

Many engineering orgs have tried bolting AI reviewers onto their pull requests (PRs). Too often, those reviewers get ignored. The comments are noisy, the suggestions are generic, and engineers learn to scroll past them.
We wanted something different. Over the last few months, we've been rolling out a code review agent across DoorDash's engineering org. The central challenge turned out to be attention: helping the agent focus on the parts of a change that deserve review, and stay quiet when it has nothing useful to add.
The bar we set for ourselves wasn't "does it find things." It was:
- Do engineers actually change their code when it comes up with a comment?
- Does it preserve enough trust that teams keep it enabled?
Here's where we've landed.
The numbers
In a typical week, the agent reviews more than 10,000 pull requests across 56 onboarded repositories: Go backend services, iOS and Android apps, web frontends, infrastructure, data pipelines. Many reviews fire automatically when a PR is opened; engineers don't have to ask for one. The agent runs on the same PRs as human reviewers, often before a human has looked at the diff.
A few things we measure:
- 60.2% of settled high and critical findings result in the engineer changing code before merge (n=2,256), up from a 46% acceptance rate with our previous third-party review agent. We measure this on if the human acted on it or not.
- Webhook-triggered findings are accepted at 59.0%. That matters because these are not cherry-picked manual invocations. The agent runs automatically, on real PRs, and still produces comments engineers act on.
- A review costs roughly $3 on average today. Similar deep, agentic code review products with remote execution, repository access, and verification are publicly priced around $5 to $20 per review, depending on change size.
- The agent posts findings about 7 minutes after a PR opens on average, usually before the first human reviewer has looked at the diff. Most engineers see the comment while the change is still fresh.
These numbers hold up across very different codebases. Acceptance on a Go backend repo looks similar to acceptance on an iOS repo, which looks similar to acceptance on a web frontend. The agent is not optimized for one stack. It is optimized for a specific balance: catching critical issues without spamming authors. In practice, that means commenting only when the claim is specific, grounded, and likely worth the author's time.
How we got here
The current system is the third version. The evolution is worth understanding, because each step taught us something we couldn't have predicted from the previous one.
v1 was a fan-out of focused specialist agents: one for security, one for tests, one for performance, one for code quality, and so on. Each agent had a narrow scope and a specific checklist. This was good at catching mechanical bugs like missing nil checks, unhandled errors, and obvious test gaps. But it kept missing the architectural issues: a refactor that quietly changed a contract, a new abstraction that didn't fit, a deletion that broke something three repos away. Specialist agents don't see the bigger picture, because none of them are looking at it.
v2 introduced two parallel general-purpose reviewers that each saw the whole change. They were better at catching architectural and cross-boundary issues because they had the context to reason about how the pieces fit together. But each reviewer had too much to do in a single session: read the full diff, evaluate it against all the rules that applied to the changed code, trace callers, check sibling implementations, and verify every potential concern. Attention spread thin across the change, and real findings sometimes got lost. We were leaving critical issues on the table not because the reviewers couldn't catch them, but because the system had not decided what deserved deep investigation.
v3 added the lead scout in front of the reviewers, and this is the change that mattered most. The lead scout's job isn't to verify anything. It just reads the diff and notices things that feel off: "this deletion looks suspicious," "this enum case isn't handled in the sibling file," "this error path is silently swallowing failures." It produces a list of investigation leads. The two deep reviewers then take those leads and dig in, verifying the ones that hold up and dropping the ones that don't.
The scout does two things at once. The obvious one is what it produces: a list of suspect spots in the diff. The less obvious one is what it filters out: the parts of the change that don't need scrutiny. By the time the deep reviewers run, they're not trying to evaluate every line. They're focused on the handful of places where something might actually go wrong, with the rest of the change as supporting context. That focus is what lets them go deep enough to find architectural issues that v2 was missing.
This is closer to how senior engineers actually review code. They don't exhaustively verify every line. They notice a hunch, or a pattern they've seen go wrong before, and then dig into the parts that warrant attention. Splitting noticing from verifying let us go deeper on the things that matter without spreading attention thin across the things that don't.
That became the core product lesson: code review agents don't fail only because models make mistakes. They fail because they spend attention poorly and spend trust too quickly.
At a high level, the review pipeline now looks like this:
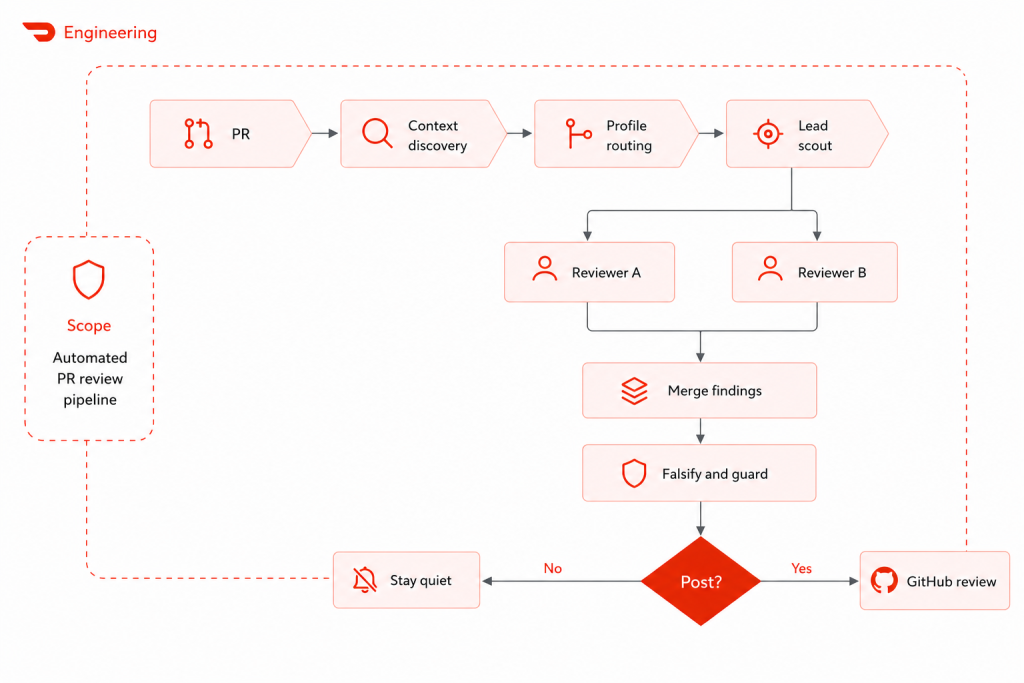
The point was not to make the agent review exactly like a human. Human reviewers are better at intent, taste, and deciding whether a tradeoff is acceptable. The agent is better at patient, repetitive attention: checking deletions, tracing callers, comparing sibling implementations, and applying domain rules consistently. The useful system is the combination, with AI covering review paths humans predictably skim.
The design principle: precision over recall
The single biggest decision in building this was refusing to optimize for "catch everything." The common approach is to surface every possible concern, rank them, and leave the filtering to the human. The cost of that approach is predictable: PR spam, muted notifications, ignored comments.
We went the other way. Before any comment is posted, it has to survive a disprove-it pass, an explicit step where the system tries to falsify its own finding. If the claim can't hold up to scrutiny, it gets dropped.
A few consequences of that:
- The agent posts fewer comments than a naive approach would
- The comments it does post are anchored to specific lines with quoted evidence
- Engineers trust the signal enough to enable it on their repos without being mandated to
The 60% acceptance number is the output of that tradeoff. We'd rather miss some issues than become noise. A reviewer that's muted catches nothing.
The issues we care most about are rarely impossible for a human to understand in isolation. They are hard because they require the right context at the right moment: knowing which deletion changes a contract, which enum has sibling mappings, which domain rule is not in CI, and which plausible concern is actually harmless. The system's job is to make those judgments consistently across thousands of unrelated PRs without flooding authors with guesses.
Focused context beats more context
The standard approach to AI code review is to dump as much context as possible into the model: the entire AGENTS.md, the full diff, maybe the repo's README. Then you hope it notices the right things. We found this produces confident-sounding reviews that miss the specific things that actually matter.
The insight that changed our results: AGENTS.md and CLAUDE.md files are written for engineers authoring code, not engineers reviewing it. They mix architectural guidance, setup instructions, coding patterns, and style notes into a single document. Useful for writing. Noisy for reviewing.
So we built a different layer: per-domain review profiles that capture only the things a reviewer needs to know. Each profile is mined from four sources:
- AGENTS.md files, scanned for invariants and conventions, but only the subset that's review-relevant: architectural boundaries, anti-patterns, contract rules, not setup or build instructions
- Historical PR reviews, the comments senior engineers have left on past PRs, especially patterns they flag repeatedly
- Slack decisions, including design decisions, "don't do X" threads, and incident post-mortems that never made it into documentation
- Incident history, the specific patterns that have caused outages before
A simplified profile looks like this:
name: Data Integrity Review
description: >
Review rules for changes where data shape may stay the same but meaning changes.
Focuses on semantic migrations, cross-layer readers, and silent compatibility breaks.
rules:
- id: FIELD_SEMANTIC_MIGRATION
severity: critical
description: >
When a field's value-space meaning changes, all readers of that field
must be audited. The field name and type may remain identical, making
the change invisible in diffs. Check struct fields, storage columns,
feature-flag contexts, analytics events, and URL parameters. During
transition periods where old and new meanings coexist, callers must
explicitly choose which value they need.
evidence: >
PR #48291 changed AccountId from a legacy integer string to a globally
unique resource ID, breaking downstream analytics readers that still
parsed it as an integer. Reverted in PR #48904. Pattern recurred in
PR #50177 and PR #50632 when same-name accessors began returning
different identifier semantics without updating all consumers.
Every candidate rule survives a deliberate filter before it ends up in a profile: if CI would already catch it, drop it. If the LLM knows it from general training, drop it. If we can't point to a concrete file-and-line in the codebase as evidence, drop it. What's left is the review knowledge that's genuinely DoorDash-specific, the stuff a senior engineer on that team would catch.
Then we route. When a PR touches the payment-service-provider gateway, the agent loads the PSP rules, the payment core rules, and the monetary-security rules, and nothing else. A PR touching the consumer feed gets a completely different set. The agent reviewing a fraud-detection change is, effectively, a different reviewer than the one looking at a pricing change, because it's consulting a different doctrine.
The routing is a big part of why acceptance rates hold up across 56 very different repos. The agent isn't applying one universal standard. It's applying the standard that matters for that specific change.
Why we built this ourselves
We built our own because we wanted the review agent to deeply understand DoorDash, not code in general.
Owning the system gives us several things worth calling out:
Deep knowledge of how we work. The review profiles described above are only possible because we own the pipeline end-to-end. We can encode repo-specific doctrine, incident history, and the kind of tacit knowledge senior engineers carry that never makes it into public documentation.
Full codebase access, not just the diff. The agent runs on remote VMs with a full clone of the repository, which means it can do what a human reviewer does: trace callers across the monorepo, find sibling implementations, read the tests that cover the code being changed, and pull context from anywhere in the codebase. It also lets us run modern coding-agent harnesses with full filesystem and tooling access. Most of the bugs worth catching don't live in the diff. They live in what the diff depends on.
Vendor flexibility. The underlying model landscape changes fast. Owning the system means we can swap models as better options arrive across OpenAI, Anthropic, open source, and others, then evaluate each against the same incident eval set we use to evaluate our own changes. The agent's architecture is deliberately model-agnostic.
Cost control. Today a review costs roughly $3 on average. That is already reasonable for the class of issues we're trying to catch, but the more important point is that cost is tunable. Because the workflow is staged, we can use cheaper models for simpler steps, reserve stronger models for verification-heavy steps, skip expensive passes on low-risk PRs, and use evals plus production acceptance to make sure cost reductions don't quietly reduce quality.
Closing the loop from review to fix
Useful review comments still create work. The same system that finds issues also helps close that loop. When the agent posts a finding, or when a human reviewer leaves any comment, anyone can reply in the GitHub PR thread by tagging the agent and asking for a change. "Can you handle the nil check here?" or "Resolve the merge conflicts."
The fixer runs in a remote VM with a full checkout of the repository and the original review context: the PR diff, the finding, the surrounding code, and the suggested direction. It makes the change there and pushes it back to the PR, so the author does not need to pull the branch locally, reconstruct the issue, or switch away from GitHub.
A few things this gives engineers:
- No branch switching. You don't need to pull the branch locally, set up the environment, make the edit, push, and come back. The fix happens on the PR.
- Context continuity. The reviewer's finding, including its analysis, the file and line it flagged, and the fix it suggested, is the prompt for the fixer. You don't need to write a detailed explanation; the context the reviewer already gathered carries forward.
- Reviewable output. The result is still a normal PR commit or diff, subject to the same CI and human review as any other change.
- Parallel fixes. Multiple comments on the same PR can be addressed concurrently. Each runs in its own isolated worktree, and the changes are merged back to the head branch in order.
This is not about removing engineer ownership. It's about removing the mechanical handoff between "the review found something" and "someone has to stop what they're doing to patch it."
What it's actually good at
The agent is not trying to replace human review. It's trying to catch the class of issues that are systematically hard for humans to catch during review, the ones that don't look suspicious at a glance but turn into incidents later.
A few patterns it's particularly good at:
Deletions. Humans skim deleted code. Additions look dangerous; deletions look like cleanup. But removing a struct field, a config flag, a default behavior, or an interface method can silently change runtime behavior while the code still compiles and tests still pass. The agent treats every deletion as a prompt to ask: who depended on this? What used to be true that is not anymore?
Cross-boundary drift. When a PR updates one side of a boundary, such as one brand's adapter, one of two producers, or one handler of an enum, the agent looks for the siblings that weren't updated. These bugs don't surface in CI because each side compiles on its own.
Silent behavior changes. API changes that don't break the signature. Error handling that quietly swallows more cases than it used to. Cache misses now treated as errors, or errors now treated as misses. The agent reads the surrounding code, not just the diff hunks, and asks what changed that the diff doesn't make obvious.
Engineering lessons from production
A few lessons only became obvious after running this on real PRs.
A turn counter is not a progress detector. One early failure mode was painfully expensive: the same model request could repeat over and over while the review made no progress. Max-turn limits did not catch it because the loop was not advancing the turn counter. Our first protection was a single overall timeout for the whole review, but that still allowed one stuck agent to burn 20 minutes of tokens before the run stopped. We moved to tighter per-agent soft and hard timeouts. The soft timeout interrupts the agent and asks it to stop investigating, drop anything speculative, and return only findings it has already verified. The hard timeout is the final kill switch. This turns an expensive stuck run into a bounded result that can still be useful to the author, instead of throwing away all the work the agent completed before it got stuck.
The cheapest model is not always the cheapest review. Several stages produce structured JSON. For simple schemas, a faster model works well. For more complex schemas, weaker models sometimes produced invalid output and retried multiple times, while a stronger model produced valid output on the first attempt. The unit that matters is not token price. It is cost per successful review.
Correct findings can still be bad comments. Broad summary notes, weak "consider checking" language, and duplicate comments across re-reviews all erode trust, even when the underlying concern is real. The comments that work are anchored to a changed file and line, explain the concrete behavior at risk, and tell the author where to start. If we cannot identify that action point, the system keeps the concern out of the inline review or drops it.
Reporting needs its own guardrails. The final GitHub comment is another place where quality can fail. We added checks that prevent the reporter from posting a false-clean review if the analysis found issues, reconcile stale findings when a PR changes during review, and collapse old comments during re-review so the author sees the current state, not an accumulating pile of outdated bot feedback.
Evals are the development loop
Acceptance rate is the production signal. It tells us whether engineers trust the comments enough to act on them. But acceptance is a lagging indicator: you need real PRs, real reviews, and settled outcomes before you know whether a change helped.
For day-to-day development, we use a smaller eval set built from real review misses and high-severity incidents. These are not synthetic coding puzzles. They are PRs where we know what a strong reviewer should have caught. The set is intentionally small today so we can iterate quickly without turning every prompt or retrieval change into an expensive batch run.
The eval set is how we test changes to prompts, retrieval strategies, model choices, and review profiles before they reach production. The production acceptance data is how we find out whether those changes helped in the wild.
What's next
The next step is scaling that development loop. We're building a continuous evaluation harness that measures every change against a growing corpus of real past incidents and review misses automatically. The goal is a system that provably gets better over time, not one we hope is getting better.

