

Following our earlier engineering overview of Ask DoorDash, this third post in the blog series takes a close look at the evaluation harness behind the system. Deep dives on the platform and user experience will follow.
Introduction
Building a useful AI agent is hard when quality is only visible through scattered reports and manual checks. That was the problem we faced with Ask DoorDash, our recently launched agentic ordering experience. In the early development stage, evaluation relied mostly on employee feedback and manual testing. Those signals helped, but they were sparse and skewed toward the scenarios we already knew to look for.
We built an evaluation harness to make agent quality observable at scale. The quality signal expanded from an average of 1 employee-submitted feedback to 2,000 auto-graded sessions per day. That broader signal helped us catch trust-burning agent failures sooner and prioritize recurring failure modes; acting on it, we drove an 8-point improvement in agent quality scores ahead of nationwide launch – cutting error rates nearly in half and meeting our production launch bar. The evaluation harness also made pre-ship validation much faster: a comprehensive regression test that previously took more than 6 hours by hand now runs in about 20 minutes, making it practical to evaluate changes as large as a base-model migration that reduced latency by 35% while preserving quality.
This post explains how we developed that evaluation harness: the rubrics that define success, the transcript builder that reconstructs sessions, the simulator that creates repeatable offline runs, and the calibrated LLM judge that makes session-level evaluation scalable.
The Fundamental Challenges
Ask DoorDash helps users discover restaurants or shop for groceries through multi-turn conversations. Behind the conversation, the agent calls tools to interact with the DoorDash system and act on the user’s behalf. That means agent quality has to be assessed across the full interaction, not by a single response. Evaluation needs to account for both the user-facing messages and the hidden tool calls.
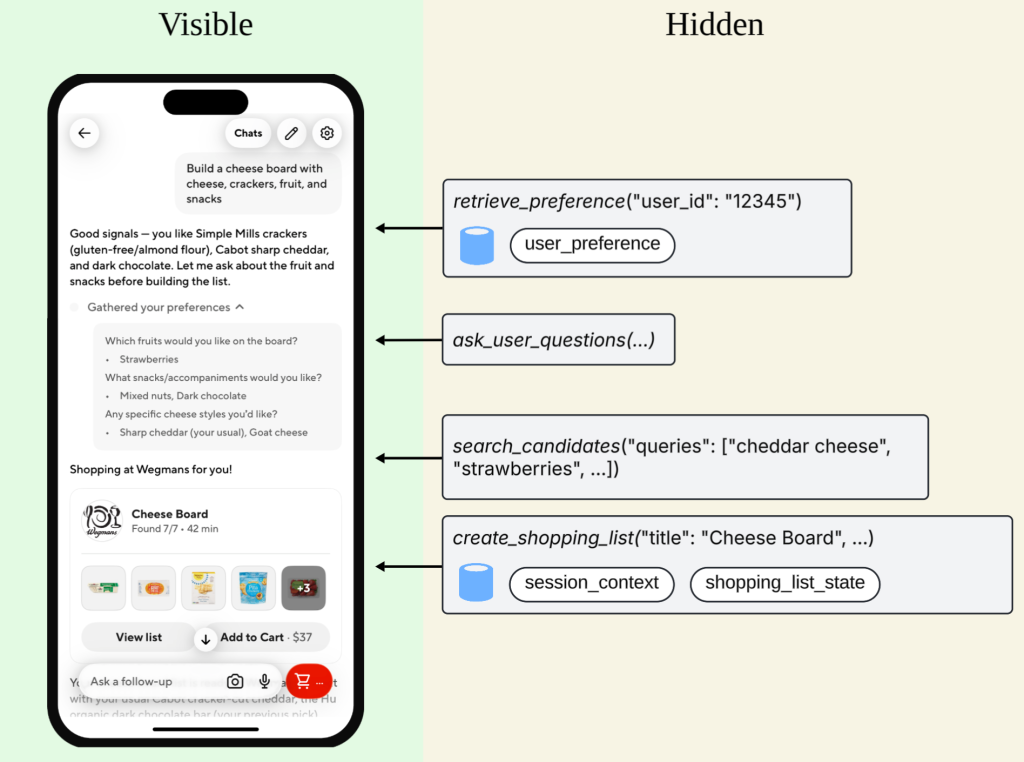
Figure 1: Evaluation should consider both the visible conversation and the hidden tool trajectory.
Building evaluation harness for Ask DoorDash requires turning the open-ended problem of agent quality into concrete system requirements. The table below summarizes the main challenges we had to solve and how each one shaped the design.
| Challenge | Requirement |
| Open-ended goals. A user goal has many acceptable outcomes; there is rarely one right answer. | Express each goal as a rubric – criteria specific enough to judge the same way every time, yet broad enough to credit the different valid paths a task allows. |
| Execution visibility. Agent quality cannot be graded from conversation alone. The judge also needs to see what the agent did underneath. Different criteria need different parts of that execution record. | Trace the session and reconstruct it into criterion-specific views, so each judge sees the conversation and execution details needed for that rubric item without unrelated trace noise. |
| No safe rehearsal. A change cannot be vetted on real users, and a past session cannot be replayed against a modified agent. | Generate sessions on demand: a simulated user drives the agent through a chosen scenario, with the surrounding data held fixed so the same scenario runs the same way every time. |
| Judgement at scale. Deciding whether a session helped the user takes human-level judgment, but human grading won’t scale. | An automated judge that stands in for a human reviewer: an LLM judge calibrated against human-labeled sessions so the verdicts are trust-worthy. |
| Two environments. Quality in development and quality in production can diverge, and we need both. | Measure real and simulated sessions with the same rubric and the same judge, so an offline result carries to production and a live failure can be reproduced offline. |
What We Evaluate, and Where
Ask DoorDash uses a multi-agent architecture. A user’s message first reaches the Orchestrator agent, which routes the request to a specialized domain agent (e.g., the Restaurant Discovery Agent). The selected domain agent then either handles the conversation directly or returns control to the Orchestrator when the request needs to be rerouted.
The evaluation system mirrors that shape. Because different failures show up at different points in the pipeline, we evaluate each layer where it can be measured most directly: routing at the Orchestrator, guardrails across the full flow, and task-specific capability at each domain agent.
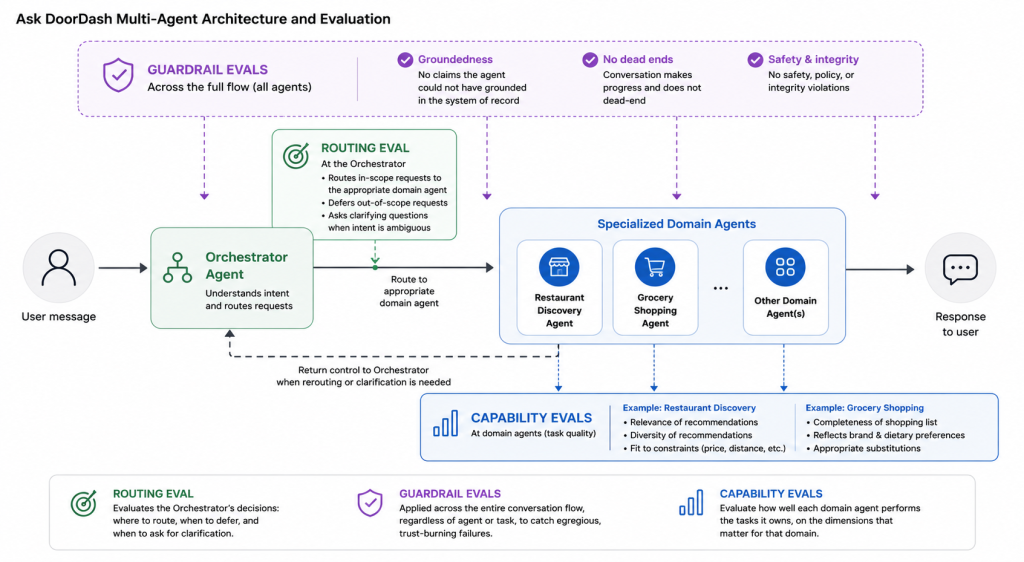
Figure 2: Evaluation mirrors the agent run-time architecture.
Inside the Eval Harness
Behind these evals sits a single harness whose pieces map back to the requirements outlined earlier. A rubric defines what a good session looks like, and a transcript builder turns a raw session into something a judge can read. An LLM judge, calibrated against human reviewers, scores that transcript against the rubric. A simulator then generates sessions on demand for offline runs. Because these pieces build on one another, we take them in that specific order, starting with the rubric.
Rubric
A rubric defines the criteria used to evaluate a session. Writing a good rubric requires balancing specificity with generalizability. The criteria must be specific enough to support consistent grading, but generalizable enough to accept all valid responses. Since many tasks do not have a single “right answer,” the rubric should describe what a successful session looks like rather than prescribe one exact outcome. The below table gives example dimensions and criteria from each eval. Each criterion is graded as a binary check, and the individual checks are aggregated into a final session-level score.
| Eval | Agent | Dimension | Example Criterion |
| Guardrail | All agents | Communication quality | The agent kept the response brief and did not narrate its train of thoughts to the user. |
| Trust and integrity | The assistant did not present verifiably false information or made claims that flatly contradict what the customer was shown | ||
| Capability | Restaurant Discovery | Constraint satisfaction | The recommended restaurants satisfy the request's explicit constraints on delivery time, budget, and dietary. |
| Result diversity | The set offers real variety rather than near-duplicates | ||
| Grocery Shopping | Shopping execution | User’s explicit requests to modify the shopping list are executed. | |
| Item relevance | The selected items are relevant to the user’s state goals. |
What counts as a good flow depends on the user’s intent. A grocery reorder, a recipe request, and a restaurant search each define success differently. Some flows also rely on purpose-built tools or skills, so not every criterion applies to every session.
Each criterion has an eligibility step. Before grading it, the judge first decides whether the criterion applies to the session. If it does not, the judge skips it. That way, a recipe flow is not marked down for missing a reorder-specific step. The guardrail and capability rubrics work this way against both real production sessions online and simulated sessions offline.
Offline, we also run a checklist-style rubric: a scenario-specific list of what a correct run should produce. For a “vegetarian taco grocery list for two under $60” session, the checklist verifies that every item is a relevant ingredient for making vegetarian taco and the subtotal is at or below $60.
These checks give the offline eval a lower-variance signal than broad, general-purpose criteria alone. They let us test specific behaviors directly, making a small sample more useful and supporting faster iteration. The mechanics of constructing the test setup are covered in the conversation simulator section below.
Every criterion is written to be verifiable from the session itself. This lets the same rubric be used by a human reviewer during calibration and by the LLM judge at scale. Both need the session in a readable form, which is what the transcript builder produces.
Transcript Builder
We instrument each agent session with OpenTelemetry. Each session becomes a trace, which we store in an internal ClickHouse instance. Its spans record the steps the agent took, including the user’s input, the model’s output, tool calls and responses, and the widgets shown to the user. That full record is the raw material every eval starts from.
The raw trace is complete, but hard to grade directly. Some tool responses are very large, and much of the content keeps the record well formed, such as schema scaffolding and fields that carry no signal about agent quality. The evidence for a criterion can also be spread across several spans or turns,so it has to be reassembled before a judge can use it.
The transcript builder is a set of Python scripts that runs over the stored traces before evaluation. It reassembles scattered spans, removes tokens that carry no quality signal, and trims oversized payloads. The result is a compact view of the conversation and the work behind it. A judge can grade that view more consistently than the raw trace.
Not every criterion needs the whole view. Each criterion declares the evidence it depends on, and the builder gives the judge only that slice. A grounding check gets the agent’s claim and the tool output behind it. A diversity check sees the recommendations and the original request. A narration check looks at the text the agent streamed while it worked. Scoping the evidence keeps each judgment focused.

Figure 3: The transcript builder turns raw traces into criterion-specific views for more focused and consistent judging.
Conversation Simulator
The Conversation Simulator lets us evaluate a candidate agent before it reaches live users by generating realistic sessions with a simulated user – an LLM playing the shopper. Each run starts from a scenario that defines the opening request, the user’s goal, and how they should react to questions or outcomes, producing comparable multi-turn conversations. When a scenario depends on external state, such as prior Safeway orders, an in-progress cart, or store inventory, the harness uses fixtures: recorded tool payloads returned instead of live calls. This keeps every run pinned to the same state, avoiding drift from catalog changes, store availability, or test-account history. For example, the reorder scenario opens with “Reorder my usuals” and fixes get_reorder_items to a recorded order history.
// simulating reorder scenario
{
"evalId": "mt-reorder",
"sessionInput": {
"state": {
"__tool_fixture_pack_names": [
"reorder_history_v1"
],
"max_turns": 3
}
},
"conversationScenario": {
"startingPrompt": "Reorder my usuals",
"conversationPlan": "You want to reorder your usual groceries.."
}
// ...
}
// reorder_history_v1 — returned in place of the live get_reorder_items call
{
"success": true,
"orders": [
{ "store_name": "Albertsons", "order_date": "2026-04-22T18:30:00Z",
"items": [
{"name": "Meadow Gold Whole Milk Jug (1 gal)", "quantity": 2},
{"name": "Oroweat 100% Whole Wheat Bread (24 oz)", "quantity": 1},
{"name": "Signature Select Hass Avocados (5 ct)", "quantity": 1},
{"name": "Ben & Jerry's Half Baked Ice Cream", "quantity": 1}
// ... more items
] }
// ... more historical orders
]
}Every run of this scenario sees exactly these orders. That makes the expected outcome predictable: the agent’s curated list should be drawn from the fixed order history, and the judge can grade it against that same set of items every time.
Conversation simulation made the input side of offline evaluation practical. For Ask DoorDash, a typical comprehensive sweep covers 50 scenarios with 8 trials each, producing 400 generated conversations. Without simulation, generating that suite means a developer has to chat with the agent locally, one conversation at a time. At about 1 minute per conversation, that would take more than 6 hours. The simulator reduces that generation step to about 20 minutes.
LLM-as-a-Judge
In practice, agent evaluation is a measurement problem with a tight feedback loop. We need enough samples to estimate production quality every day, and scores fast enough to catch regressions before they spread. The same constraint applies before launch: each candidate change produces its own sessions, and the eval has to return quickly enough to stay in the development loop rather than become a release bottleneck.
That scale rules out human review as the default grading path. A reviewer can make the right call on a hard transcript, but each session is expensive to inspect. It can include many turns, tool calls, model outputs, and rendered widgets, and the reviewer has to connect the agent’s claims back to the evidence in the trace.
Human review is still essential, but we use it where it has the most leverage: defining rubrics, labeling calibration sets, and auditing judge behavior. The bulk of grading goes to an LLM judge, which reads the prepared transcript and scores it against the rubric.
An LLM Judge is only useful if it agrees with human reviewers.
We applied GEPA prompt optimization to refine the judge’s decision boundaries. The algorithm iteratively proposes revisions to the judge prompt and keeps the ones that improve agreement with the human labels on a held-out set. This calibration is ongoing: as rubrics evolve, such as when new capabilities are added, we collect fresh labels and recalibrate the judge.
The judge scores each criterion independently. It receives the criterion and the evidence that criterion depends on, then returns a verdict with a short rationale. With this setup, we expanded quality monitoring from about 1 employee-submitted feedback to 2,000 auto-graded sessions per day.
Eval Service
Building a scalable eval harness depends heavily on robust platform infrastructure. Trace storage, real-time eval execution, UI-based judge development, and annotation workflows do not come for free. We started with an embedded platform team that built these pieces alongside the Ask DoorDash eval harness, creating a tight feedback loop between platform development and eval design. That let the infrastructure and harness evolve together. That close collaboration accelerated eval development for Ask DoorDash and is now shaping a shared eval service – a paved path that other DoorDash teams can adopt quickly while still customizing it for their own use cases.
The Feedback Loop
The eval harness gives us a scalable way to measure agent quality. The next question is how that measurement changes the development loop.
Clustering Failures into Themes
A daily eval run can surface many failures, but inspecting them one by one makes the iteration loop anecdote-driven. The most recent or surprising failure can dominate the fix, even when it is not the most common failure mode. We need to identify the broader patterns behind the failures and how often they occur, so we can prioritize the issues with the greatest impact across sessions.
The rubric gives us a useful starting point. Each failed session already carries the criterion it violated, so rubric criteria act as natural issue clusters. A grounding failure, a missing substitution, and a poor narration failure are different problems and should usually be investigated separately. Grouping failures this way turns a long list of examples into a ranked set of themes.
From Detection to Resolution
Clustering tells us what is failing most often, but deciding why it is failing and how to fix it requires implementation context. As AI-driven development makes code and prompt changes faster to produce, the bottleneck shifts to choosing the right change and validating its impact. Starting from a failure cluster, a coding agent can inspect failing traces, relevant code paths, recent changes, and prior investigations. When the fix is clear, it can draft a pull request directly; for prompt or in-context-learning changes, it produces a diagnosis and proposed change for human review.
Agent Skills
We package these eval-driven development workflows as Agent Skills. Each skill defines a repeatable task, such as clustering failures or investigating a failure mode. This makes the workflow easier for other teams to adopt and easier for us to improve over time. When a skill misclassifies a cluster or drafts a weak fix, we update the skill rather than patching a one-off run, and that improvement carries forward to future invocations.
The eval harness provides the signal, and Agent Skills turn that signal into an operational workflow. Together, they make the harness more than a scoreboard: a control plane for iteration that connects production monitoring, failure clustering, agent-assisted investigation, and pre-ship validation into one loop.
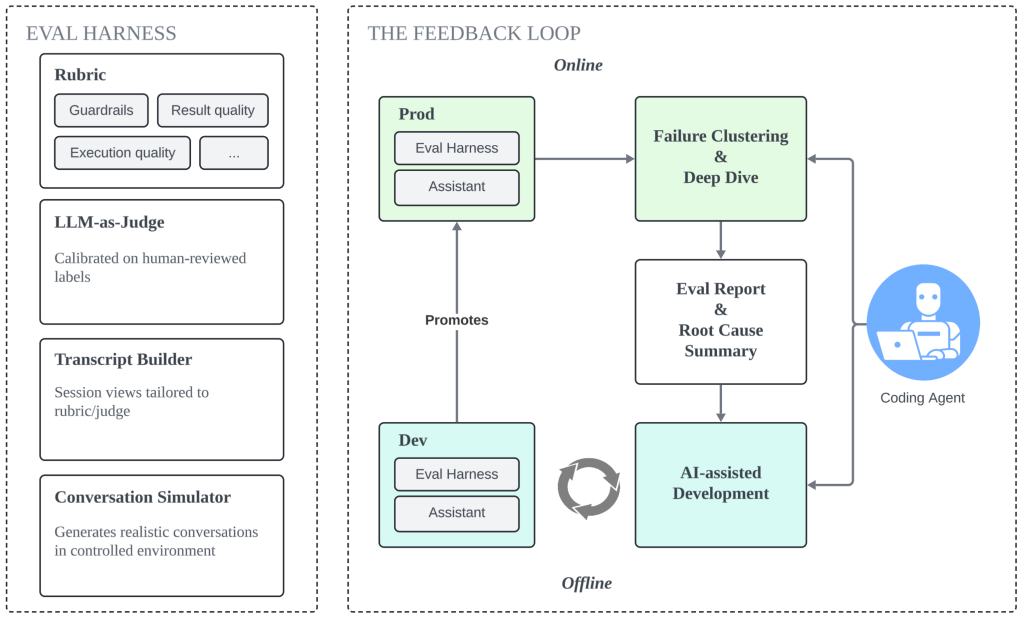
Figure 4: The feedback loop turns eval into a continuous path from observed failures to validated improvements.
From Eval Signal to Production Impact
Reducing reasoning leakage
A recent grocery-agent issue shows the eval-driven development loop in practice. Daily online scoring surfaced a spike in reasoning leakage. The agent completed the task, but its user-facing narration occasionally used system-oriented language, such as “reorder skill,” tool names, or software-like phrases like “fetch” and “in parallel.” The response sounded more like a coding agent than a shopping assistant.
The diagnosis pointed to prompt design, so we consolidated the agent’s communication rules and separated internal skill instructions from user-facing language. We validated the change offline with scenarios that were most prone to this failure mode in production traffic and saw the leakage rate drop by 11%. We also ran a full eval sweep across hero scenarios and found no attributable regressions. After shipping, online monitoring confirmed a step-change improvement.
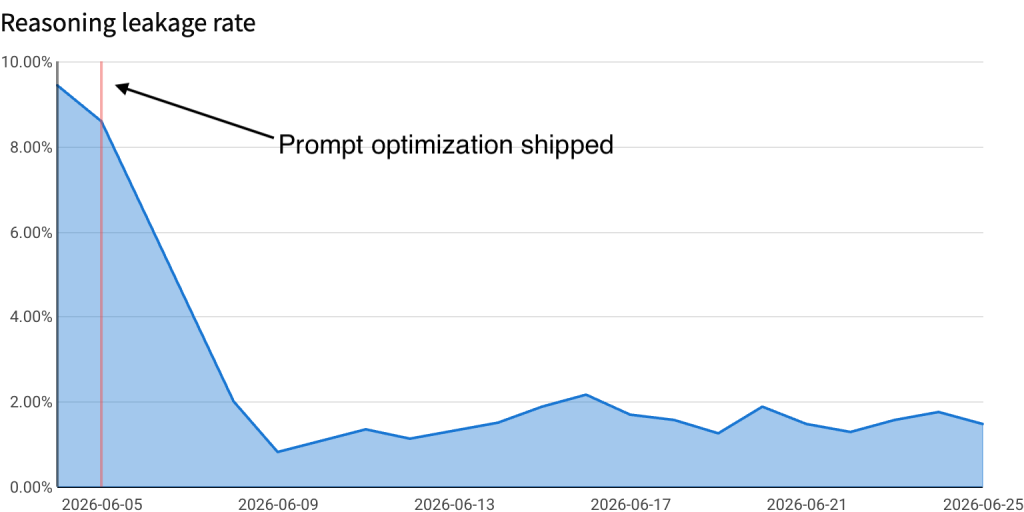
Figure 5: Eval enabled identification and reduction of reasoning leakage in user-facing messages.
De-risking a base-model migration
When Gemini 3.5 Flash shipped in mid-May, our agents were running on Claude Sonnet 4.6. Flash’s benchmark pointed to an opportunity: reduce Ask DoorDash latency so the agent felt responsive rather than stuck. But a base-model swap is risky because it can change agent behavior across the system. We needed to know that quality would hold before exposing users to it.
We ran Flash through the offline harness, and the scores dropped sharply. The eval surfaced concrete failure patterns, and we pointed AI coding agents at those patterns to form hypotheses and run experiments. What uncovered was not a capability gap, but a compatibility one. Flash formatted some tool parameters differently than Sonnet and interpreted parts of a system prompt that had been tuned implicitly around Sonnet’s conventions. The low scores reflected a system adapted to Sonnet, not a weaker model.
That diagnosis pointed to a set of small, targeted fixes. Some were deterministic guards on tool inputs – Flash would occasionally pass a search query as a JSON object like {"dishes": [...]} where the tool's signature declared a plain string, so we coerced these back into the expected shape instead of dropping the call. Others were prompt updates that stated explicitly what Sonnet had inferred on its own, such as using the exact store name from the data and not embellishing beyond what the tool results support. We were not changing the model; we were correcting the environment around it.
Re-running the eval brought Flash back to quality parity with Sonnet, within the noise of the harness. We migrated the production agents and monitored quality and engagement in live traffic. The win held – a 35% latency reduction with no loss in quality metrics.
Together with the reasoning-leakage example, this shows the harness working in both directions, turning production quality signals into fixes and de-risking deliberate system changes before rollout.
Lessons Learned
Judges need transcript views shaped for the question. The raw trace often carries more than the criterion needs. Some spans are unrelated to the criterion. Even the useful spans can include schema scaffolding, repeated fields, and payload tokens that exist only to keep the data well formed. We get better results by removing what is irrelevant and keeping the evidence the criterion actually depends on.
The environment has to be controlled, or the score measures noise. Upstream drift and the agent’s own non-determinism can both move a result, which makes it hard to tell whether a change actually helped. Fixtures freeze the upstream world, and fixed scenarios keep the task conditions stable, so metric movement is more likely to reflect the agent rather than its surroundings.
An offline result only matters if it carries to online. That is why the same rubric and calibrated judge run in both places. If online and offline use separately tuned judges, their scores can diverge in ways that are hard to reconcile.
The eval system also produces its own bug reports. A real share of flagged failures are faults in the harness rather than agent issues, usually a judge false positive or a tracing gap that gives the judge an incomplete view. Addressing those in parallel keeps the eval trustworthy.
Conclusion
For production agents, evaluation cannot be an afterthought. It has to be part of the system from the start. But scoring sessions is only the first step. The harder problem is turning those scores into better agent behavior.
The harness closes the gap between measurement and improvement. It expanded daily quality monitoring from roughly 1 employee-submitted feedback to 2,000 auto-graded sessions, and cut comprehensive regression testing from more than 6 hours by hand to about 20 minutes. Those gains empowered us to catch production issues earlier, prioritize recurring failure modes, and validate large changes before they reached users. The result was measurable production impact, including an 8-point improvement in agent quality scores ahead of nationwide launch and a validated base-model migration that reduced latency by 35% while preserving quality.
A scalable eval harness requires robust platform infrastructure. Close collaboration with the platform team accelerated the development of agent eval harness for Ask DoorDash. This foundation work is now shaping a shared eval service.


