

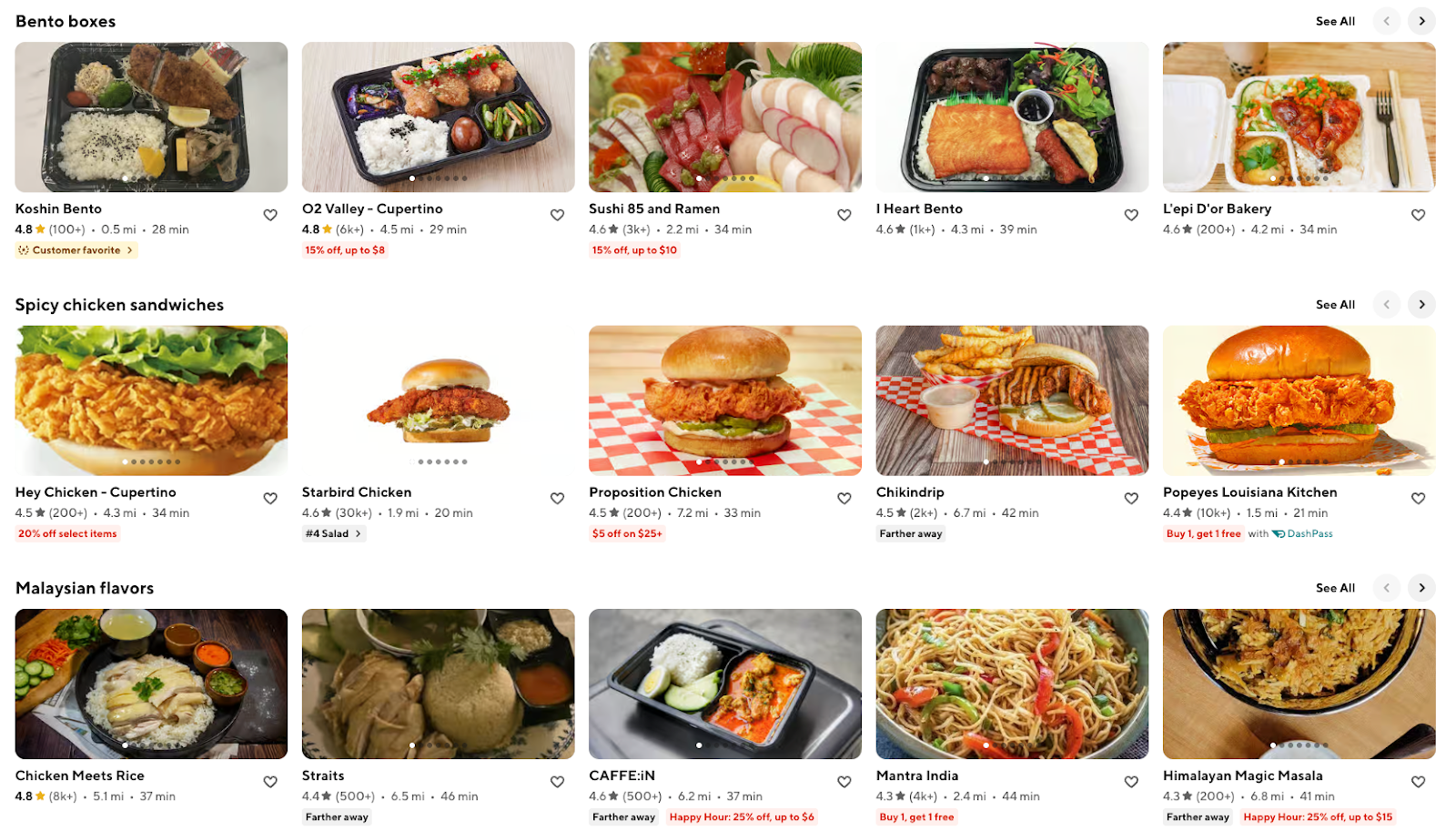
At DoorDash, we strive to deliver the best shopping experience to our customers. The homepage, which serves as the primary entry point to our application, plays a crucial role in delivering highly relevant recommendations that connect consumers with merchants. Our goal is to create a best-in-class content system that provides truly personalized recommendations, enhancing the order experience in multiple ways. With this in mind, we introduced a personalized store carousel system on DoorDash’s homepage powered by generative AI (GenAI). The new system uses large language models (LLMs) and our in-depth understanding of customers to create a unique set of carousels for each user that includes descriptive themes and metadata to power store retrieval.
The introduction of our GenAI-powered personalized carousel generation system marks a significant leap forward in creating a bespoke consumer journey. It presents a distinct and unique browsing and shopping experience for every individual user. Leveraging our extensive data on user preferences and order histories, generative AI can create homepage carousels that align perfectly with each consumer's personal needs. As shown in Figure 1, this level of granular customization reduces search issues and lets users make quicker and more informed decisions. Seamless connections to store options, related merchants, and personalized product recommendations enhance user engagement while ultimately fostering a more intuitive and satisfying platform experience.
Overcoming existing system limitations
Our original content system was based on a heuristic design that leveraged our extensive food knowledge graph (FKG) to organize content. This system featured around 300 curated carousels, categorized by popular dishes and cuisines like "breakfast burritos," "salads," and "baked goods." The system's core was built around a sophisticated matching algorithm that analyzed a user's preferences from FKG tags collected from past orders. These preferences were then cross-referenced with carousel tags to identify and select those with the highest alignment, personalizing the user's content experience.
While customers appreciated the increased variety, many still believed the carousels had room for improvement, citing the following issues:
- Insufficient concept diversity: 300 carousels proved inadequate to encompass the full spectrum of our customers' preferences.
- Overly broad and impersonal concepts: Carousels such as "Salads" were often too general and impersonal.
- Irrelevant or missing stores: Suboptimal knowledge graph (KG) tagging resulted in stores being matched to irrelevant carousels, or relevant stores being omitted.
Through analyzing consumer profiles with LLMs, we can generate highly personalized carousels. This approach summarizes customer interests to create unique carousel names and builds stores into the carousels with embedding-based retrieval. This eliminates the need for manual carousel creation and tagging and overcomes the limitations of KG tagging, which is constrained by accuracy issues and vocabulary size. LLMs allow us to include any dish or cuisine, even those not captured by KG tagging, resulting in a nearly unlimited array of personalized carousels.
Looking at the big picture
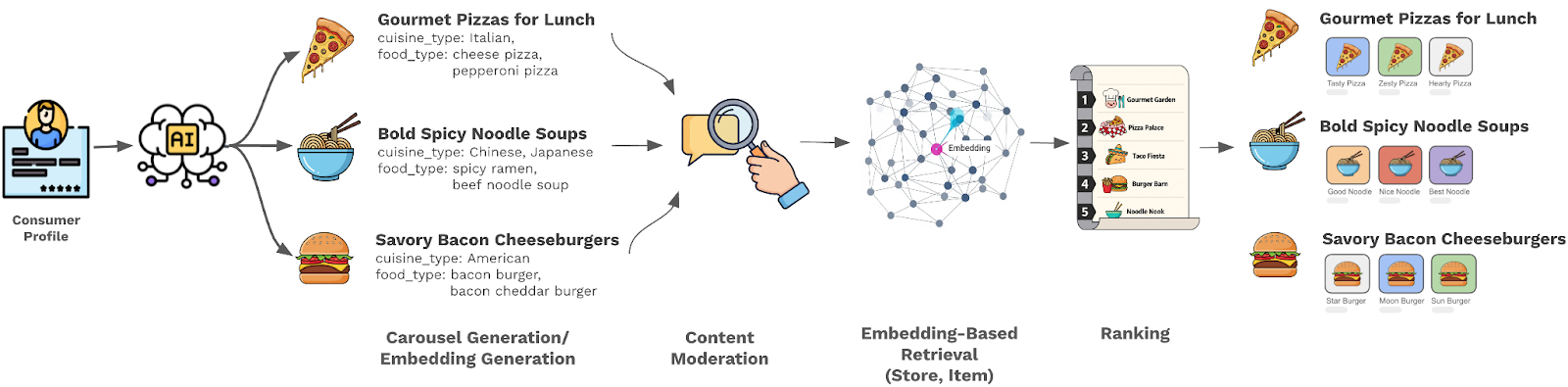
As shown in Figure 2 below, our new pipeline follows a typical bulk content generation pipeline framework. The main considerations when building the pipeline were:
- Scalability: The pipeline needed to handle millions of users globally and provide personalized content to each of them.
- Cost-effectiveness: Given the use of external LLMs for content generation, we needed to balance the expenses incurred with superior quality and frequent new content.
Our pipeline now consists of five stages:
- Carousel generation: Takes as input consumer profile and part of day — for example, breakfast or lunch — then uses the LLM to generate carousel titles and metadata
- Carousel embedding generation: Converts the generated carousel titles and metadata into text embeddings
- Content moderation: Uses LLMs-as-jury to filter violating carousel content
- Store/item retrieval: Retrieves stores and items that are most relevant to the carousel title
- Store ranking: Ranks the stores in the carousels to balance between relevance and engagement
Generating carousels and titles
We use a sophisticated LLM-powered system to generate personalized carousel titles for the homepage, driven by comprehensive consumer profiles. These profiles capture a user's unique cuisine, taste, and dish preferences, forming the foundation for highly relevant recommendations. The generation process is governed by several critical considerations to ensure optimal user experience and business effectiveness:
- Personalized relevance: The paramount objective is to align carousel titles precisely with individual user preferences. This means if a user frequently orders Italian, the system will generate titles like "Classic Italian flavors" or "Oven-baked pizzas".
- Contextual awareness (day partitioning): The LLM intelligently incorporates part-of-day and day-of-week information to suggest appropriate dining options. For instance, breakfast-themed carousels will appear in the morning, rejecting such dinner suggestions as "Steakhouse favorites" to maintain relevance.
- Topic balancing: We seek topics that are neither too specific nor too broad. For instance, "Basil popcorn chicken" might be too niche and risk missing user interest, while a broad topic like "Pasta" could be less engaging.
- Ensuring title diversity: To prevent repetition and maintain user engagement, we prioritize generating a diverse range of titles. This avoids presenting multiple carousels with similar themes, even if the underlying dishes are different.
- Exclusion of unwanted topics: We work to exclude titles for irrelevant or undesirable categories. This includes avoiding specific brand or dish names, titles focused on appetizers and side dishes, and food items not typically served by DoorDash restaurant partners. This focus ensures that all generated titles lead directly to actionable and appealing options within the DoorDash ecosystem.
We optimize our carousel titles based on continuous feedback from internal users; we discuss this further in the evaluation section below. This user-centric methodology enables us to refine prompts, integrate both qualitative user input and quantitative data, and generate titles that are more engaging, informative, and tailored to enhance the user experience.
Stay Informed with Weekly Updates
Subscribe to our Engineering blog to get regular updates on all the coolest projects our team is working on
Please enter a valid email address.
Thank you for Subscribing!
Expanding queries with metadata
Generating effective carousel titles is just the first step toward presenting relevant stores. The brevity of these titles makes them difficult to convert into useful embeddings for retrieval, which leads to suboptimal results.
On the other side of the retrieval, we deploy as the retrieval document our comprehensive merchant profiles, which include food types, cuisine categories, and dietary options. A key innovation in our process involves using the LLM not only to generate the carousel titles, but also to create auxiliary metadata for each carousel to align it with the merchant profile fields.
This approach also integrates personalization by deriving metadata from consumer preferences and order history. This transforms generic carousel titles into personalized queries, prioritizing stores based on individual user behavior, for example, presenting different types of wraps for users with Indian or American cuisine preferences, as shown in Table 1. This multi-faceted approach significantly improves the relevance and utility of displayed store selections, enhancing user satisfaction and engagement.
| Carousel Title | Metadata |
| Vegetarian stir fry | {"cuisine_type":["Chinese"],"food_type":["vegetable stir fry","tofu stir fry","mixed vegetable stir fry"]} |
| Traditional diner breakfasts | {"cuisine_type":["American"],"food_type":["pancakes","French toast","eggs benedict","scrambled eggs"]} |
| Hearty wraps | {"cuisine_type":["Northern Indian"],"food_type":["paneer wrap","chicken tikka wrap","vegetable wrap","egg wrap"]} |
| Hearty wraps | {"cuisine_type":["American"],"food_type":["chicken wrap","buffalo chicken wrap","chicken Caesar wrap","southwestern chicken wrap","veggie chicken wrap"]} |
For cost-effectiveness and scalability, we generate our prompts with Spark jobs and call LLM through batch requests.
Moderating content
As with other LLM applications, we must exercise extreme caution with generated content to prevent displaying inappropriate carousels to users. This includes titles that may violate DoorDash policies, or are insensitive/offensive, unappetizing, or conceptually incoherent. Manual review is not feasible because we generate millions of unique carousel titles.
We employ an LLM-as-jury approach to scale the review process. This begins by prompting three different LLMs with our review criteria and then subjecting their independent decisions to a veto process. If any juror LLMs find a title to be in violation, it is automatically blocked. This moderation process gives us 95% recall on detecting the bad titles.
Retrieving stores and dishes
For each carousel generated, we retrieve the most relevant stores, and for each store, an image that aligns with the carousel's title. The latter is achieved by finding the most relevant dish to the carousel within the store.
After the carousel title and metadata are generated, they are concatenated into text and converted into embeddings using LLM text embedding models. Similarly, JSON-formatted merchant and dish profiles are turned into embeddings for retrieval by the same model. This creates two k-nearest neighbors (KNN) queries: First, to identify stores with the highest cosine similarity within the delivery radius, and second, to find the dish with the highest similarity to the query within each selected store.
Instead of a typical approximate nearest neighbor approach, we perform an exact KNN search on GPU. Pre-generated masks — for example, deliverable stores for different geolocations or items within each store — and document embeddings are stored in GPU memory. For a query with a corresponding geolocation, we perform matrix multiplication to calculate cosine similarity between the query embedding and the unmasked document embeddings, then pick the top K results, enabling low-latency online retrieval of stores and dishes.
Determining ranking and presentation
After the carousels are generated, we leverage the existing carousel serving framework to serve the carousels with the information retrieved. This gives us a modular and configurable way of presenting the carousels to users.
Once candidate stores are retrieved, we leverage our existing store ranker to determine the order in which the stores will be displayed within each carousel. This model is optimized around engagement signals such as click-through rate or conversion rate. Starting from this baseline ensures that the slate respects the same quality and guardrails that already power our homepage experience.
While we don’t yet have enough training data for the ranker to learn about the new embedding similarity score, we can better represent the retrieval relevance and the baseline model through layering in a block re-ranking step that leverages the re-ranking module in the carousel serving framework. The ranked list is partitioned into blocks of size K; within each block, we reorder stores by a weighted blend of the ranker model and the embedding similarity between the carousel’s representation and each store’s embedding.
FinalScore(s) = R(s)^α · S(s)^β
Here, R(s) is the engagement-based ranker score, S(s) is the similarity score between the store and the carousel, and the exponents α and β act as tunable weights.
This multiplicative design means that a store only rises to the top if it performs well on both dimensions, striking a balance between engagement and relevance. In addition, the blocked re-ranking design gives us a flexible baseline for experimentation and an incremental path toward a fully learned ranker.
Evaluation and experiment results
During system development, we conducted two types of offline evaluations:
- Carousel and user relevance: This evaluation assessed whether the carousel was relevant and engaging to a specific user. This was inherently subjective and could only be done by the target user. To accomplish this, we created a panel of internal users who score carousels based on such criteria as repetition frequency, specificity, diversity, and relevance. We then used this feedback to iterate on our prompt.
- Carousel and store relevance: This evaluation, scaled using third-party labelers, objectively determined the relevance of stores fetched for the carousel. We provided carousel-store lists to these labelers, who scored the relevance based on predefined criteria while we monitored the precision@K metric.
These two evaluations helped us refine our prompt and store retrieval strategies, leading to an improvement in our precision@10 metric from 68% to 85%.
For A/B tests, we launched the new content system in two of our biggest submarkets: San Francisco and Manhattan. Early results show double-digit click rate improvement; conversion rates and homepage relevance metrics also are improving, indicating that the homepage is becoming more sticky and relevant with fewer consumers bouncing off. The new system also drives greater exploration and merchant discovery by exposing customers to more cuisines and new merchants, which is not only driving merchant trials but also small and mid-sized business (SMB) volume.
Future work
Our GenAI content system has shown promising results, and we are committed to further enhancements. One key area for improvement involves broadening the scope of our carousels. Currently, we focus on taste preferences, offering cuisine and dish recommendations. In the future, we plan to expand into other dimensions, such as affordability, speed, and non-restaurant shopping, including groceries, to better help customers find what they need.
We also plan to enhance the LLM used for profile and carousel generation. While off-the-shelf LLMs can use their world knowledge to understand customer preferences and recommend topics effectively, they lack DoorDash-specific insights. Among the insights we would like to deploy are co-purchase patterns, regional customer preferences, and store performance on our platform. By fine-tuning our model with DoorDash's proprietary data, we can integrate this knowledge with existing world knowledge to deliver even more precise recommendations to our customers.
Acknowledgements
We are deeply grateful to our entire Core Consumer organization for advancing the GenAI effort for our consumers. Specifically, we extend our gratitude to the following teammates:
- Engineering: Zhenzhen Liu, Xiaochang Miao, Heather Song, James Zhao, Dipali Ranjan, Michael Chen, Yu Zhang, and Anish Walawalkar for your insightful discussions and collaborations on foundations.
- Leadership: Chunlei Li, Eric Gu, Ujjwal Gulecha, Qilin Qi, Mauricio Barrera, and Parag Dhanuka for support and guidance along the way.
- Product and S&O partners: Spring Ma, Parul Khurana, Aliza Rosen, and Kunal Moudgil for the fruitful collaboration on prompt tuning and evaluation.








