
First of a blog series on the engineering behind DoorDash Assistant. Deep dives on Intelligence, Evaluation, Platform, and User Experience follow, alongside our earlier post on the memory platform.
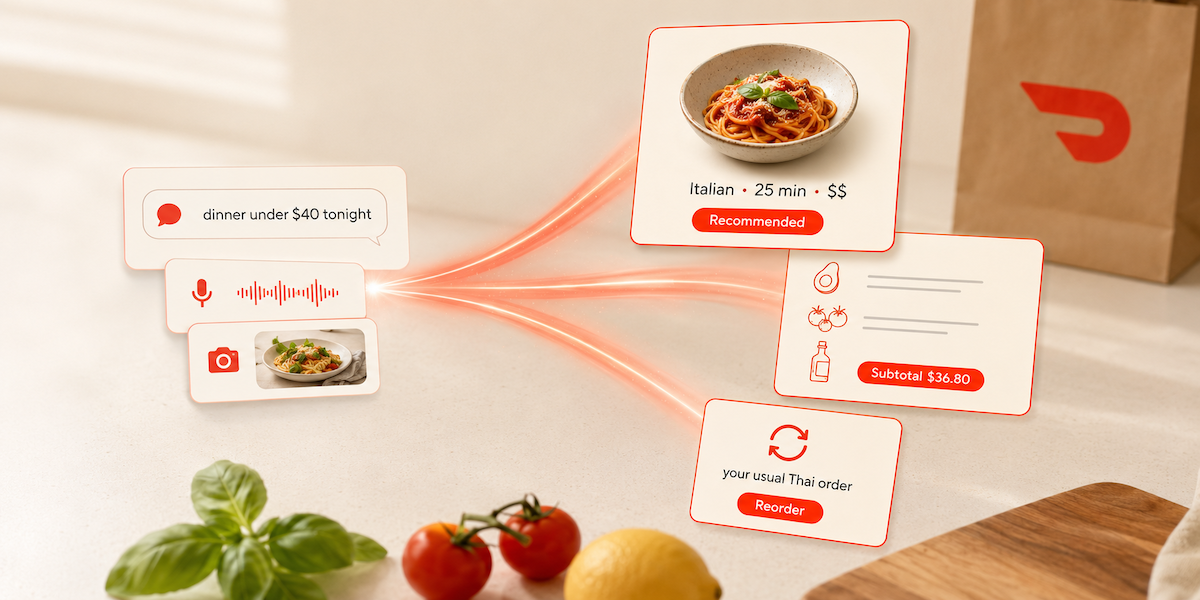
Ask DoorDash is a conversational way to shop on DoorDash. A consumer describes what they want, for example "a quick dinner under $30 near me" or "this week's groceries for two people, vegetarian, $60 budget," and the Assistant produces a response the consumer can refine through the conversation, whether that’s store recommendations or a built cart.
Producing that cart reliably comes down to local-commerce grounding and getting personalization right. Menus, prices, hours, ETAs, delivery radii, and inventory change minute to minute and depend on where the consumer is. None of it lives in a model's weights, and almost none of it is scrapable: which restaurants are serving vegetarian today, whether the nearest grocery store has avocados, what a realistic ETA from the consumer's address is right now. Personalization matters just as much: a consumer who told the Assistant they shop vegetarian for a household of two shouldn't have to repeat that on the next request. DoorDash has spent a decade building the catalog and the consumer memory the agent grounds against, and most of what follows is how we keep the agent's output tied to them.
The Assistant that powers Ask DoorDash is now rolling out to select areas in the U.S. on iOS, starting with restaurant search and grocery shopping. This post covers the runtime architecture, the four engineering pillars beneath it, and how the team builds it.
What's in production
Patterns from the first weeks of early consumer exposure:
- Discovery is most of the traffic. Around seven in ten messages are some form of discovery: looking for a restaurant ("ramen near me"), figuring out dinner ("what should I eat tonight"), planning a grocery run ("vegetarian dinner for two"), or browsing for ideas. The rest are support, deals, or general questions.
- Sessions tend to be multi-turn. Most consumers who send a first message keep iterating in the same session: refining a recommendation, narrowing a search, swapping an item, or building out a list.
- The largest potential production-failure category is grounding. Stores recommended as open when they're closed, prices that don't match the catalog, items the agent claims to have added that aren't in the cart. The fix in each case has been to route the agent's claim through a tool call against the system of record.
A short example
A typical grocery session looks roughly like this. Numbers are illustrative.
Turn 1. Consumer: "Build me a $60 vegetarian list for two people this week."
The agent retrieves the consumer's memory blocks (dietary preferences, brand affinities, past order history), runs a delivery-radius search for currently open grocery stores with reasonable ETAs, picks one, and assembles a shopping list. The Assistant renders the list as an interactive widget with a running subtotal under $60.
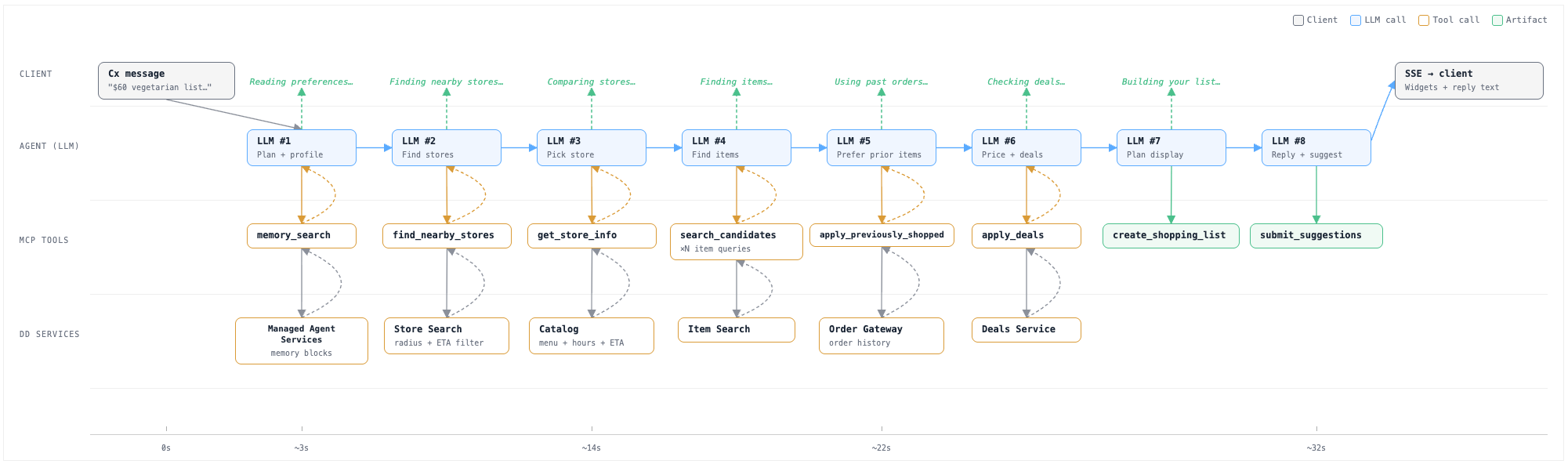
Behind that single turn:
- 6-8 LLM calls and a handful of tool calls against the live catalog (consumer memory lookup, store search, per-merchant inspection, item search, order history lookup, optional pricing or deals check, display planning, reply text + suggestions)
- Low hundreds of thousands of input tokens in the model context once the candidate set is in
- 20-30 seconds end to end
Turn 2. Consumer taps the widget to swap the pasta brand, remove a yogurt the household already has, and edit a quantity. These edits run against the artifact directly through the Gateway and never enter an LLM round trip. The subtotal recomputes against the live catalog.
Turn 3. Consumer: "Add salad ingredients." The agent reads the artifact (with the consumer's edits applied), grounds against the same store's current inventory, appends matching items within the remaining budget, and renders the updated list.
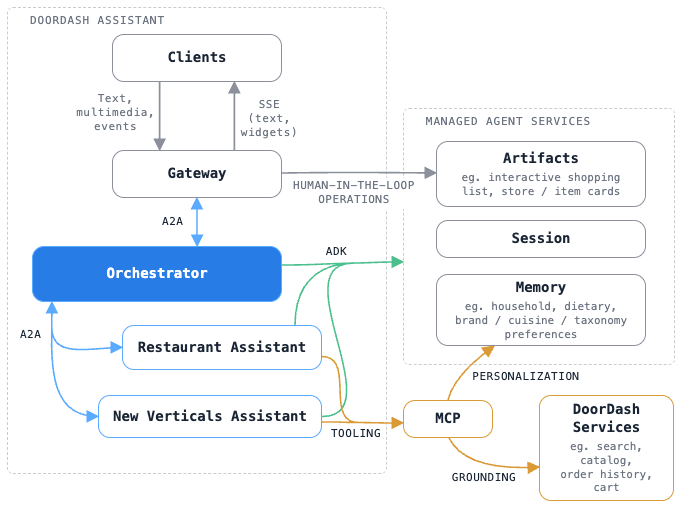
Architecture overview
DoorDash Assistant is a layer on top of the existing DoorDash platform. Four parts, shown in Figure 2:
- Assistant runtime. Clients, a Gateway, an Orchestrator agent, and two domain agents (restaurant discovery and grocery shopping).
- Managed Agent Services. Artifacts (widgets stored as versioned objects), session state, and consumer-level memory. Built once for all DoorDash agent teams.
- A shared Model Context Protocol (MCP) tool surface. Business logic and grounding data exposed as typed tools that any agent, and our external integrations, can call.
- DoorDash backend services. The same search, catalog, order history, cart, deals, and merchant pipelines the rest of the app uses.
The four engineering pillars
The engineering work splits into four pillars. Each gets a dedicated post in this series; below is the short version.
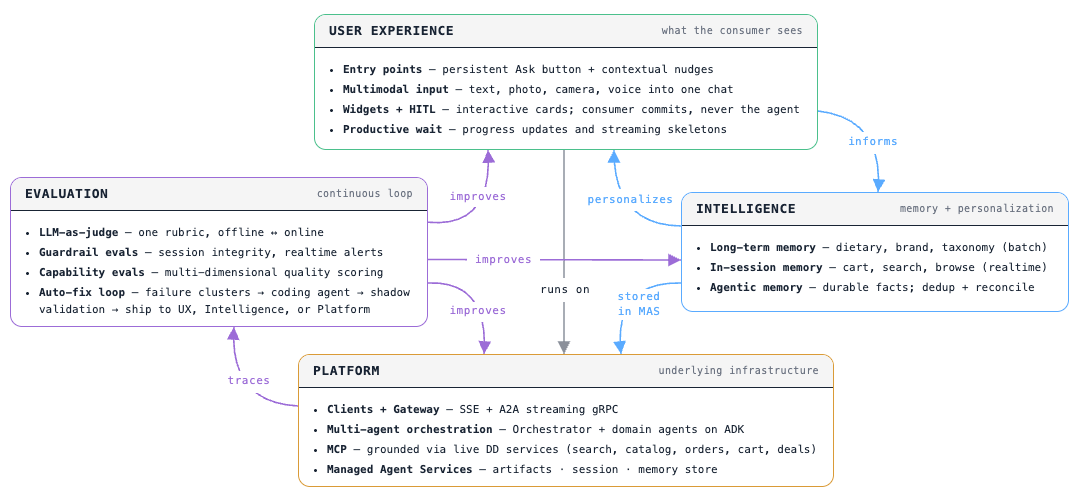
1. Intelligence
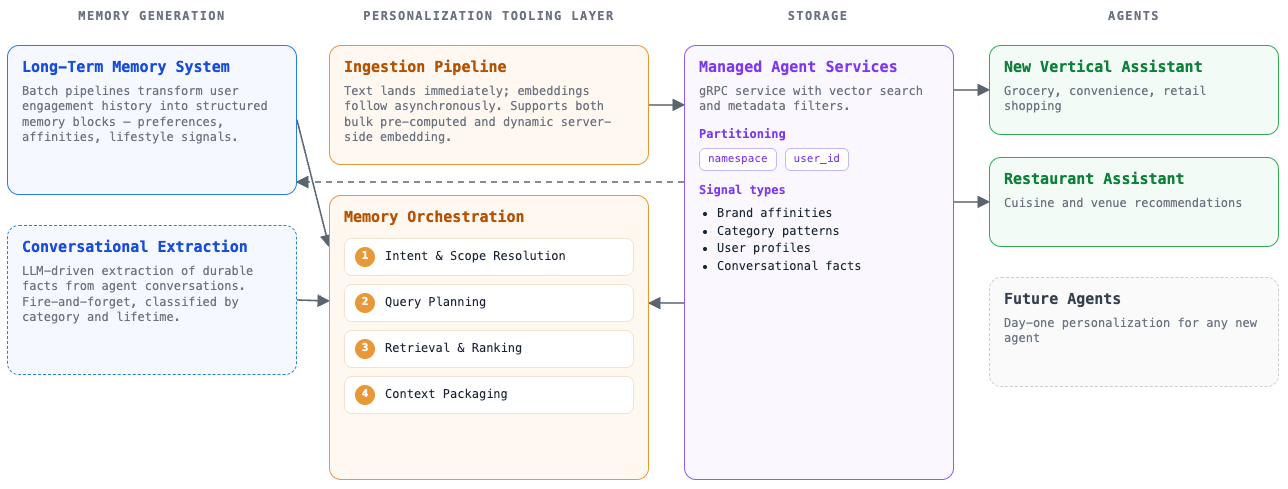
Agents reason in natural language and start every session with no history. The Intelligence pillar adds the memory layer that lets each session pick up the consumer's context. Our memory platform post covers the underlying store: how facts are extracted, partitioned, and retrieved. This section is about how the agent uses that store during a conversation.
| Layer | Update cadence | What it holds |
|---|---|---|
| Long-term memory | Daily/weekly batch | Dietary preferences, dining patterns, brand affinity, item taxonomy, store preferences, cross-channel patterns |
| In-session memory | Realtime | Current intent from active cart, search, and browse activity |
| Agentic memory | Conversation-driven | Durable facts the consumer states explicitly. New facts are deduplicated against long-term memory and reconciled with profile data before being written back. Examples we save: "vegetarian preferences," "always shopping for two," "prefer a further Safeway that has better inventory availability for my usuals." Examples we skip: one-time mentions ("getting this for a friend tonight"), ambiguous statements, anything the consumer has already overridden in later turns. |
Each memory block is a small, structured fact: a category plus the preference itself, such as dietary: prefers dairy-free or brand: prefers Oatly. Each fact is written with a timestamp and, where appropriate, a time-to-live so transient details, like a one-off pantry run, expire automatically.
Facts are extracted from the conversation by an LLM and stored in Managed Agent Services. The store is partitioned into namespaces by memory kind: durable facts, taste profile, and brand or category preferences. Writes are reconcilable rather than append-only. The extractor can add, revise, or retract a fact as the consumer’s preferences change, so the store reflects the consumer’s current state instead of becoming an ever-growing log. Health and medical information is never written, even on explicit request.
Memory only matters if it composes with what is actually for sale right now. A consumer who “always buys Oatly” should get a different recommendation when Oatly is out of stock at the nearest store. A “$60 weekly budget” stops mattering when the cheapest qualifying cart subtotal for this week’s request comes in at $72.
We do not resolve this in a separate layer. It happens on the turn. The agent retrieves relevant stored preferences through its memory tools, then reconciles them against live grounding data returned by search and cart tools, including availability, pricing, and store hours. When memory conflicts with live data, the agent adjusts its plan accordingly.
2. Evaluation
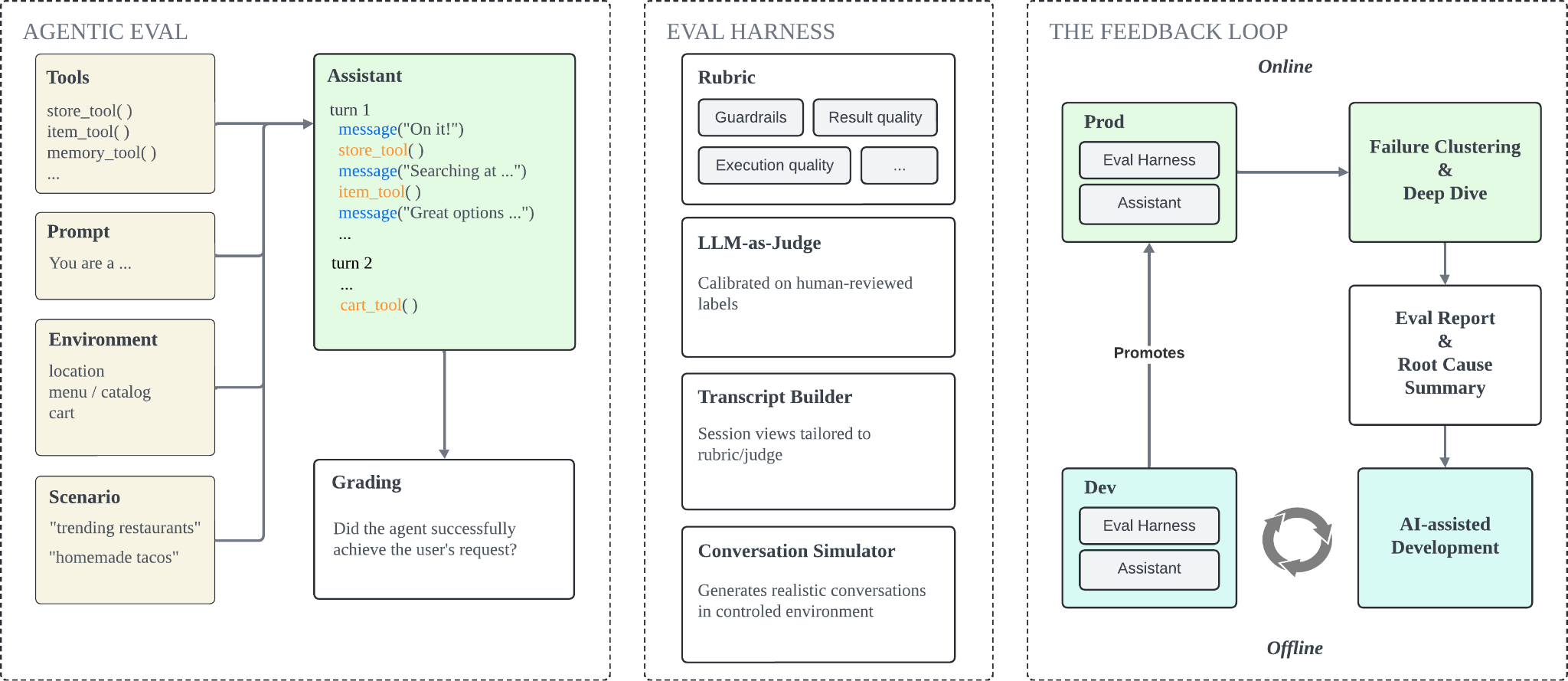
Evaluating an agentic system is fundamentally different from testing traditional software or evaluating an AI model. Unit and integration tests verify that individual components behave as expected. Dashboards monitor the health of production services. Model evaluations measure capabilities using predefined tasks and datasets. While all of these remain important, none directly answer the question that matters: did the agent successfully help the user accomplish their task?
The challenge arises from the stateful nature of agent interactions. Sessions span multiple turns and tool invocations, with each action shaping the context for subsequent decisions. A change that appears minor in isolation can alter how an entire conversation unfolds, making it difficult to reason about agent quality through pre-defined input-output mappings alone.
Figure 5 shows the evaluation system we built to measure and improve agent quality end to end. At a high level, the system constructs a transcript for each session, capturing user inputs, agent responses, tool calls, tool outputs, and grounding context. A suite of LLM-as-judge, calibrated against human-reviewed labels, evaluates the transcript against the relevant rubric. Guardrail evals monitor critical agent behaviors such as session integrity and safety, surfacing failures that could break user trust. Capability evals measure quality dimensions such as result quality and execution quality, helping us quantify agent performance across the parts of the experience we care about. Offline and online evals share the same rubric and judge, so calibration stays aligned between development and production. The forthcoming agentic evaluation post goes deeper on individual components of this system.
As online evals run, background agents cluster failures, perform deep-dive investigation, and generate reports for the team. Some reports identify bugs in the assistant itself, such as broken item-selection logic. Others uncover gaps in the evaluation system, such as an LLM-as-judge prompt producing false positives. The team reviews each report, makes the necessary changes, generates synthetic sessions through the simulator, and validates the results offline against the same rubric before deploying to production.
3. Platform
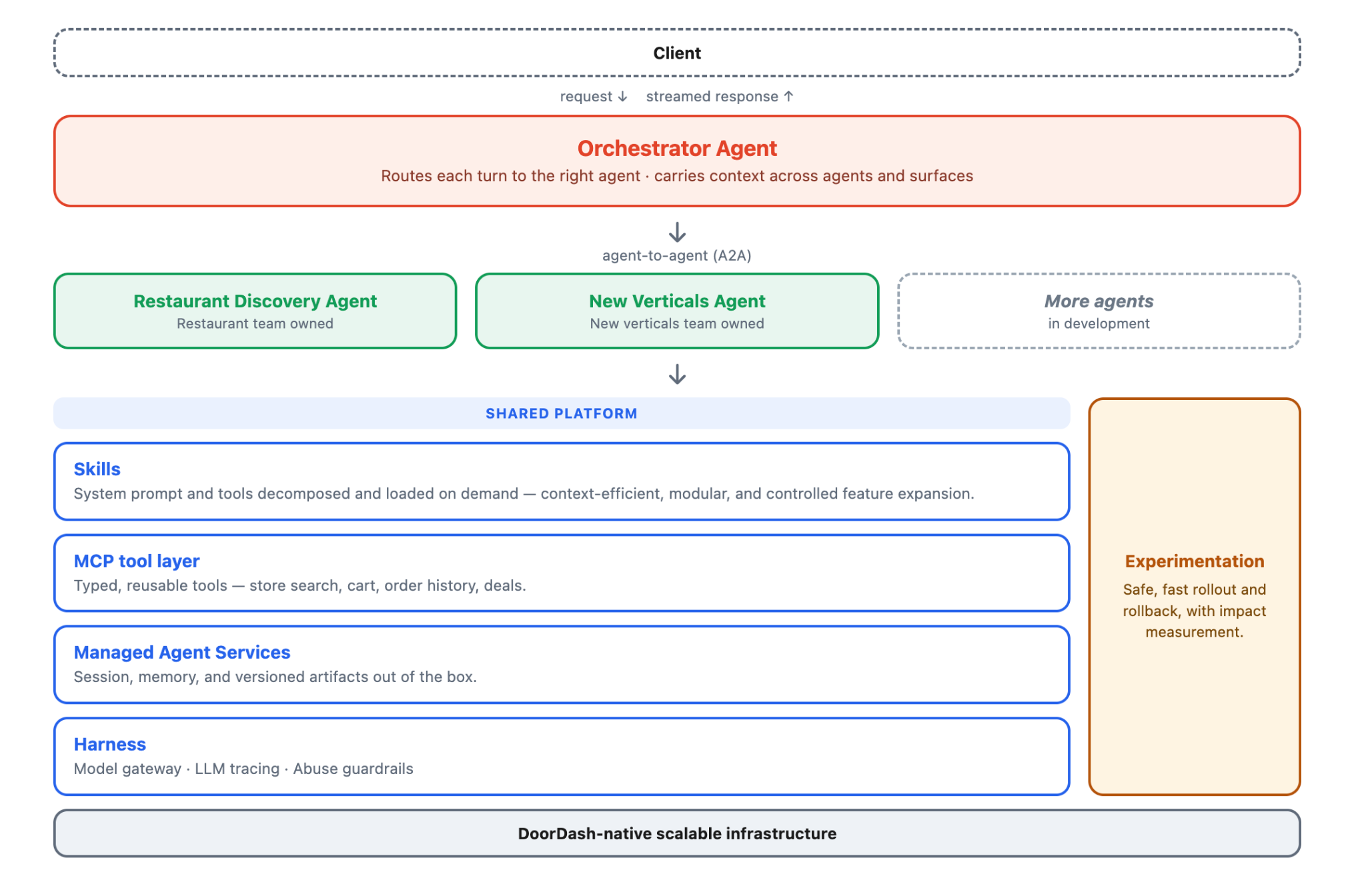
The DoorDash Assistant is made up of several domain agents on a shared platform: restaurant discovery and grocery shopping today, with more in development, each owned by a separate team and shipping on its own schedule. We built the platform to solve common agentic-system problems (high end-to-end latency, context management, tooling) in a way that is reusable across agents and use cases. The rest of this section walks each part.
Clients and the Gateway
The client today is iOS, with Android and web coming. Inputs are text, image, and voice; output is a Server-Sent Events (SSE) stream of text deltas and widget payloads. The Gateway, in our consumer web monorepo, uses the Vercel AI SDK to expose its UI message stream format to clients and translates that into agent-to-agent (A2A) streaming gRPC. It also handles authentication, session continuity, and the SSE plumbing for long-lived multi-turn requests.
Orchestrator and domain agents
An Orchestrator agent decides which domain agent (restaurant discovery or grocery shopping) handles each turn. They communicate over the same A2A protocol the Gateway uses, so each agent deploys on its own schedule. Agent pinning keeps follow-up turns like "add to cart" routed to whichever agent answered the previous turn, until the consumer's intent shifts.
Each agent runs on Google's Agent Development Kit (ADK). A unified model factory selects the model per role (routing, restaurant discovery, grocery shopping, summarization) by configuration, with fallback across providers and per-role swaps without a code release. We routinely shadow-evaluate alternative models, and the eval harness produces the data that informs each swap.
Managed Agent Services
All three agents access the same set of Managed Agent Services through ADK, built once so other agent teams at DoorDash can adopt them without rebuilding the basics:
- Artifacts. Widgets like shopping lists and store cards stored as versioned objects with stable IDs. The consumer edits them between turns directly through the Gateway, and the agent reads the latest version on the next turn. The cart edits in the earlier example all run as direct artifact mutations while the LLM is idle.
- Session. Conversation turns, tool calls, tool results, and agent state, namespaced per agent with cross-agent sharing through A2A headers.
- Memory. Consumer-level personalization signals. The Intelligence pillar above describes how facts are extracted, stored, and reconciled with live grounding data.
MCP and grounding
Agents call tools through a shared MCP layer. The same MCP server backs both the Assistant and our external integrations, with each surface configured to see the tools it needs. Business logic (cart manipulation, store lookup, deal application) lives in the tools, separate from the prompts that call them. Personalization runs through the same layer (the agent calls memory_search the same way it calls find_nearby_stores).
Underneath MCP are the same backend services the rest of the DoorDash app uses (search, catalog, order history, cart, deals, the merchant pipeline). Improvements there apply to the Assistant for free, and so do edge cases: freshly delisted items, mid-update menus, isochrone polygons that exclude a store the consumer can see geographically. The goal is for every consumer-visible claim to come from a tool call against the system of record on the turn it's made.
4. User Experience
The Assistant is designed to feel like a personal shopper: the consumer can lean on it or take over at any point.
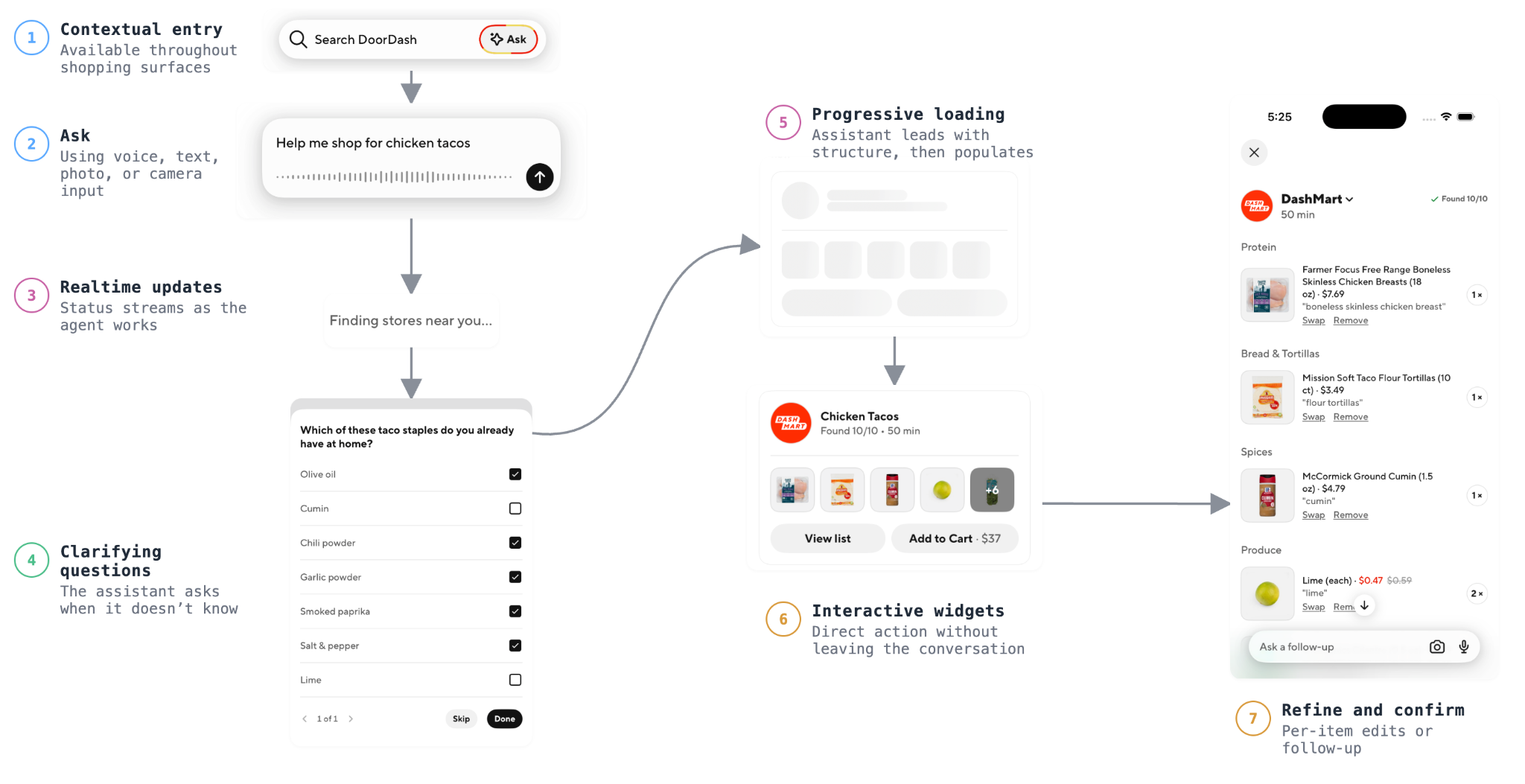
Meeting the consumer where they are. The Assistant has a standard entry point in the form of a persistent "Ask" button. Around that, contextual entry points show up in the surfaces where the consumer is already shopping through nudges and suggestions. Input matches the moment too. Text, photo, camera, and voice all feed the same conversation, and each opens a different way for the consumer to decide how they shop: a typed shopping list for the week, a screenshot of a recipe saved from Instagram, a snap of the fridge to see what's missing, or a voice request for dinner ideas on the walk home.
Creating a collaborative environment. The consumer stays in the loop, choosing when to delegate to the Assistant and when to operate manually. They can hand off a full task ("build me a $60 vegetarian list for two") or stay hands-on. Either way, the Assistant produces the work but never commits it without explicit consumer confirmation. When the Assistant builds a shopping list, the consumer reviews and confirms before it lands in the cart. The consumer can tweak items, quantities, and stores directly on the widget (often faster), or ask the Assistant to make the change in the next turn. The collaboration runs the other direction too. For a recipe, the Assistant pauses to ask which pantry staples the consumer already has (flour, oil, salt) before building out the rest of the list. Ambiguous requests get a clarifying question, and any assumption the Assistant had to make is surfaced explicitly so the consumer can correct it.
Turning replies into interactions. Responses lean on widgets like store cards, lists, and cart sheets, rendered from the same live data the rest of the app uses (actual prices, real cart contents, current store hours). Grounded in real data, the conversation earns trust: the consumer can verify what the Assistant is offering rather than taking the Assistant's word for it. As the widget library grows, we're closing more of the gaps where the consumer would otherwise have to type out what they want, so free-text exchanges become direct widget interactions.
Making the wait productive. LLM responses take seconds, which is an eternity in a shopping flow. When the Assistant opens, pre-generated suggestion prompts are served from cache so something is on screen instantly. Once a turn is in flight, an SSE stream pushes partial results as the agent works, so widget skeletons settle into shape and text fills in smoothly.
Building a scalable core. The client is structured to evolve. An adaptable set of frameworks decouples the chat from any specific spec or interaction paradigm, so new agent behaviors, widget contracts, and interaction patterns can land in the app without significant rework.
How we work
Three notes on the team's operating model.
AI-assisted development
The core Assistant team works with an AI coding assistant in the loop full-time. The team maintains a small library of reusable skills: sprint planning / standup preview, CI failure triage, production debugging runbooks, queries against our memory store, repo synchronization, and E2E test orchestration. In the months leading up to launch, weekly pull-request volume doubled in the early sprints and roughly tripled by the final pre-launch weeks.
The evaluation harness described in the Eval pillar is also part of the development workflow. It runs against production traces and against proposed prompt or code changes. When the harness finds a failure cluster, a coding agent reads it, proposes a fix, and validates the fix against a shadow Assistant paired with the simulator. Changes are gated on the rubric pass rate staying clean.
Iteration speed
Architecture and model choices are reversible by design. Every meaningful change runs through the simulation harness before shipping, and a dynamic value lets us flip behavior per consumer or roll back instantly. Through the project we have reversed roughly as many decisions as we have kept: static memory embeddings became dynamic, per-sub-agent prompt optimization became system-level joint optimization, and several model choices have moved in and out of the primary path.
Loosely coupled domain teams
Grocery and restaurant discovery are different products in practice. A grocery cart has many acceptable answers (substitutions, alternates, equivalent brands), and consumers usually edit the cart before they check out. Restaurant discovery is more binary: the consumer either liked the recommendation enough to order or they didn't. The two domains have separate teams, agents, tool surfaces, and deploy schedules. They share the platform: widgets, Managed Agent Services, MCP, the Orchestrator, cold-start handling, and the evaluation harness. A regression in one domain doesn't affect the other.
What's coming in this series
Over the coming weeks we will publish a deep dive on each pillar:
- Intelligence. The memory and personalization layer behind the Assistant. Builds on our memory platform post.
- Evaluation. How we measure and steer quality in development and in production.
- Platform. The runtime and infrastructure backing the agents.
- User Experience. Entry points, widgets, multimodal input, and human-in-the-loop design.
Use-case deep dives may follow. A companion post from the DoorDash Reservations team will cover AI in the reservations experience separately.
Working Team
The Assistant is the work of a much larger team. Other contributors include:
Aayush Sheth, Alex Levy, Angela Yuan, Benjamin Wu, Bin Li, Christian Lai, Danny Nightingale, Francisco Escobar, Haowen Qu, Heather Song, James Zhao, Kevin Schaefer, Kyle MacDonald, Mauricio Barrera Acuna, Nithin Alexander, Raghav Saboo, Ravikiran Jagarlamudi, Sangmin Shin, Twisha Jain, Vipul Venkataraman, Xiaochang Miao, Yating Han.
Join Us
If working on agents, evaluation systems, agent infrastructure, or consumer-facing AI at scale sounds interesting, we're hiring. See our open engineering roles at careersatdoordash.com.






