
Here comes the mandatory “AI Moves Fast” disclaimer: when I first drafted this article in early March, I began by saying something about how “AI is coming.” and how we should get ready for it. Re-reading that just a couple of months later, the phrase feels remarkably outdated: AI is not just coming anymore; it has arrived. Major tech companies are now generating more than 75% of their code through AI, and smaller, less cutting-edge companies are quickly following suit. By the time you read this article, this premise might already sound just as silly as my previous one!
However, I believe the takeaways from this article remain relevant. What I cover here is my personal journey to AI proficiency. All things considered, I believe myself to be an intermediate user at best, but getting here required plenty of experimentation and far more podcast-listening than I am willing to admit. The part that still feels unsolved for many developers is not using AI for autocomplete or quick edits, but trusting an agent with a larger task and getting back something coherent, reviewable, and useful. If that workflow has not quite clicked for you yet, this article is for you.
Over the next few sections, I’ll retrace my path from Cursor being my default AI coding companion, to my confused first attempts at using Claude Code, to the agent-team experiments that mostly produced expensive AI slop, to the research → plan → implement loop that finally made long-running agent work practical.
Then I’ll present a little project I call Agentic Orchestrator, which encapsulates all these lessons. Shown in Figure 1, it’s a boring state-machine-driven orchestrator I created to make agents one-shot ambitious projects. And the best part? It’s open source!
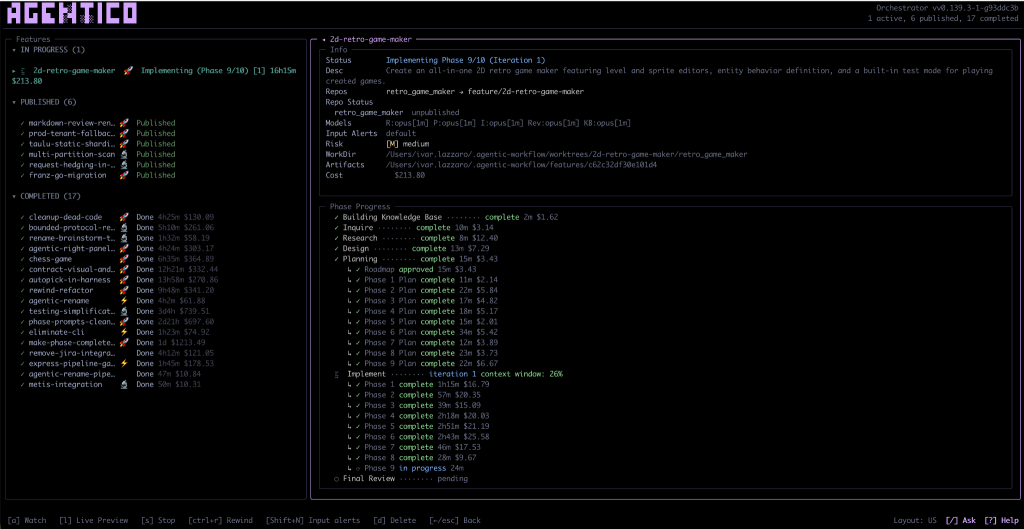
Figure 1: The main dashboard of Agentic Orchestrator, keeping tabs of multiple features in different development stages.
But let’s start from the beginning.
Before the loop: My cursor phase
Cursor is an incredible tool for boosting productivity that combines the convenience of a full integrated development environment with the power of agentic AI to tackle tasks at various levels of complexity. It’s getting better over time as the models and the tools become more capable. This became my bread and butter in 2025 and into 2026. I don’t remember having written many lines of code manually, unless relentless tabbing counts.
But as I became more curious about how far I could push agentic development, I started encountering the limitations of Cursor and tab-driven development in general. The primary problem was that I couldn’t get it to run reliably long enough to build complex features with full autonomy.
With the breakthrough features brought by Anthropic’s Opus, the industry was already talking about long-running agents and their ability to one-shot features without human input. I wanted to experience all of that for myself! It was therefore time for me to move to the new hot thing everyone was talking about: Claude Code.
My complex relationship with Claude Code
Picture this: Your friends and colleagues are bragging about how they can automate all aspects of their lives, while your attempts at prompting even the simplest things fail miserably. That was me back in March 2026.
Various folks from different companies and technical backgrounds were trying to sell me on the idea that we had now reached the singularity. No more humans were needed in the loop, they said; AI will incarnate your every desire and make them reality, including impersonating you on Slack, taking Zoom calls, making a killer espresso, and of course, writing code. All I needed to do, they said, was switch to Claude Code with Opus 4.6 to see my world shaken. And so I did! For me, though, it turned out to be worse than using equivalent models with Cursor.
I like a nice, terminal-based tool as much as the next coder, but with Claude Code, I lost my ability to interact directly to review every individual change. This would, in theory, come in exchange for better orchestration and tools provided by the harness, but in the end, the model was still the same. And it’s not like Cursor didn’t have tools or a plan mode. So, what gives?
It turns out that Claude Code comes with a mind-shift: You don’t have to interact with your code anymore. You have to change your development flow, trust the agent, and fully iterate via prompting.
It was time to start experimenting and aim for that dreamy Opus-powered espresso.
Starting the experiments: Agents, agents, agents!

Remember my primary objective: To get AI to build a complex feature autonomously.
While exploring the Claude Code documentation, I found an experimental feature called agent teams. This allows users to invoke a team of agents with different personalities and roles to hack different parts of the codebase and then merge their results into a working final product — or, at least, that’s the theory.
In practice, my experience with this swarm of agents went wrong for reasons I didn't expect. I initially assumed the hard part would be the prompting, so I leaned into that. I wrote elaborate personas, told one agent it was "the best Go developer who ever lived," cast another as a "meticulous senior reviewer," and choreographed how they'd hand work off to one another. I was, essentially, a motivational influencer for language models. But none of it moved the needle. Flattery doesn't add capability! The model isn't holding its real skills in reserve until you tell it it's brilliant. The persona was theater; underneath that theater, the output was exactly as good or as bad as it was ever going to be.
My personas fiasco was mostly harmless. At worst, it was wasted context. The real problem was that parallelism multiplies divergence. Each agent worked from its own reading of an ambiguous spec, made its own independent assumptions, and invented its own version of the interface where two pieces were supposed to meet. Every agent was locally plausible. Nothing was globally consistent. So when it came time to merge, the seams didn't line up; there were mismatched contracts, duplicated logic, and two halves of a feature that each assumed the other half worked differently.
The net result? For trivial features, agent teams worked adequately. For anything that might actually justify the complexity of a multi-agent setup, the AI slop coming out of those sessions was completely unusable. I found myself dropping entire pull requests that had taken hours of processing for this very reason.
So I took a step back. The lesson wasn't that agents can't handle complexity, or that more agents are worse than one. It was that I'd been asking the wrong question. I kept trying to get agents to collaborate, to coordinate, to agree, to merge their work, when the real issue was that there was nothing for them to coordinate around. There was no shared source of truth. No artifacts were being handed from one step to the next. There was no separation between thinking and doing. The agents weren't the problem. The empty space between them was. So I stopped asking how to get a team of agents to work together and started asking the opposite: What scaffolding would free each agent from having to collaborate so that it could do just one narrow, well-defined job against a fixed artifact that had already been produced? It became less throw-agents-at-the-problem, and more about building the rails and letting the agents run on them one stretch at a time.
This new approach is what eventually led me down a very different path.
My breakthrough: Research, interview, plan, loop, and antagonistic reviewers
After the team of agents debacle, I did something radical: I talked to people — like, actual humans. I sought out engineers who had somehow cracked the code on getting Claude to do meaningful work autonomously. What I learned completely changed my mental model.
The first revelation came from an inspiring talk from Humanlayer on what they call the RPI — research, plan, implement — framework. The idea is deceptively simple: Instead of shoving an entire spec at an agent and hoping for the best, you break the work into distinct cognitive phases. First, the agent researches the codebase by reading the relevant files, understanding the patterns, and mapping out the dependencies. It then produces a plan — a detailed, phased implementation document with specific file paths, code snippets, and success criteria. Only after that’s completed does it implement, working from its own plan rather than from a vague understanding of a spec it half-forgot 30,000 tokens ago.
This was a fundamentally different philosophy from the here’s-the-spec-go-build-it approach I had been using. Each phase has a narrow, well-defined objective. Each phase produces a concrete artifact that becomes the input for the next one. And crucially, each phase fits comfortably within a context window because it's not trying to hold the entire problem in its head at once. Research doesn't need to think about implementation details. Planning doesn't need to write code. Implementation doesn't need to rediscover the codebase, because the plan already tells it exactly where to look.
The second revelation was even simpler, courtesy of the grill-me skill from Matt Pocock: Let the agent interview you. Instead of spending hours writing the perfect prompt that anticipates every edge case and clarifies every ambiguity, you let the agent ask you questions! It turns out that a back-and-forth session with an agent that has just finished researching your codebase is worth more than hours of upfront prompt engineering. The agent knows what it needs; you just have to give it permission to ask. You’d be surprised by how relevant these questions sometimes are. At the end of the day, it makes complete sense; one of the things you learn as you level up your career is to delegate. When you do so, more often than not the engineers to whom you’ve delegated work will come back with questions. They don’t want to make incorrect assumptions about what you had in mind. Why would agents be different?
But the third and most important lesson I learned was about what the industry commonly refers to as the loop.
You see, even if you implement RPI, you still have two problems. The first is the context window problem: A complex implementation might take more tokens than a single session can hold. The agent might get 80% of the way through the plan and then start losing coherence. Or it might hit an unexpected compilation error that sends it spiraling. The second problem is more subtle: Self-review is almost worthless. An agent that just spent half an hour implementing a feature shouldn’t have to then decide whether that implementation is actually good.
The loop solves the first problem. An antagonistic reviewer solves the second. And the beautiful part? The whole thing is embarrassingly simple. At its core, it is still basically a Bash while loop, just with a review gate, as shown here:
| while [ iteration < max_iterations ]; do run the implementation agent with the objective and current progress check if the agent reported SUCCESS or RETRY if RETRY → feed the progress back in and go again if SUCCESS → run an antagonistic reviewer in a fresh context window if APPROVED → done if CHANGES_REQUESTED → feed the review back in and go again done |
That’s it. That’s the secret. You run the agent, it does some work, it updates a progress file saying “here’s what I’ve done, here’s what’s left,” and then it emits a signal: AGENT_LOOP_STATUS: SUCCESS or AGENT_LOOP_STATUS: RETRY. If it says RETRY, you start a fresh session with a clean context window, but you hand it the progress file so it knows where it left off. If it says SUCCESS, you do not trust it. You summon the antagonist.
By antagonistic reviewer, I do not mean an agent that is rude or contrarian for sport (although that’s really fun to watch; you should try it!). I mean a separate agent whose job is to be professionally skeptical. It reads the plan, inspects the diff, checks the tests, looks for missed requirements, calls out brittle assumptions, and asks the question the implementing agent is least incentivized to ask: “Is this actually done?”
The separate context window is the key. If the same agent reviews its own work, it carries all the same assumptions, shortcuts, and narrative momentum from the implementation. It remembers why it made a decision, so it is more likely to defend that decision. A fresh reviewer has no such attachment. It sees the repository state, the stated objective, and the implementation artifacts. That separation creates just enough adversarial pressure to catch the kinds of mistakes that otherwise survive until a human review.
This solves both failure modes in the most pragmatic way possible. Instead of trying to make a single session survive the entire implementation, you accept that sessions are ephemeral and design around that. Each iteration gets a clean context window. Each iteration reads the progress file, understands what has been done, and focuses on what comes next. The progress file becomes the agent’s long-term memory, while the reviewer becomes the immune system that prevents bad work from quietly declaring itself finished.
The most agent-savvy among you might already recognize that this is a Ralph loop. The antagonistic reviewer added the missing piece; it’s not “keep going until done,” but “keep going until a fresh pair of eyes agrees that done means done.”
The combination of RPI phases, the loop, and antagonistic review was a genuine step change. For the first time, I could point Claude at a moderately complex feature — something that would take a few thousand lines of code across multiple files — and come back to a working implementation. It didn't work every time, but it did often enough that I stopped thinking of autonomous coding as a party trick and started thinking of it as a tool.
The core insight was solid: Break the work into phases, let each phase produce artifacts, loop across context boundaries, and never let the agent that wrote the code be the only judge of whether the code is good.
Messy workspace
While I was ecstatic with my ability to produce complex features with very little tuning at the end after this breakthrough, I got carried away. My workspace started looking something like Figure 2, but multiplied by five or six — one per concurrent feature I was working on.
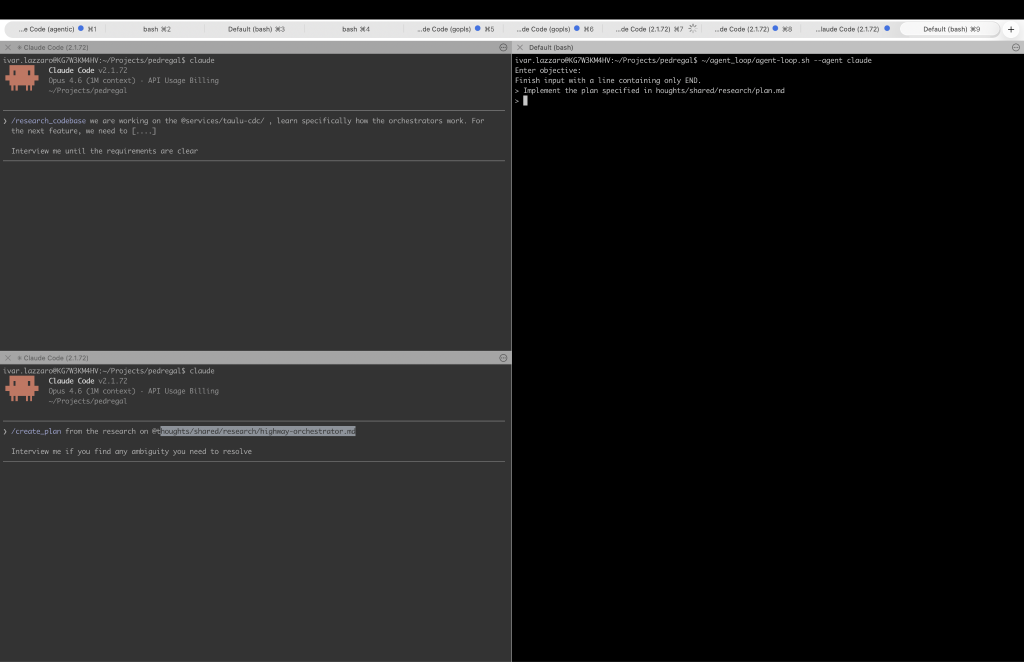
Figure 2: My legacy workspace: multiple Claude sessions and terminal panes, each tracking a different phase of the RPI loop.
The workflow worked, but it was awkward to run by hand. For each feature, I had one AI session researching the codebase, another turning that research into an implementation plan, and then a loop where I answered clarification questions, reviewed the plan, and kicked off the implementation. That was manageable for one feature. Once I tried running it across five or six features at the same time, I was constantly context-switching between terminals, plans, branches, and half-finished conversations.
My first instinct was to turn back to agents. I instructed a manager agent to implement the RPI-plus-loop framework using sub-agents so that I could manage everything from a single Claude instance. But, already traumatized by my earlier agent teams experience, I decided to build a tool instead. I am pleased to announce that this tool is now open source for everyone to enjoy.
Meet Agentic Orchestrator
And that's how Agentic Orchestrator was born. It’s a terminal user interface (TUI) that takes the research → plan → implement framework, enhances it, and wraps it in real engineering.
The core idea is simple: Don't ask an AI to manage other AIs. Instead, build a harness that drives the feature lifecycle, and let each AI session focus on doing exactly one thing well. The orchestrator handles the plumbing, including state transitions, worktree isolation, session management, progress tracking, and crash recovery. The agent handles the thinking. It’s a predictable orchestration on top of unpredictable agents.
From Bash loops to a real state machine
Remember the Bash while loop from earlier? That’s the one where you run the agent, check the status, and feed progress back in. Agentic Orchestrator takes that same idea and gives it actual bones. Every feature progresses through a well-defined state machine, as shown in Figure 3: Knowledge base → inquiring → researching → designing → planning → implementing → reviewing → publishing → done.
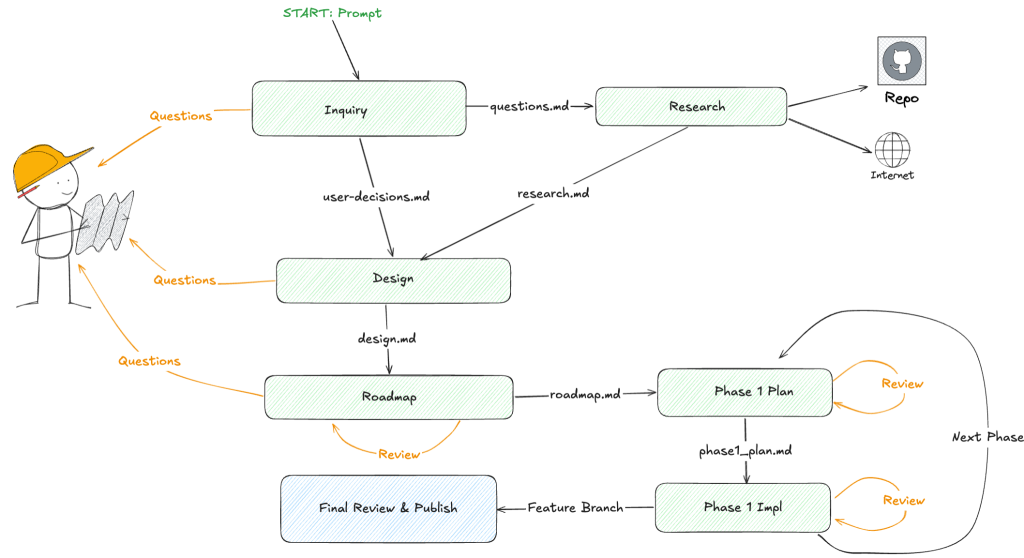
Figure 3: The new and improved development loop.
RPI now looks a bit different from before. This is the result of many weeks of experimentation, which led to a workflow that allows me to produce very complex features confidently in a single long-running session. No, I don’t have a clever acronym for it, but Table 1 shows what each step is and what it does.
| Phase | Output | Why it exists |
| Knowledge base | A reusable map of architecture, conventions, APIs, dependencies, and verification commands | Allows every later phase to start from a real baseline instead of rediscovering the repo from scratch. |
| Inquiry | Clarifying questions and user answers via the grill-me pattern | Forces unknowns into the open before any agent starts guessing. |
| Research | Documents research with concrete file references and current-state behavior | Describes the reality, not the solution, upon which the factual substrate planning will rest. |
| Design | Design doc: Problem statement, solution, user stories, decisions, explicit out-of-scope | Provides the feature's source of truth, produced through a focused design review with the agent. |
| Roadmap | Ordered list of thin, end-to-end vertical slices | Allows agents to execute bounded, verifiable slices instead of sprawling plans that touch every layer at once. |
| Phase planning | Approved phase plan with tasks, acceptance criteria, and verification expectations | Makes the work concrete enough to execute; optional plan-stage critics catch weak plans before code becomes expensive. |
| Implementation | Code, tests, progress file, verification report | Allows a fresh context window to pick up where the previous session stopped; this progress file enforces the loop with discipline. |
| Final review | Approval or itemized change requests | Provides a reviewer with no implementation momentum to decide whether done actually means done. |
Table 1: Each step of the new development loop, explained.
The boring infrastructure
The phases are the visible part. Underneath, the orchestrator handles the unglamorous work that turns an otherwise manual workflow into a system that survives me closing the laptop. Under the hood, several components keep things going:
- Worktrees: Every feature runs in its own git worktree, which means that several features can move through the pipeline against the same repo without stepping on each other.
- The TUI: This interface provides a dashboard that tracks everything in flight — what's researching, what's blocked, what needs review, and what's ready to publish.
- Crash recovery and session management: Because the state machine is persisted, you won’t lose progress to such things as a closed terminal, a hung session, or a hard crash.
- Post-publish actions: Even after the PR is up, the orchestrator still has your back. You can rebase against main, request targeted refactors, rewind to a prior state, tweak the implementation, or resolve incoming review comments without leaving the TUI.
- Deterministic phase transitions: The code decides what runs next, persists artifacts, and enforces the review gates, while the agent does the thinking; it doesn't get to invent the workflow as it goes.
This is the part that should not be left to the agents. Agents are probabilistic; they can lose track of state, skip a step, or confidently continue from a bad assumption. The more unpredictable the intelligence layer becomes, the more valuable it is to have a boring, deterministic harness around it.
Does this work?
Your mileage may vary.
Back in March, Anthropic published this article on long-running agents in which they presented a challenge with the following prompt:
| Create a 2D retro game maker with features including a level editor, sprite editor, entity behaviors, and a playable test mode. |
I tried the same thing with Agentic Orchestrator using the full autonomous mode — in other words, no answers required from humans. After 12 hours, $250, and absolutely no extra tweaks, this was the result:
Granted, this used Opus 4.7 for all phases, as opposed to 4.5 used by Anthropic in their demo.
This is starting to feel a lot like Opus-powered espresso.
So, have we solved software engineering?
Not yet, but we are quite close to solving coding at this point.
The models are improving at a pace that makes quarterly planning feel like geological time. Features that require five loop iterations today may be done with a one-shot tomorrow. We’ll keep pushing the context window ceiling higher, forcing the loop pattern to exist at all. The review gate that catches an agent's mistakes will fade in importance as agents make fewer errors. If we're lucky, the Agentic Orchestrator itself will be obsolete in a few weeks, rendered unnecessary by models that can hold an entire feature in their “head” without needing a progress file to remember what they were doing. Honestly, that would be the best possible outcome. I didn't build it because I wanted to build an orchestrator. I built it because the unsupervised agents weren't good enough to function without one.
But even in a world where the models are ten times more capable than they are today, there is one thing I'm increasingly convinced won't change — human domain knowledge and our fundamental understanding of systems can’t be replaced.
Here's what I've learned after weeks of living in this workflow: The quality of what comes out is still circumscribed by what you put in. The agents aren't magic. They're amplifiers. If you feed them a vague prompt, you get a vague implementation. If you don't understand the codebase well enough to answer their questions, they'll make assumptions, and those assumptions will be wrong.
The role of the software engineer is changing, not disappearing.
When your programming language is English, the skills that matter shift. You still need to be a good engineer, arguably more so than before, but the nature of the work changes. There is less typing and more thinking, less syntax and more architecture. We’ll stop asking how to implement something and begin asking what we should implement and why. The software engineer’s value isn't in writing code anymore. It's in knowing what the right code looks like and being able to articulate that clearly so an agent can produce it.
The model I've landed on looks something like this: During the day, the human does human work. You write prompts. You answer questions. You review plans. You make judgment calls about edge cases and trade-offs. Then the agents go off and implement for hours — overnight, over lunch, or while you're in meetings. When you get back to the computer, you can review the PR, tweak what needs tweaking, publish, and move on. The human provides the intent and the judgment. The machine provides the labor and the stamina. It’s delegation in its purest form and, like all delegation, it requires the delegator to know what they're actually talking about.
A note on work density, addiction, and mental health
I want to shift tone here, because this part matters.
There's a narrative in the AI productivity discourse that goes something like: "AI tools free up your time so that you can focus on the creative, high-value work." This sounds wonderful. It is also, in my experience, mostly wrong.
A recent BCG study of 1,488 workers found something that resonated deeply: Productivity self-reports increased when using one to three AI tools, but plummeted with four or more. Workers reported more mental effort, greater mental fatigue, and more information overload when AI required higher oversight. The study's author, Julie Bedard of BCG, described workers feeling they were "reaching the limits of their brain power."
And I felt it, too. Here's what actually happened when I got the agentic workflow running smoothly. I didn't work fewer hours. I worked the same hours, but with a dramatically higher density. Instead of writing code for eight hours, I was making judgment calls, context-switching between features, reviewing implementations, answering agent questions, and writing prompts for eight hours straight. The mechanical downtime, the typing, the debugging, the breathing room I had while I wrote the boilerplate and reflected on what I was doing was gone. Every minute involved making decisions. Every minute increased my cognitive load.
I found myself more tired at the end of the day, not less. I was more drained, not more energized. And there's a subtle addiction to it: When you can kick off a feature before bed and wake up to a PR, the temptation to kick off three features before bed is overwhelming. The agents don't get tired. But you are still the bottleneck for every question they ask and every plan they propose. The work compresses, and if you're not careful, it compresses you with it.
I don't have a neat solution for this. We are in an awkward transition period where the tools have outpaced our ability to use them sustainably. We're all figuring out the ergonomics of a fundamentally new way of working, and pretending it's all upside does a disservice to everyone trying to navigate it.
Take breaks. Set boundaries. Remember that the agents will still be there in the morning. And if you find yourself refreshing the dashboard at midnight to see if the review gate passed, close the laptop. I say this from experience. The PR can wait.
Go build something!
I started here saying I'm an intermediate user at best. Even after writing all of this, I still believe that. The difference is that I now know the shape of the learning curve and I can tell you: It's worth climbing.
Here's what I'd tell someone starting from scratch today: Don't try to boil the ocean. Start with a small task on Cursor or Claude Code. Get comfortable with the rhythm of prompting, reviewing, and iterating. Then try the RPI framework on a single feature — research first, then plan, then implement. You don't need anything fancy. Just open three Claude sessions, one for each phase, and pass the artifacts manually. Feel how different it is when the agent has context from its own research instead of your hastily written prompt.
Once that clicks, and it will click, you'll start seeing the gaps that better tooling can fill. Maybe you'll build your own orchestrator. Maybe you'll use mine. Maybe by the time you read this, there will be something better than both. That's fine. The frameworks and the tools will keep changing. The mental models won't, at least not as fast. Research before you plan. Plan before you implement. Loop when you run out of context. Let the agent ask questions. And know your codebase well enough to answer them.
The espresso machine isn't fully automatic yet. But it's no longer a manual pour-over, either. We're somewhere in the semi-automatic range, and the shots are getting better every week.
Now go experiment. And when you find something that works, share it, because I guarantee someone else is stuck exactly where you were last month.
