

As DoorDash migrated from a monolithic codebase to a microservices architecture, we found an opportunity to refine our API design. Beyond simple functionality, we determined best practices in making APIs that help our applications load quickly, use minimal storage, and, most importantly, avoid failures.
APIs, the connective tissue of a software platform, can offer performance improvements when properly designed. At DoorDash, the APIs relay frontend client requests to backend services and provide the information that users see in our apps, such as the estimated time when a food order will be delivered. If the APIs perform at maximum efficiency, client requests and responses all process more quickly.
The migration to a microservice architecture gave DoorDash the opportunity to revisit our API design, specifically determining how to optimize the information flows. We came up with best practices around targeted endpoint requests, resulting in significantly reduced latency and errors.
Building orchestrated APIs using domain-specific services
DoorDash’s previous platform, a monolithic codebase combined with a single database, made constructing queries very easy. However, a lack of clear boundaries contributed to errors and inefficiencies. Engineers could code anything they wanted into their API responses, drawing from any part of the monolith, raising the potential for an API to deliver a hodgepodge of information in an overly large response.
For example, consider a simplified version of a request to retrieve consumer order details, as shown in Figure 1, below. When the request server processes the request, it queries a series of tables in the database and returns a large response including the order and delivery details, store information, and promotions, which are not all needed after the order has been placed.

Also, business needs, such as new end-user features, may require that engineers add more functionalities to the API to support new types of interactions over time. Eventually the API loses its generality and becomes difficult to maintain.
In our new architecture, we introduced a backend-for-frontend (BFF), an application connecting the consumer-facing client and the services providing general purpose APIs. Client requests go to the BFF, which then orchestrates the aggregation of information needed by the client.
As shown in Figure 2, below, when the BFF receives the order details request, it orchestrates the calls to the consumer service, order service, and delivery service, ultimately assembling the response details into a consolidated order detail response. Building APIs using domain-specific services, orchestrated by the BFF, makes it easier to understand which RPCs are called and how they are executed.

The need to standardize hard and soft dependencies in a microservice architecture adds complexity versus a monolithic codebase. However, we can set our call to the services’ endpoints to Fail Open to some dependencies so that if the dependencies fail, the endpoint will continue to serve successfully. In our monolith, a database issue may bring down the endpoint easily regardless of soft or hard dependencies, causing more widespread failure.
Stay Informed with Weekly Updates
Subscribe to our Engineering blog to get regular updates on all the coolest projects our team is working on
Please enter a valid email address.
Thank you for Subscribing!
Last but not least, implementing APIs in the above manner allows for quick troubleshooting when the endpoint suffers performance degradation, as we can isolate which service is causing the issue. Once we understand the problem, we can be more responsive in taking remedial actions.
Focus on what the API needs to provide
Orienting services around domains helps provide guidance for the boundaries along which APIs should operate. The BFF orchestrates the interaction between backend APIs to render responses that meet the needs of clients, but in this framework we should be careful about mixing different APIs from different scopes. The most important thing to determine during design is the API’s role.
At DoorDash, our APIs primarily support information on food orders, whether that’s an order placed by a consumer and sent to a restaurant, a delivery request sent to a Dasher, or a Dasher’s progress in bringing a food order to a consumer. For example, two main endpoints, order detail and order delivery status, populate our order tracking page, shown in Figure 3, below:

In our previous monolithic codebase, the order detail API provided all the data when loading the order tracking page, including the order items, order delivery address, order processing status, ETA, and the map. The client, web or mobile, uses the data from this order detail endpoint to render the page and then polls the order delivery status to update the order processing status, ETA, and map. We can find that both the order detail endpoint and the order status endpoint interact with the services providing order tracking information.
The order tracking page needs to show two types of data: static data about what was ordered and dynamic data about the order’s status. Even though we consider the order live when it shows up on the order tracking page, there is no need to include the order tracking detail in the order detail API since there is an order status endpoint to serve it. Clients can make the two requests in parallel when loading the page. Also, once the order is completed, we still need to show the order details to, for example, let consumers see their order histories. However, order tracking data becomes unnecessary after the order has been delivered, at least in this order history use case.
Given the use case above, it makes sense to separate the endpoints that provide static data and dynamic information. Order detail endpoints don’t need to integrate delivery status, ETA, and map data. The client only relies on the order status endpoint to render and refresh the page’s dynamic area. In redesigning our APIs, we remove the order processing status, ETA, and map response from the order detail endpoint. Creating APIs with well-defined functionality makes dependencies clear, testing easy, and users’ logic behavior consistent.
An API needs to answer the most important question posed by the workflow. We need to understand the user scenarios, identify the data characteristics, and comprehend the business logic behind it. We should always think twice about an API’s role when designing a system.
Simplified and optimized request flows
Every request sent from consumers contains meaningful information. Analyzing the flows between the client and backend lets us determine what can be optimized when migrating the endpoints. Can we optimize to eliminate unnecessary requests? Can we empower client API requests to execute on the page in parallel instead of serially?
Take our Reorder flow as an example. The Reorder feature lets consumers place the same order from their order history with a simple click. In this flow, the GET order cart detail is called, followed by a POST reorder to create a cart using the existing order content, where we return a new order cart to the client, as shown in Figure 4, below:

When we redesigned the Reorder endpoint, we wrote the Reorder API so it would read the order information it needs to create the new cart instead of passing the large order data over the network to create the new cart, as shown in Figure 5, below:

The client only needs metadata for the new cart from the Reorder endpoint, so we only return a cart summary response to the client instead of the whole cart. Compared to the previous flow, shown in Figure 4, we not only eliminate the request to call GET order cart from the client, but also make both the request and response very light.
Results
Redesigning our APIs to focus on their specific roles yielded significantly reduced latency and error rates. For the use cases cited above, both the order detail endpoint and order history endpoint process a high volume of traffic. Our API improvements show that:
- For the order detail endpoint, we reduced endpoint latency by over 90%, a 30 times improvement. For P99, as shown in Figure 6, the latency has been reduced from greater than 2,000ms to less than 100ms. In terms of error rate, shown in Figure 7, we achieved a 60 times improvement, going from 0.3% on average to 0.005% (actually, the new endpoint often shows 0% error).


- For the order history endpoint, we achieved a 10 times reduction in endpoint latency, as shown in Figure 8, and an error rate for the new API of 0% for almost all the time, as shown in Figure 9.


These API improvements led to a perceivable improvement on the client side. When we place a test order with a couple of items the response size of the old API was 72kb (71.4kb exactly), while it is 1kb (1.1kb exactly) using the new API, as shown in Figure 10:
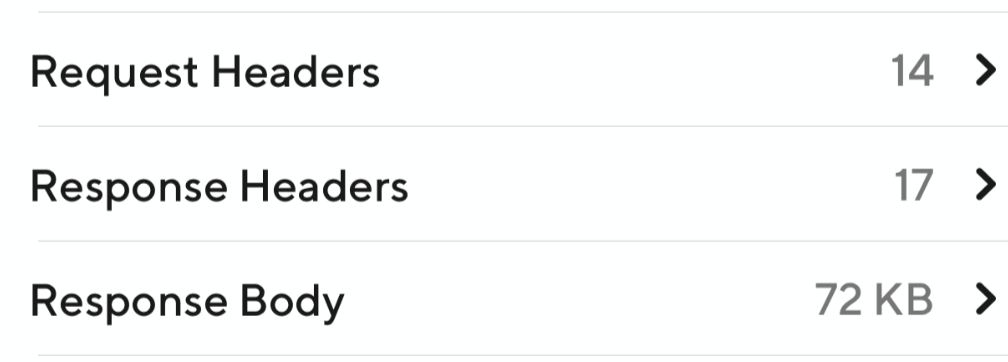 |  |
When viewing actual client response on our consumer app, the loading experience runs much more smoothly when using the new APIs, as Figure 11 shows:
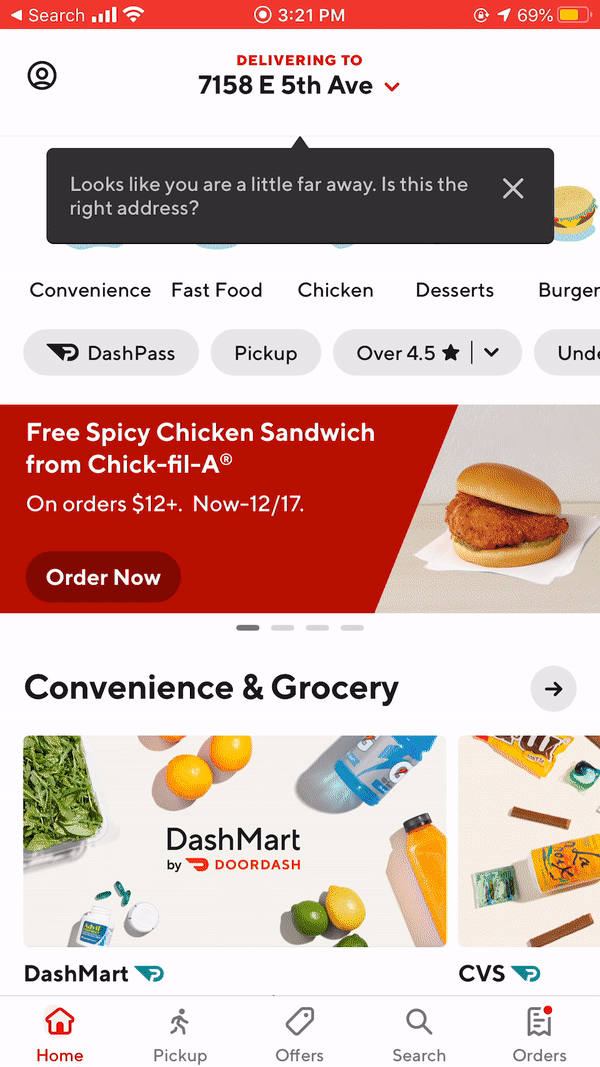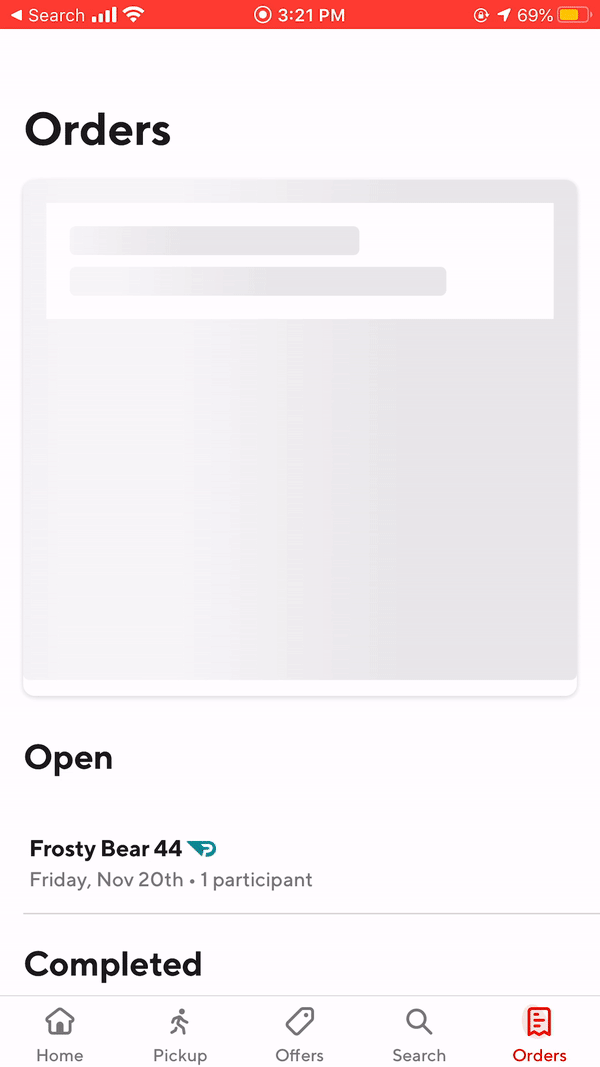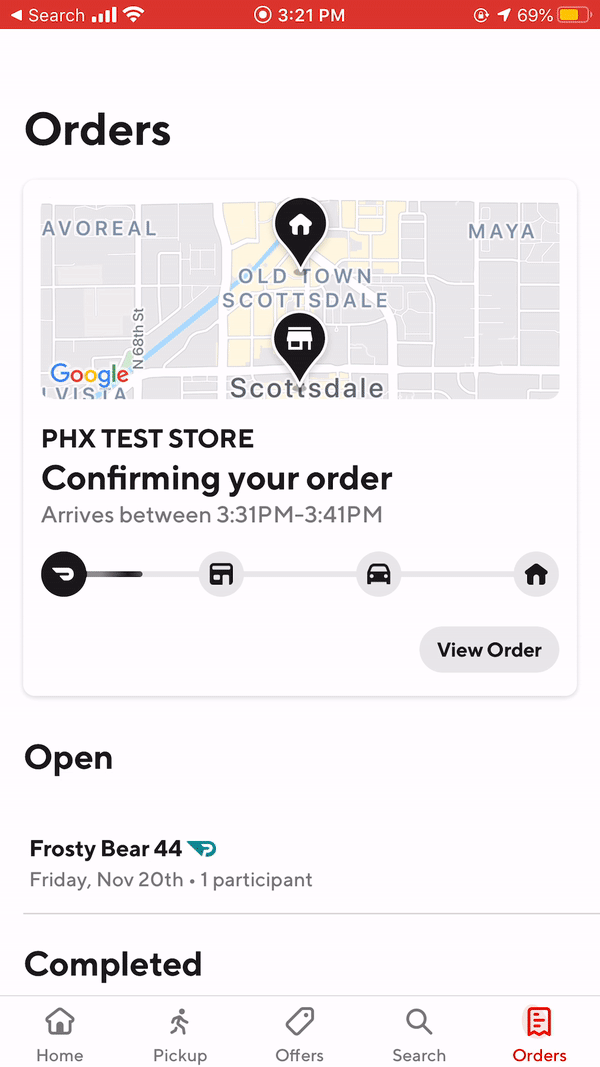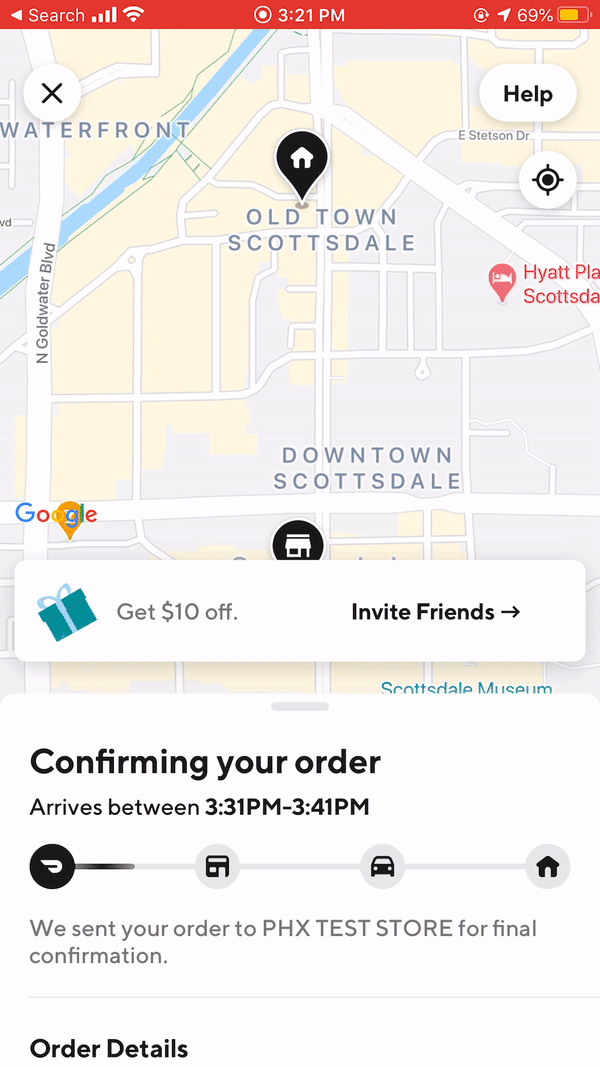 |  |
Conclusion
From database infrastructure to app programming, there are many ways technology companies can improve the customer experience. Good, targeted API design might be one that falls under the radar, yet can deliver significant improvements.
In our case, we were given the opportunity to redesign our APIs during a migration from a monolithic codebase to a microservices architecture. However, any technology company, especially those with a great amount of legacy code in their platform, might find it useful to assess their APIs. There might be opportunities to reposition the APIs, removing overly large requests and reducing load on networks, while making clients run more quickly and becoming less error-prone, ultimately delivering a better customer experience.
Acknowledgements
Big thanks to my awesome teammates, Tao Xia (backend), Byran Yang (Android), Donovan Simpson (iOS), and Thuy-Vy Do (web), for working with me on this project. Also, many thanks to David Shih, Irene Lee, Alejandro Valerio, Cesare Celozzi, Amiraj Dhawan, Yimin Wei, Zhengli Sun, and Jimmy Zhou for their support.
