context graph that captures relational structure between entities.
Dense embeddings from memories
The first encoding approach treats all memory text as semantic signals and embeds them into continuous vector space. The key idea: If consumer memories and item descriptions embed closely in semantic space, the consumer likely prefers that item. Memory embeddings act like a high-level query expansion: "plant-forward, organic, premium fresh brands" pulls items that match those semantics even if the consumer hasn't purchased them before.
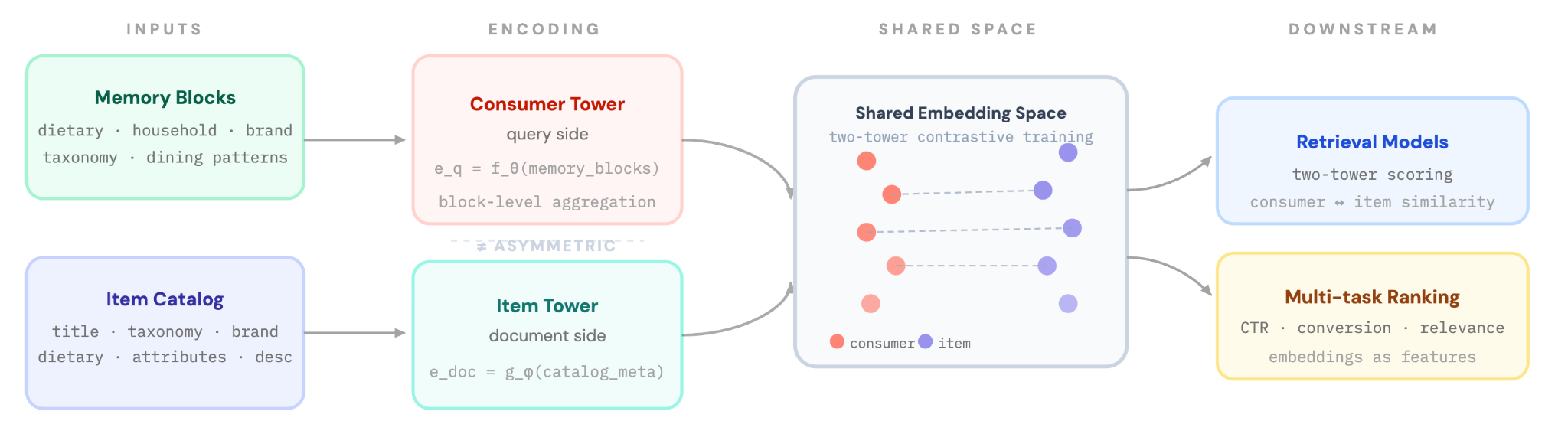
Asymmetric encoding design
We use asymmetric embedding, mapping the consumer, or query side, and item, or document side, into a shared space. Each memory block uses a block-specific retrieval instruction prepended to the consumer text, as shown here:
Instruct: Given a consumer's shopping preferences and brand affinities, retrieve items that match their preferences.
Query:Brand affinities: Strong preference for organic produce brands...
Shopping patterns: Weekly bulk buyer, premium fresh categories...Items are embedded without an instruction prefix on the document side. This asymmetry allows the model to learn that consumer profiles should retrieve relevant items rather than just matching similar profiles.
Block-level aggregation
Rather than embedding each component independently and then pooling them, we concatenate all components within a block into a single labeled text before embedding. This eliminates a pooling step and lets the model attend across all signals within a block jointly. The entire concatenated text is embedded as one unit.
Integration with ranking and retrieval models
To enable low-latency feature fetching, we train a semantic two-tower model to project the high-dimensional embedding features into a task-aligned lower-dimensional subspace as follows:
- Consumer tower: This adds together consumer block embeddings, brand embeddings, and taxonomy embeddings as input.
- Item tower: Concatenates item name, description, and category embeddings.
The same embeddings also serve as input features to our multi-task ranking models, where they complement existing engagement-based signals, as shown in Figure 2.
Memory context graph
Dense embeddings capture semantic similarity, but they don’t capture the relational structure between entities. A consumer who prefers organic produce and a brand known for organic snacks share a latent connection through the concept “organic.” But this relationship is implicit in embeddings and can be lost during aggregation.
The context graph makes these connections explicit. We build a heterogeneous context graph in which consumers, brands, taxonomies, and semantic concepts are explicit nodes connected by typed edges, as shown in Figure 3. The graph is constructed directly from memory blocks and augmented further with our internal knowledge graph. Consumer preference edges link to brand and taxonomy nodes, while keyword nodes extracted from memories form a semantic layer that bridges entities, enabling multi-hop reasoning from consumer preferences to items they have not purchased.
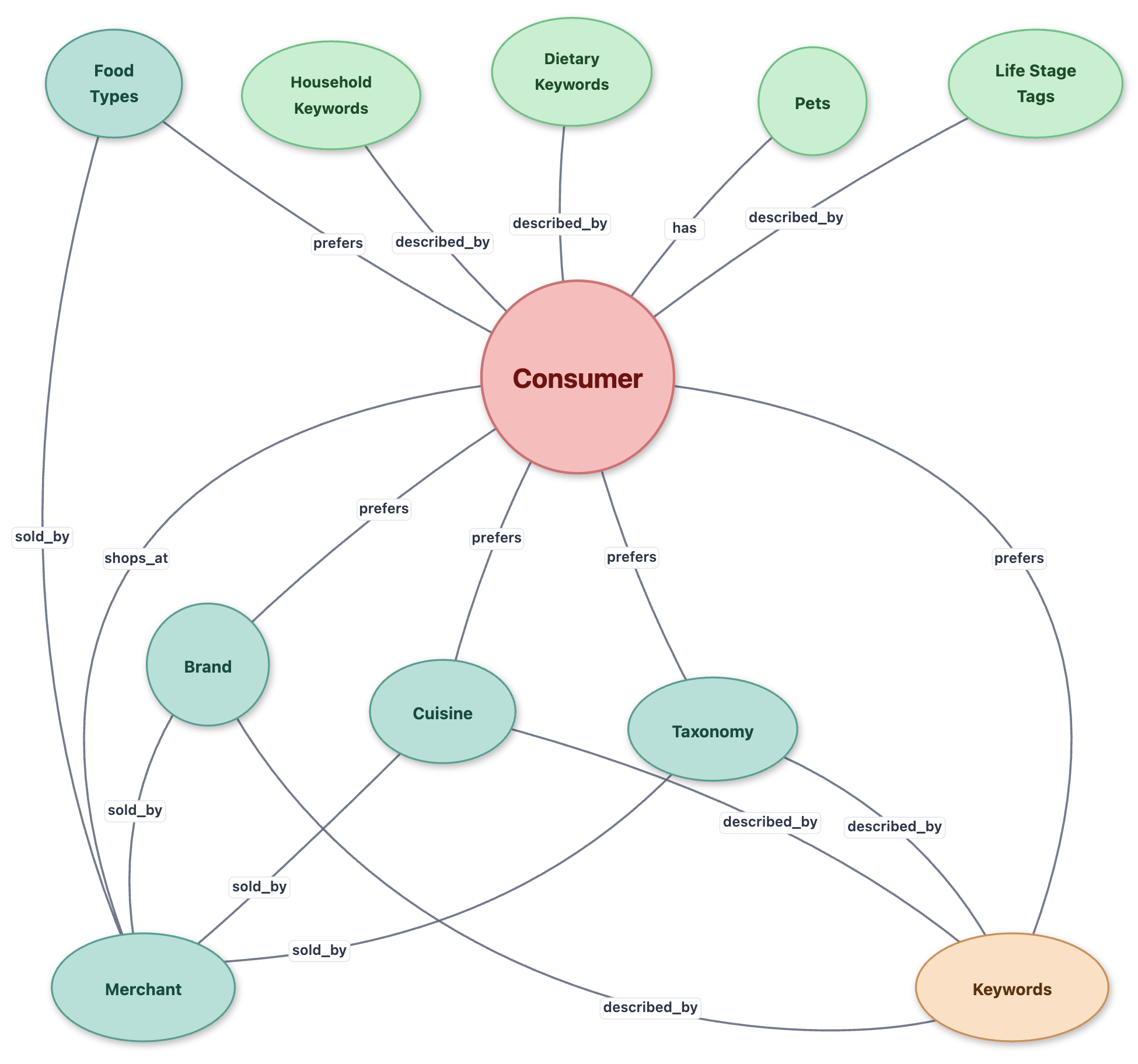
The graph provides a way to reason about relationships, such as “prefers X which implies Y,” “merchant carries preferred brands,” or “keywords connect to multiple taxonomies.” Even if a consumer has never purchased a specific category, the graph can connect them through shared attributes and keywords that propagate preference signals.
Scaling memory generation
The system operates across the full breadth of DoorDash’s consumer base, spanning multiple verticals, with a requirement to generate, encode, and serve memory within daily batch windows.
- Memory generation: The LLM-based memory pipeline runs on a cadence that varies by block type; blocks capturing quickly changing signals such as dining patterns run more frequently than blocks capturing stable signals like dietary preferences. Rather than uniformly reprocessing the full consumer population on every run, we use selective recomputation; components are only regenerated when their underlying source signals have materially changed. This is justified by the nature of long-term memory. Most consumers’ durable preferences are stable week-over-week, and regenerating unchanged components would burn LLM compute time without improving quality. Computation can therefore concentrate on active consumers with meaningful new behavioral signals.
- Embedding generation: Dense embeddings are generated for all block types via batch inference on GPU clusters. Item-level blocks have the highest cardinality because each consumer has per-entity preference records across the brands and categories with which they engage.
- Graph construction: The context graph is rebuilt on a batch cadence from memory block manifests, running downstream of embedding generation and sharing feature inputs where possible.
- Feature serving: All encodings, dense embeddings and graph embeddings, are published to the ML feature store for consumption by ranking and retrieval models at inference time. This is a deliberate design choice; serving happens from precomputed encodings rather than on-demand generation, keeping inference latency independent of the complexity of the memory representation.
How we are using unified consumer memory
Personalized collections: On DoorDash, we show store and item collections through personalized themed carousels such as “Snack Time” or “Quick Dinner Ideas.” Traditionally, these collections are curated using attribute-based definitions that are the same for every consumer. Instead, we now use an LLM to generate personalized collections for each consumer tailored to their memory blocks.
The pipeline works in two stages. Offline, an LLM reads a consumer’s memory blocks and generates personalized carousel titles and search keywords for each use case — for example “hydration, but make it zero sugar” for a consumer with a sugar-aware profile — along with search terms tuned to their specific brand and format preferences. Online, these generated search terms drive embedding-based retrieval (EBR) to fetch candidate items from the catalog, which are then ranked by existing models. To explore further, see our earlier post: “Offline LLMs, Online Personalization: Generating carousels at DoorDash”
Ranking models: Consumer memory enriches our ranking models with signals that go beyond engagement-based signals and learned embeddings. When a consumer searches for “snacks,” the ranking system can leverage their memory blocks, including brand affinities and category preferences. Memory embeddings act as a semantic query expansion; “plant-forward, organic, premium brands” pulls relevant items even for broad or ambiguous queries.
Lessons learned
- Memory blocks are a semantic matching primitive: We initially thought of memory as context for an LLM only. Our bigger realization has been that memory blocks can be used as a semantic matching primitive for ML models, too. Many personalization problems, such as item retrieval, substitution, or cross-category recommendation, are fundamentally about aligning consumer intent with catalog semantics. Memory blocks express that intent in a form that can be embedded, graphed, and tokenized.
- Extraction and encoding must be decoupled: Memory generation and encoding evolve at different rates. LLM improvements affect memory quality; embedding model and graph architecture improvements affect encoding quality. These are independent axes of improvement that happen on different timelines and require different evaluation criteria. Keeping them as independent stages connected by versioned manifests means each can be upgraded, rolled back, and A/B tested without touching the other.
- Multiple encodings beat any single representation: No single encoding captures everything. The combination of dense for semantic similarity and graph for structural reasoning captures more signal than either approach alone.
- Versioning and lineage are non-negotiable: Every component carries full lineage, including model ID, prompt hash, response hash, and generation timestamp. When a model change produces unexpected downstream behavior, we can trace through manifests for components of source signals to discover prompts that may identify the root cause. We can also reconstruct any consumer's memory as of any historical date, enabling A/B testing and rollbacks.
Future directions
- Toward personalized Small Language Models (SLMs) with memory-in-the-loop: The north star is a closed loop system in which memory retrieval feeds a personalized small language model that generates recommendations with explanations, and user feedback — such as clicks, rejections, or substitutions — can then flow back as a reinforcement signal that improves both the model and the memory over time. Memory becomes not just context for a model, but part of the optimization loop.
- Beyond token-level memory: Today, the memory platform is entirely token-level — explicit, inspectable text that is injected into prompts. This is the right starting point; it is interpretable, easy to update without retraining, and works with any foundation model. But two complementary forms of memory are emerging: Parametric memory encodes knowledge directly into model weights — for example, LoRA adapters generated from memory blocks — offering potentially better performance but slower updates and less interpretability. Latent memory maintains continuous hidden states across interactions, enabling models to internalize context without explicit retrieval. As these techniques mature, we expect the platform to evolve toward a hybrid: token level for inspectable, high-frequency updates and parametric for stable personalization signal.
- Temporal graph dynamics: The current graph is a static snapshot rebuilt weekly. We’re exploring incremental graph updates in which new behavioral signals add or strengthen edges without full reconstruction, enabling the graph to reflect preference changes within days rather than weeks.
Conclusion
Personalization at scale requires more than statistical pattern matching. It requires semantic understanding of what consumers prefer, why they prefer it, and how those preferences connect to the catalog. By extracting this understanding into structured, versioned memory blocks and encoding them through complementary representations — dense embeddings for semantic similarity and a context graph for relational structure — we have built a foundation that serves both traditional ML models and emerging LLM-driven experiences from the same source of truth.
Acknowledgments
We would like to offer special thanks to Yuxiang Wang and Fiona Miao for actively working with us on the design decisions for the platform; to Camrick Solorio, Jimmy Sindhwad, Doga Pamir, and Nachiket Paranjape for contributing to the evaluation process; and to Taoxin Jiang for helping us scale up our LLM inference infrastructure.







