

DoorDash provides an engaging internship program where software engineering interns are deeply integrated into our Engineering teams, allowing them to gain practical, real-world experience that complements their academic learning. This is one of two posts that showcase the exciting projects our summer 2024 interns developed. Their work not only reflects their problem solving and technical skills but also plays a meaningful role in driving innovation at DoorDash.
Preventing Ad Overspend: Improving budget pacing algorithms
By: Rohan Garg
DoorDash's advertising platform, which aims to show the right user the right ad at the right time, lets advertisers consistently connect with consumers. Restaurants, for example, can specify an advertising budget for their campaigns and our platform can dynamically determine how that budget should be best spent throughout the day. Without pacing a campaign's ad spend in this way, it is possible to deplete the entire budget early in the day. Restaurants then would get fewer orders during the dinner rush, hampering their ability to compete on the platform. This problem is known as budget pacing; in this post, we discuss how we improved our budget pacing system through mitigating severe over-delivery.
The challenge
When a consumer clicks on an advertisement, we charge that advertiser an ad fee. This fee is taken from the advertiser's daily budget - their monthly budget is split evenly across all days. Because of daily fluctuations in user traffic, however, we also set our own spend goals that can vary from day to day. Once the spend goal is hit, we stop serving ads for that advertiser. We can still bill advertisers up to double their daily budget because of an agreement made between DoorDash and advertisers. This gap allows for some overspending, up to the billing cap, after the pacing goal has been achieved. Overspend occurs when a consumer clicks on an ad before the daily spend goal has been reached, but then fails to place an order until after that goal is reached. This is called delayed attribution. If too many orders contribute to this delayed attribution, we spend past our daily goal, resulting in ad overspend.
Consequently, even if a campaign is no longer served in auctions, it can still be charged because of an earlier ad impression. This is particularly severe for enterprise campaigns (sometimes more than 20%), as they attract a large number of consumers and tend to have high conversion rates.
Although we aim to minimize ad overspending, we must be careful not to throttle spending so much that we cause underspending. Our current method to prevent this is to switch from an algorithm that carefully paces spending for most of the day to one that deliberately spends the remaining amount up to the daily goal as efficiently as possible for the last few hours of the day. This mechanism is called fast finish, or FF. Technically, if a campaign has not reached the daily spend goal at certain hours, we immediately stop any pacing or throttling. This causes a sharp rise in ad spend, as shown in Figure 1. As a result, high-quality campaigns show a big spike in spending right after the FF period - a negative experience for our advertisers. Our goal in this project was to iterate on our intraday pacing system and the fast finish lever so that we can minimize overspending while avoiding underspending.

Improving budget pacing algorithms is a key challenge for DoorDash and its industry in general. If we do not pace budgets well, we can encounter unstable impression counts, reduced revenue for DoorDash, and blackout days in which an ad campaign gets no ad impressions for many days at the end of the month.
Sizing up the problem
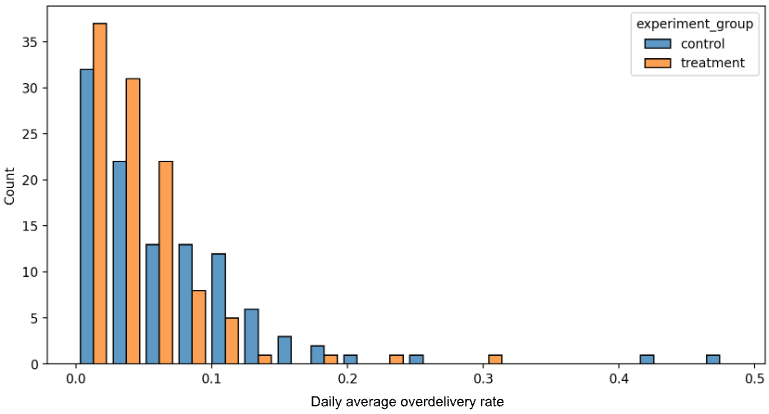
To understand the business opportunity as well as the severity of advertiser overspend, we spent a week doing a deep dive into the ads platform data. For the last week of May 2024, enterprise ad campaigns experienced about 11.5% overspending beyond goals for the week. Because budgets can be depleted earlier in the month, we studied spending data for the first week of June 2024 as well. The data showed that in the first week of June, enterprise campaigns saw nearly 25% ad overspend. The data was clear - many advertisers were struggling with severe ad overspending.
Developing a new approach
Our solution was to use campaign-specific parameters to modify various properties of the fast-finish logic. Using campaign-level overspend data, we varied the time that fast finish started and the rate at which ads were throttled.
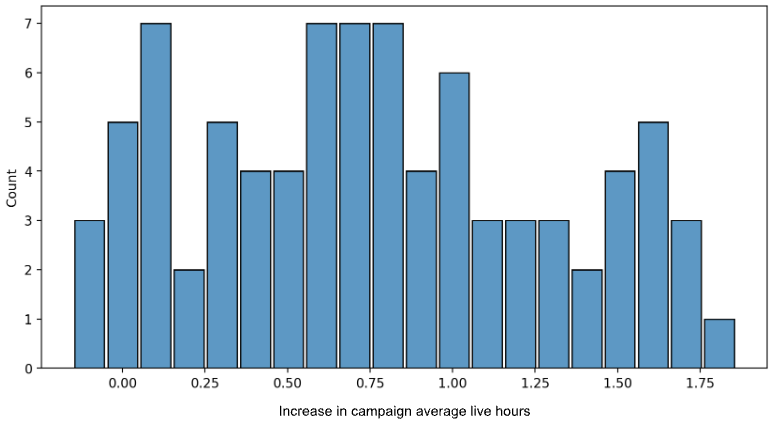
Our first approach dynamically adjusted the fast finish time for any campaign in which there was high overspend. The thinking behind this was to allow our intraday pacing algorithm more time to serve the campaign. By allowing more time for the daily spend, we would likely hit the goal before we would need to trigger fast finish, leading to fewer delayed attributions. In simulations, we saw this approach increase daily campaign live hours by as much as 6%.
Our second approach changed the urgency level for switching from intraday pacing to fast finish. Instead of immediately dropping the probability of throttling an ad to zero, we slowly dropped it to zero over a set period of time, for example an hour. By slowing the drop of the throttle rate, we hypothesized that we could smooth the number of orders as we approached the daily spend goal. We believed this could lead to fewer delayed attributions as well. In simulations, we saw this approach increase daily campaign live hours by as much as 3%.
Our third approach simply combined the first two approaches. Ideally, pushing back the fast finish start time would increase campaign spendable hours; the transition window would smooth the spend curve, resulting in fewer orders with high delayed attribution. In simulations, we saw this approach increase daily campaign live hours by as much as 8.2%.
Tackling technical challenges
Three primary technical challenges occurred during this project.
The first revolved around designing the algorithm to push back the fast finish start time. We needed this algorithm to be robust enough to adapt to our changing input parameters, including the latest desired fast finish start time. We also needed the algorithm to output smooth behavior, for example no large jumps in the fast finish start time if a campaign started to experience more overspend. We were able to solve this problem by carefully selecting a smooth non-linear function that mapped historical data values to fast finish start time values.
Our second challenge stemmed from concern that our initial ideas were subject to a positive feedback loop that could cause unstable behavior. Essentially, we were using historical data to influence our algorithm, but over time the algorithm would influence the data, creating a feedback loop. We solved this problem by adding extra guardrails around our algorithm's output.
The third issue involved the many nuances in engineering the algorithm and integrating it with our ad exchange service. For now, our pacing logic is embedded in the main service and there is a limited latency budget. Consequently, we put in extra effort to optimize the implementation carefully through parallelization and caching, e.g., some inputs to the algo do not change within the day and thus are cached locally to reduce latency.
Finalizing a solution
After simulations and online experimentation, we ultimately selected the third, combination approach, which includes:
- Introducing a transition window between intraday and fast finish, probabilistically throttling X% requests when spending is faster than expected before reducing to 0% throttling
- Incorporating a dynamic FF start time based on campaign spending history
As a result, our new intraday system is composed of three stages over the course of each day: intraday, transition, and fast finish.
We conducted a one-week online A/B experiment that demonstrated the power of our new algorithm, as shown in Figures 2, 3, and 4, including:

Conclusion
In conclusion, we took a deep dive into over-delivery, brainstormed various solutions, and conducted simulations on our top three ideas. Based on our simulated results, we implemented our solution in production and measured its ability to mitigate over-delivery. The end result improves our ability to pace advertising budgets and improves the advertiser experience on the platform. Improving budget pacing moves DoorDash's advertising platform closer to its ultimate goal: Delivering the right ad to the right user at the right time.
Identifying the main active device for dashers using multiple devices
By: Thao Nguyen
During my summer internship, I worked to improve how DoorDash logistics domain tracks Dasher locations. About 10% of Dashers use more than one device during a shift, which can lead to issues if locations from different devices report conflicting information, such as varying locations between devices.
It is crucial to know which of a Dasher's various devices are authenticated and should be used in location tracking. This is important because some devices might be unintentionally activated, such as when a family member accidentally opens the DoorDash app from a different location and leaves it running. In a more troubling scenario, a malicious former Dasher, banned because of poor performance, might attempt to exploit this system vulnerability to earn money illegally - a situation that DoorDash, our customers, and our merchants would all want to avoid.
My project aimed to identify the primary device to know where each Dasher is, what they are doing, and if any suspicious activity is occurring. Determining the primary device also ensures that only reliable location data is used by downstream services, thereby reducing consumption of noisy data from multiple devices.
Implementation
This project used Apache Flink, a powerful stream-processing framework, to enhance the accuracy of Dasher location tracking.
The new service I developed processes raw location data streams from an existing Kafka topic that is continuously updated with Dasher collected from the Dasher mobile application . My project added a key feature: An `isFromMainDevice` field that indicates whether a particular location report originates from the Dasher's primary device. After a series of logic checks on the location data, this field is set to true or false. Such checks include, among others, filtering out accidentally activated devices, applying production configurations, and identifying duplicate records. To accurately identify the main device during this process, I collaborated with another internal service that specializes in account compliance and fraud detection. By leveraging this service's dedicated databases, sophisticated logic, and thorough testing, I was able to ensure that the system correctly identified the primary device, thus enhancing the overall reliability and efficiency of the location-tracking process.
After processing, enhanced location data records are pushed to a new Kafka topic, where they are ready for consumption by downstream services such as assignment, order-tracking and geo-calculation.
Impact
This project significantly improved the accuracy of Dasher location tracking by identifying and prioritizing data from each Dasher's primary device. More reliable location reports contribute to reducing system abuse issues and enhance the overall efficiency of downstream services. The refined data now helps DoorDash make better assignment decisions and improves the accuracy of geo-calculations, ultimately contributing to a more reliable and secure platform for Dashers, merchants, and consumers alike.
Applying vision transformers to detect and prevent photo recycling fraud
by Anastasiya Masalava
Like many customer-facing companies, DoorDash establishes a variety of algorithms to detect and prevent consumer fraud. During my summer internship, I worked on developing a solution to curtail photo recycling fraud - a scheme in which a consumer submits duplicate or slightly modified (scaled or rotated) images to request multiple refunds from different deliveries. Consider the following two refund request images:

These images were submitted by the same customer as evidence for two refund requests related to two different deliveries. These requests should be flagged as image reuse to prevent refunds. However, it is challenging for human agents to spot such duplicate images through manual searches in the database. This kind of situation calls for an automated duplicate image detection system.
Selecting a robust algorithm
The first basic solution for duplicate image detection would be a SHA-256 hashing algorithm, which can compare the fingerprints of two image files to detect exact duplicates. But this solution cannot detect any image transformations such as rotation or scaling; any slightly modified images will not be identified as duplicates.
To address these limitations, I implemented a perceptual hashing algorithm - P-hash - designed to withstand minor image modifications such as compression, color correction, and brightness. I used hamming distance to detect similarity between two images, which measures the minimum number of substitutions required to change one hash string into the other. Although P-hash offers a good way to detect slightly duplicate images, it has a limitation: It tends to fail when image alterations significantly affect pixel patterns, for example, in the presence of rotation or scaling.
To make the solution more robust, I deployed a vision transformer, or ViT, deep learning model, which applies transformer architecture to computer vision tasks. Duplicate images can then be found in three steps, as shown in Figure 1.

First up, the ViT's encoder computes dense representations — embeddings —of images to compress high-dimensional pixel images into vectors, preserving information about the image. These embeddings are then used to compute pairwise cosine similarities between images; potential duplicate image pairs can be retrieved if their cosine similarity is greater than the threshold.
The biggest advantage of this algorithm is ViT's ability to understand the general context of images, improving its performance in identifying similarities.
Assessing performance
To discern the optimal solution, I created a testing dataset of image pairs and ran three experiments. The vision transformer algorithm outperforms SHA-256 by 52%, P-Hash by 1.3% as measured by F1 score, a balanced measure that reflects both the false positives and false negatives.
Impact
Experiment readout indicates that the Dup Photo detection can bring upwards of $0.6M annual savings. With the expansion of more use cases, the impact can be further increased. Over the course of my internship, I implemented an automation node to flag new refund requests if any duplicate image pairs have been detected in a consumer's previous requests. This solution can significantly reduce time spent on reviews and can minimize losses from photo recycling fraud.
Why DoorDash needs a server-driven UI with mosaic
By: Yufan (Joy) Xiao
Traditionally, a mobile app's user interface, or UI, is defined within the app itself on systems such as iOS or Android. This way, the app receives data from the backend to update text values and other content in its UI components. However, this approach creates two challenges to updating the UI:
- Delayed release cycles: Updating the app's UI requires releasing a new version of the app. This process can take several weeks to get approval from app stores, increasing the time to release.
- User adoption lag: Even after a new version is published, users may not immediately update their app, limiting the reach of new features and UI improvements.
Mosaic, DoorDash's standard server-driven UI, or SDUI, framework offers an effective solution to these challenges by moving the UI definition to the backend, making the mobile app responsible only for rendering the UI components. Using Mosaic, we can change the UI simply by updating the backend response. These changes take effect as soon as the mobile app receives the updated response, significantly reducing the need for app version updates. Figure 1 below demonstrates a key difference between what's being transferred between frontend and backend.

Why we need pagination
Some services need to return large amounts of information in response to user requests. For example, when a consumer visits the DoorDash homepage or searches for stores, the service might find more than 1,000 stores. Loading all of them at once would cause significant latency, negatively impacting the user experience.
Pagination allows us to break down large data sets into smaller chunks that are returned on demand. It's crucial to integrate pagination functionality into Mosaic to handle large data sets efficiently without compromising performance.
Implementation overview
Data flow (homepage example)
Below describes a series of steps of how a client sends a request to backend and gets back a paginated response via Mosaic. Figure 2 shows its sequence diagram.
- Client: Sends a representational state transfer, or REST, request to the unified gateway, including the parameters needed to process the homepage and a page token for pagination.
- Unified gateway: This is DoorDash's internal tool that converts REST requests into Google remote procedure call, or gRPC, requests. Responses are then transformed back into REST responses.
- gRPC service: Processes the request and generates a Mosaic contract, which is included in the gRPC response.
- Data source: This is where the gRPC service retrieves data requiring pagination. Data sources could include a database, downstream services, or THIRD OPTION, among others.

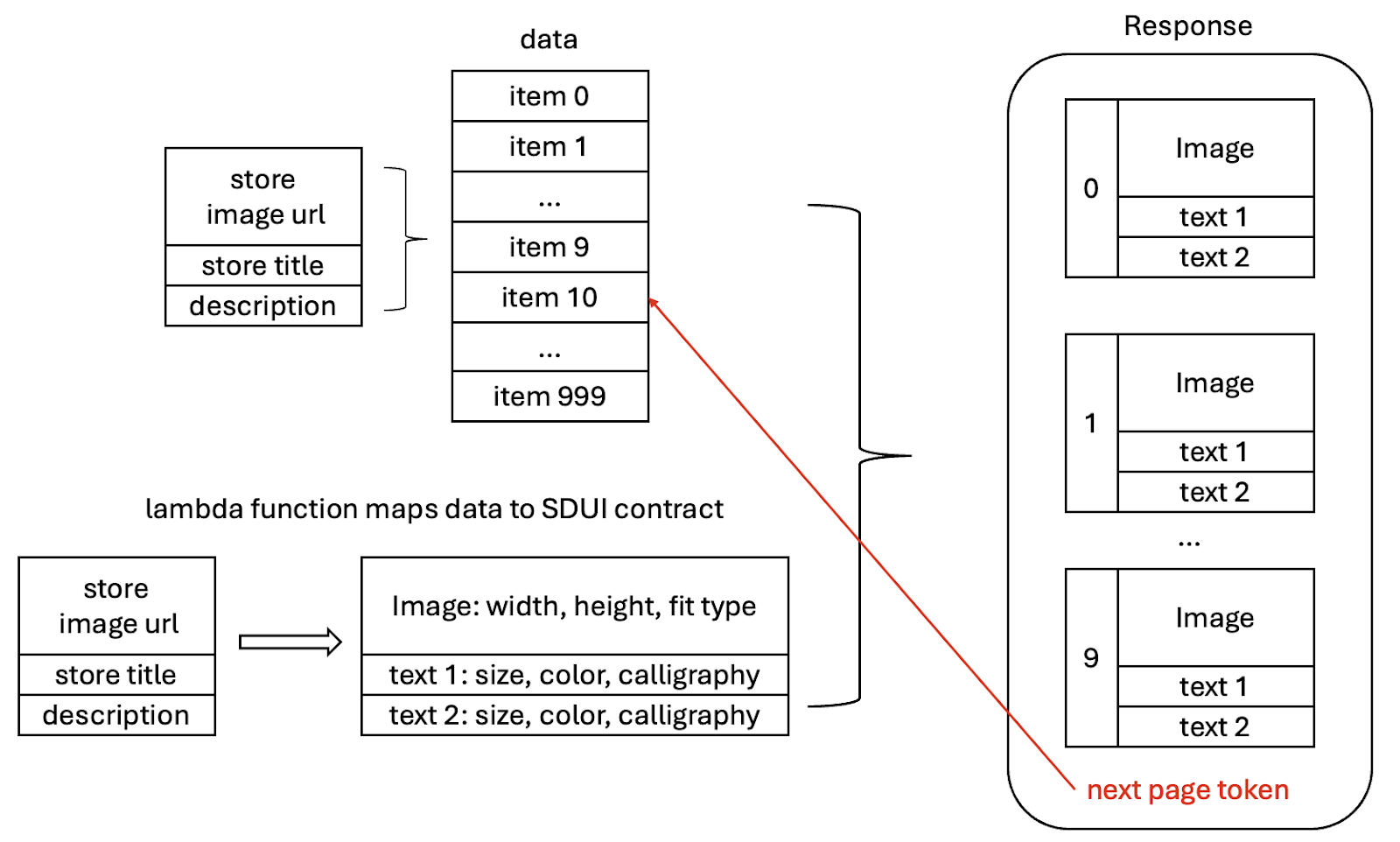
Converting backend paged data into Mosaic contracts
In the backend service, we define a lambda function that converts each data item into a group of UI components. These UI components, such as text, images, buttons, or tooltips, already are defined in Mosaic.
The backend response includes groups of UI components along with a page token to indicate the starting point of the next page. The client uses this page token for subsequent requests as seen in Figure 3.
Rendering UI in the Android mobile app
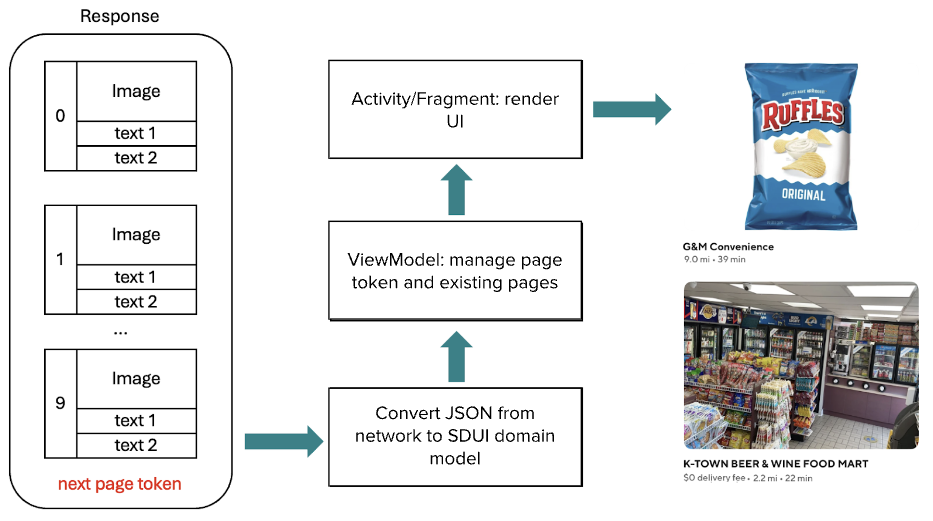
As seen in Figure 4, after the mobile app receives the REST response in JSON format, Mosaic library converts it into a domain model. Android ViewModel then manages the page token from the domain model and maintains existing pages. The ViewModel is binding with an Android activity or fragment, which renders the UI with Mosaic.
Impact
This project significantly accelerates adoption of the Mosaic framework across DoorDash, especially enabling the feed service to migrate to the new SDUI framework.
With pagination functionality, Mosaic not only supports a robust and flexible development environment but also offers a more scalable SDUI strategy, enhancing overall application performance and user experience.
Enhancing transparency and efficiency with DoorDash personalization debug tool
By: Shanting Hou
During my internship at DoorDash, I worked with the New Verticals, or NV team to develop a personalization debug tool to enhance operator transparency and significantly reduce debug time for engineers. Our solution contributed to the overall efficiency and reliability of DoorDash's retail and category pages.
Improving tool understanding and debug efficiency
The NV team, particularly members focused on customer experience and product personalization, were grappling with inefficiencies in their outdated web debugger tool. The tool was not equipped to handle the growing complexity of retrieving essential information such as machine learning, or ML, prediction scores and personalized insights, which are crucial for testing ML features and responding to cross-functional team inquiries. Team members frequently had to rely on engineering support to diagnose and resolve issues, including limited item visibility, discrepancies in personalized content, mismatches between displayed deals and user preferences, and understanding the algorithm's ranking logic. This dependency on engineers not only slowed operational processes but also hindered team autonomy and led to inefficient debugging procedures.
Building a comprehensive solution
To address these challenges, I was tasked with revamping the debugging tool. First, I dived deeply into the tool's current use cases, discussing issues with ML and back-end engineers responsible for the ranking algorithm. I sought to identify the most critical features that needed to be logged to streamline the debugging process as well as to visualize the ranking logic more effectively. Primary challenges involved deciphering the ranking logic's intricate flow and the logging information design. Both required navigating complex system logic and comprehending ongoing experiment values to pinpoint the ranking algorithm's core stages. With the guidance of engineers Yucong Ji and Anthony Zhou, I was able to overcome these challenges and develop a clear understanding of the algorithm.
The next step required translating this technical logic into terms easily understood by both engineers and operators, which involved categorizing different ranking steps into their possible outcomes. I discovered, for instance, that the pinning settings for carousels could leave them in one of three states: unpinned, pinned to a given range on the page, or fixed at a specific position. To ensure clarity, I documented the logic of the logging fields in a comprehensive wiki.
But the logging fields by themselves wouldn't be effective unless they directly addressed user pain points. By analyzing confusion and errors reported on the team's Slack channel, I identified specific concerns and determined what logging information would be most valuable. As just one example, we added carousel order logging information to increase transparency in the ranking stages, which helped to pinpoint where errors occurred. To make the tool user-friendly, we displayed the logged values in an accessible manner. The main debugging information was clustered into two key modals, separated by carousels and items. Additionally, we made modifications to retailStorePageFeedQuery to reduce latency, adding an enableDebug field that would pass from the front-end to the back-end. Consequently, debugging information was only retrieved when needed, ensuring optimal tool performance. The result was a robust tool that allows team members to view relevant debugging information directly on the live DoorDash site by simply toggling a debug button. Figures 1 and 2 below show examples of the new debug modals.
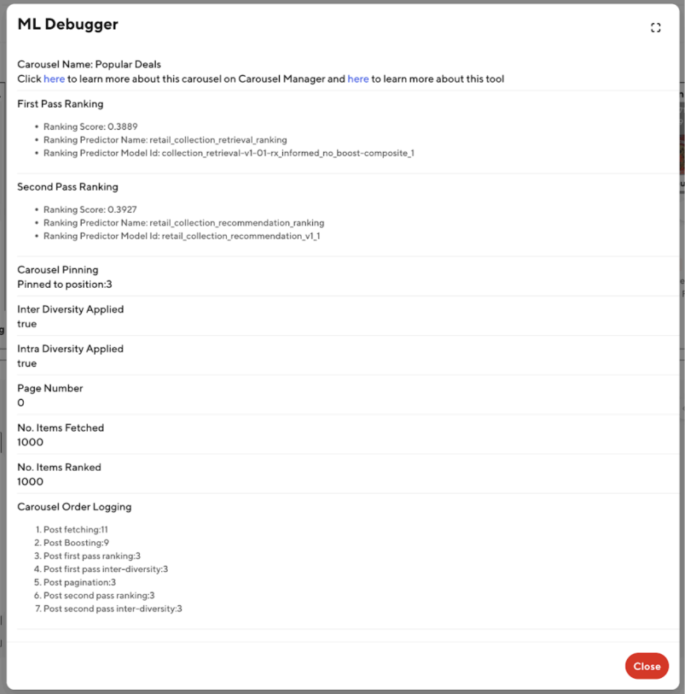
Shows key details of each step in vertically ranking item Carousel on the page to allow easy debugging of any ranking-related inconsistencies. For example, the ranking scores/ML models used to rank this carousel as well as the position of the carousel after each step in the ranking process.
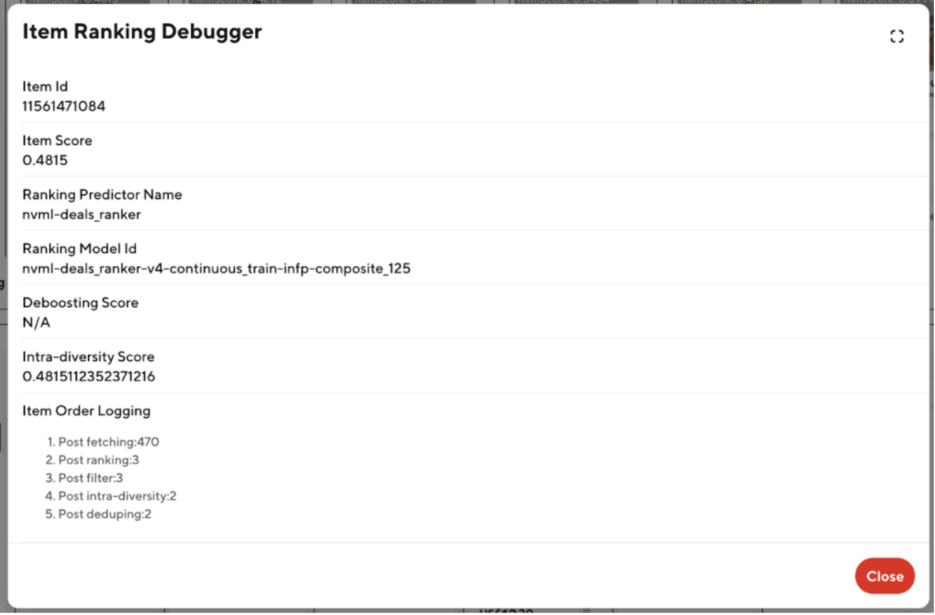
Shows key details of each step in horizontally ranking items within a carousel to allow easy debugging of any ranking-related inconsistencies. For example, the ranking scores/ML model used to rank this item as well as the position of the item after each step in the ranking process.
Transforming the debugging process
Implementation of the personalization debug tool significantly impacted both the NV team and DoorDash as a whole. The tool reduces the time required for back-end engineers to debug issues by up to two hours, moving engineers away from manual debugging through the ML platform. This not only saves valuable engineering time but also improves the overall efficiency of answering cross-functional partner queries and testing new ML models. In the final weeks of my internship, I focused on enhancing the tool's extensibility and long-term maintainability. I implemented functions that back-end engineers could use to log carousel/item position changes and other crucial features efficiently. I also modified the front-end to adapt seamlessly to new back-end changes, ensuring that any logging or feature information that was added would be reflected automatically without requiring further adjustments. I also investigated using tree metrics for detailed, per-query insights that could enable alternative approaches to overcome potential challenges, such as increased latency and complex logging.
Overall, the personalization debug tool has empowered DoorDash's NV team to maintain effective debugging practices, improve transparency for operators, and ensure the platform's continued reliability and efficiency. This project stands as a testament to the impact that a well-designed tool can have on a large-scale, distributed system.




