

Knowledge at DoorDash is vast and distributed, spread across experimentation platforms, metrics hubs, dashboards, wikis, and the institutional wisdom embedded in team chats. Historically, answering complex business questions required significant context-switching: Searching the wiki, asking in Slack, writing SQL, and filing Jira tickets. To bring this vast smorgasbord of knowledge into a cohesive whole, we developed an internal agentic AI platform designed to be a unified cognitive layer over DoorDash's data and operations.

Here, we outline our findings as we transition our agentic platform from a collection of capable, but siloed, assistants into a collaborative ecosystem. Our journey focuses on the architectural patterns that enable sophisticated agent-to-agent (A2A) interactions. We detail here our progression from simple, deterministic workflows to our current work with deep agents and our exploration into dynamic, asynchronous agent swarms. Because this is an evolving project, what follows is a snapshot of our progress, direction, and the lessons we’re learning along the way.
Evolutionary path of multi-agent collaboration
Building a robust multi-agent system is a journey of increasing complexity and capability. We've learned that you can't jump straight to sophisticated, multi-agent collaboration; you must first build a solid foundation. Our approach follows a clear evolutionary path, with each stage building upon the last while introducing new levels of autonomy and intelligence. Figure 2 illustrates these architectures—workflows, agents, deep agents, and swarms—arranged along a continuum from deterministic pipelines to long‑horizon collaboration.

Workflows as a foundation for determinism
A workflow marks the starting point for any automated AI system and forms the bedrock of our platform. Think of a workflow as the digital equivalent of a factory assembly line: A series of steps that are pre-defined, sequential, and optimized for a single, repeatable purpose. Represented as directed graphs, these deterministic pipelines have a clear beginning, middle, and end. There are no unexpected detours and no improvisation.
This rigidity is a critical feature. Workflows are ideal for certified, high-stakes tasks where consistency and governance are paramount. For example, a workflow helped automate summarizing data from multiple sources to generate insights for Finance and Strategy internal reporting use cases. The process used AI agents to pull together input from such things as Google Docs, Google Sheets, Snowflake queries, and Slack threads to develop recurring reports such as business operations, year-over-year trends, and daily business growth. Workflow characteristics, reliability, speed, and auditability make them the system of record for our most important routine operations. By handling the high-volume, predictable tasks, they build a foundation of trust and efficiency, freeing up more advanced systems to tackle ambiguity. As shown in Figure 3, a Snowflake query can feed an AI summarizer, which then writes the result to Google Docs.

That said, workflows are not the only option. In some cases, companies rely on self-service tools that empower users to explore data and generate answers on their own. While these tools provide flexibility, they can be sub-optimal; they assume the user knows which data sources to query and how to interpret them, and that the user has the technical skills to do so correctly. Skillset gaps, inconsistent usage, and the risk of misinterpretation limit their effectiveness for critical or complex analyses. This makes deterministic workflows the more reliable path for high-stakes tasks, while self-service tooling plays a complementary role for ad hoc or exploratory needs.
Introducing dynamic reasoning with agents
Agents are a logical next step to introduce dynamic decision-making. Unlike rigid workflows, agents are adaptive and flexible, using a policy driven by a large language model, or LLM, to decide which tools to call, what information to read, and what to do next. The enabling technology for this leap is ReAct cognitive architecture, which allows an agent to iterate through a think-act-observe loop. This agentic pattern, in which an LLM externalizes its reasoning, has proven so effective that its core principles are evolving and being integrated directly into the models themselves. Early agents were given access to an external "scratchpad" to write out their chain of thought. Now, however, this scratchpad for generating intermediate reasoning steps is increasingly becoming an intrinsic part of the model's training pipeline. Optimal thought generation is fine-tuned during post-training. This evolution makes the think-act-observe loop even more powerful, as well as perfect for navigating uncertainty in exploratory, multi-step questions.
For example, consider the query: *“Investigate the drop in conversions in the Midwest last week.”* An agent would first discern the ambiguity in the request, then act by querying a metrics glossary to define conversions and an internal service to identify states in the Midwest. Based on the results, it would form a precise query to our data warehouse. Upon finding a dip in conversions, its reasoning loop would hypothesize potential causes — such as app rollouts, competitor actions, or holidays — then act by querying the tools available to it, including the experimentation platform, the incident log, and the marketing calendar, until it could isolate a correlation and generate a summary of its findings. As shown in Figure 4, our DataExplorer agent demonstrates this tool‑driven policy by invoking `DescribeTable` to surface candidate tables and by generating grounded starter SQL.
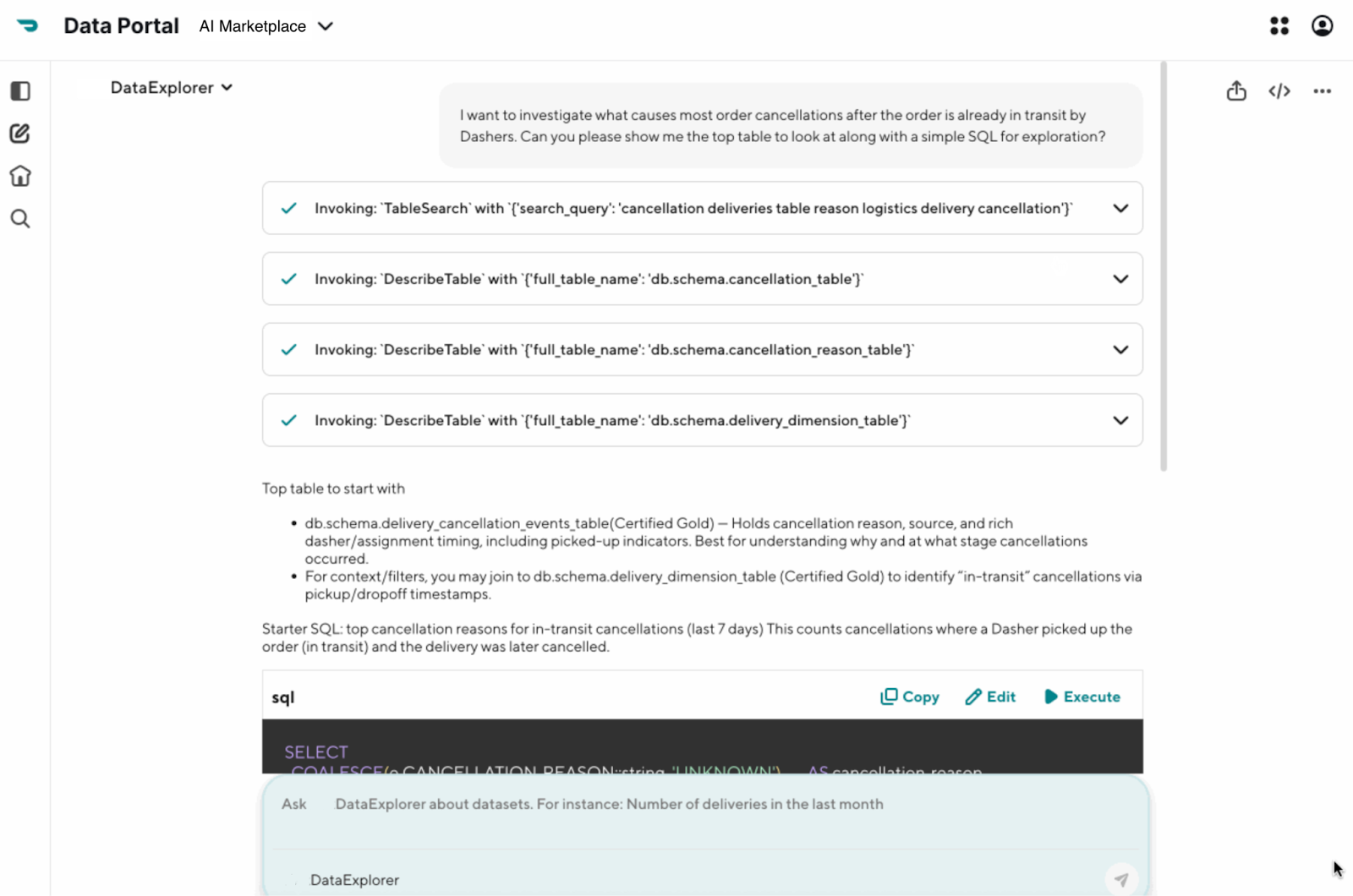
As agents begin to interact with a diverse set of tools, a standardized interface like a model context protocol (MCP) becomes crucial for scalability and governance. The primary challenge for a single agent, however, is context pollution. As it performs more steps, its context window fills with intermediate thoughts. This degrades reasoning, increases token costs, and limits its ability to handle long-running tasks — a limitation that naturally leads to more advanced architectures.
Calling on deep agents to decompose hierarchical tasks
To overcome the limitations of a single agent, the next logical step is to introduce a deep agent. This term describes a collaborative cognitive architecture that involves multiple agents organized in a hierarchy to manage complex, long-horizon tasks. The core principle is specialization and delegation, moving from a single reasoning loop to a pattern of agents calling other agents.
While the planner-worker model is a popular example, more sophisticated hierarchical patterns are emerging. For instance, some architectures use a three-tiered system; a manager agent at the top decomposes a complex user request into a sequence of subtasks, a progress agent tracks the completion and dependencies of these subtasks, and multiple specialist decision agents execute the individual actions. More advanced implementations also incorporate a reflection agent, which reviews an action's outcome to provide error feedback and dynamically adjust the overall plan, adding a layer of robustness.
This hierarchical approach relies on a persistent workspace or shared memory layer. This isn't just a virtual file system; it's a critical component for enabling stateful, long-running tasks. It allows one agent to create an artifact, such as a dataset or a piece of code, that another agent can then pick up and use hours or even days later. This enables a form of collaboration in which the collective intelligence of the system can be applied to problems that are too large for any single agent's context window.
Agent swarms defining the frontier of asynchronous collaboration
Agent swarms are at the pinnacle of our current exploration. This pattern moves beyond a defined hierarchy to a dynamic network of peer agents that collaborate asynchronously. Control is not centralized in a single manager; instead, it is distributed across the entire system. Swarms are defined by the principles of distributed intelligence and emergent behavior — no single agent has a complete picture of the task, but through local interactions, a coherent, intelligent solution emerges.
Think of it less like a corporate org chart and more like an ant colony. Agents in a swarm coordinate dynamically, often through a shared memory layer and decentralized communication protocols, handing off tasks based on expertise and real-time needs. This makes them exceptionally resilient and adaptable to changing environments. The primary challenge — and an area of active research — is in governance and explainability. Because behavior is emergent, it can be difficult to trace the exact decision path that led to an outcome. This makes it all the more crucial to ensure that the swarm's collective actions remain aligned with the original high-level goal. To do that, agent swarms must be decentralized, resilient, and able to handle extremely complex, long-running processes through emergent collaboration.
Our research indicates that true swarm behavior is best unlocked through an A2A protocol. A robust A2A standard must go beyond simple messaging to handle agent discovery, asynchronous state management, and lifecycle events. This provides the foundation for dynamic collaboration, allowing agents to join, contribute, and leave the swarm as needed.
Each of these evolutionary stages — workflows, agents, deep agents, and swarms — represents a distinct paradigm. At DoorDash, we are actively exploring and implementing all of them. Our approach is not to replace one with another, but to build a portfolio of capabilities suited to different problems. We rely on deterministic workflows for our most critical reporting and operational processes where auditability is key. Our teams use single agents for ad-hoc data exploration and analysis, empowering them to quickly answer day-to-day business questions. We are in the process of building and testing our first deep agent systems to tackle more complex, long-term analytical projects that require task decomposition, such as market-level strategic planning. And finally, agent swarms represent our research frontier, where we are investigating their potential to solve our most complex, real-time logistics challenges. With all of these paradigms available to developers on our internal agentic platform, the following section explores some of the key components that form the foundation for these advanced capabilities.
Stay Informed with Weekly Updates
Subscribe to our Engineering blog to get regular updates on all the coolest projects our team is working on
Please enter a valid email address.
Thank you for Subscribing!
Taking a high-level look at DoorDash’s agentic AI platform
Advanced agentic architectures are only possible because they are built on a robust and mature platform. These foundational capabilities ensure that every agent, no matter its role, operates with a high degree of accuracy, reliability, and contextual awareness. Figure 5 shows the platform components at a glance.
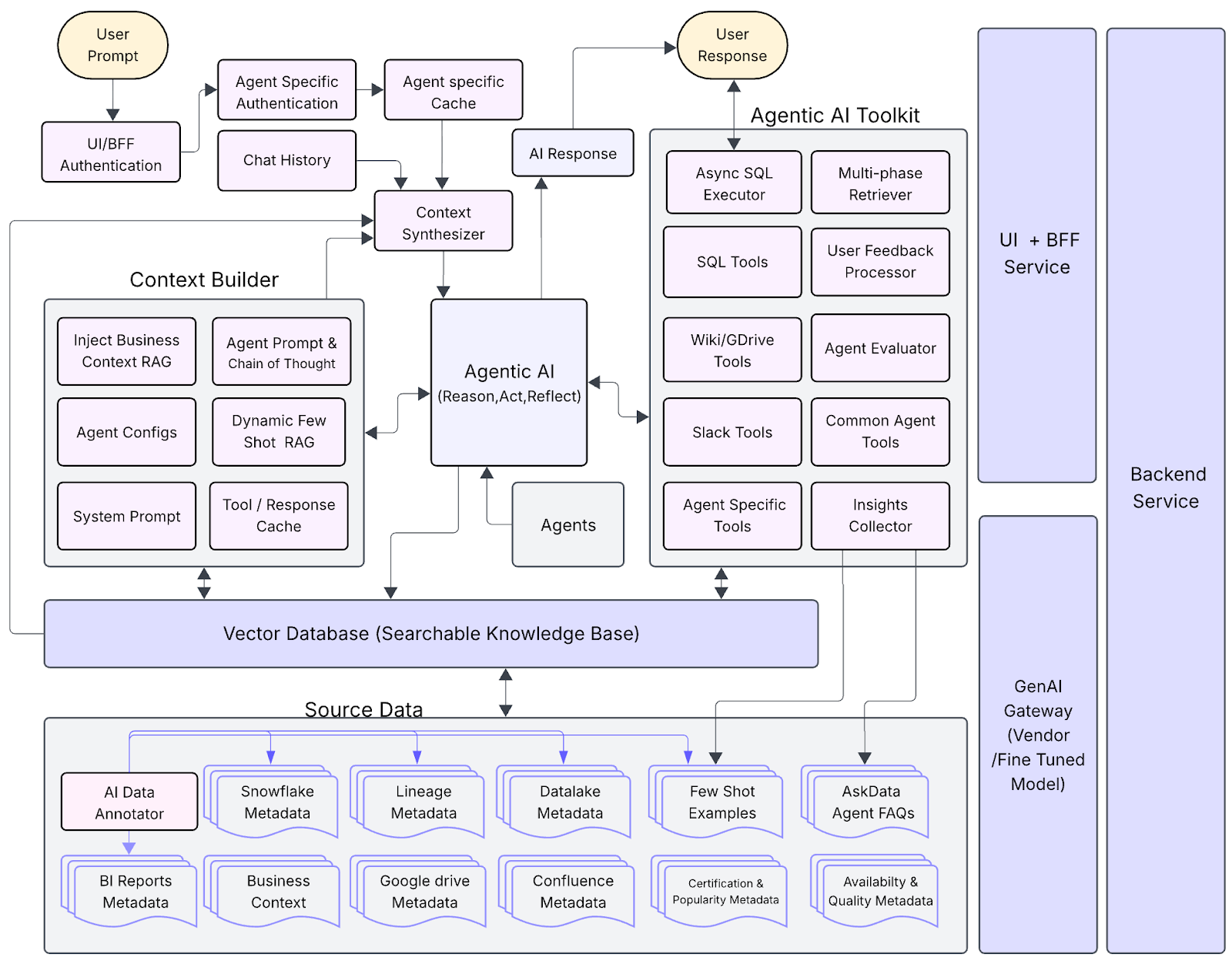
At the heart of our platform's knowledge retrieval is a high-performance multistage search engine built on a vector database. In a business where critical information is spread across wikis, experimentation results, and thousands of dashboards, it can be a major challenge to find the right context quickly. Our engine addresses this by using an algorithm that combines traditional best-match-25 keyword search with dense semantic search, followed by a sophisticated re-ranker using reciprocal rank fusion, or RRF. For DoorDash, this isn't just a technical enhancement; it's a direct enabler of operational agility. This powerful search is the foundation for all our retrieval-augmented generation functionalities, ensuring agents ground their reasoning in fast and accurate contextual information so that an operator can get a trustworthy, evidence-backed answer in seconds, not hours.
This is paired with schema-aware SQL generation. Our secret sauce here is a combination of techniques and tools designed to achieve accuracy. The process starts by identifying the appropriate data sources using an RRF-based hybrid search with custom lemmatization fine-tuned for table names. Once the correct tables are found, we use our DescribeTable AI tool with pre-cached examples. This tool provides the agent with compact, engine-agnostic column definitions. Crucially, it enriches this schema information with example values for each column that are pre-cached in an in-memory store. This significantly improves filtering accuracy for dimensional attributes such as countries, product types, and other categories by giving the agent concrete examples to use in `WHERE` clauses.
Trust is then maintained through a rigorous, multi-stage validation process we call Zero-Data Statistical Query Validation and Autocorrection. This includes automated linting for code style and markdown enforcement, but its core is an `EXPLAIN`-based check for query correctness and performance against engines like Snowflake and Trino. For deeper validation, with the trade-off of slightly increased latency, the system can also check statistical metadata about the query results—such as the number of returned rows or the mean value of a key column—to proactively identify potential issues like empty sets or zero-value results. This validation occurs without exposing any sensitive data to the AI model. If an issue is found, the agent autonomously uses this feedback to correct its query. The system also learns by searching for negative user feedback, allowing the agent to modify its response and improve over time. This capability democratizes data access, enabling a business leader or operations manager to ask complex questions and receive a trustworthy answer without writing a single line of code, all while protecting our data warehouses from costly, inefficient queries.
To maintain a high bar for quality and build trust in our AI systems, we built an automated LLM-as-judge evaluation framework. For a platform intended to guide high-stakes business decisions, "good enough" isn't an option. This framework systematically runs predefined question-and-answer scenarios against our agents. An LLM judge grades each response for accuracy and provides a detailed rationale. We also leverage open-source frameworks such as DeepEval to measure more nuanced metrics, including faithfulness and contextual relevance. The results are automatically compiled into reports, giving us a scalable way to benchmark performance, catch regressions, and accelerate iteration. This continuous, automated oversight is non-negotiable for deploying AI into critical business functions and ensuring reliability over time. Figure 6 summarizes this validation and guardrails flow.

A powerful platform ultimately must be accessible to be impactful. We have focused heavily on a unified user experience and integrations to meet users where they already work. While our conversational web UI provides a central hub for discovering agents and reviewing chat history, the real acceleration comes from our integrations with Slack and Cursor. Business teams collaborate and make decisions in Slack channels, and developers live in their integrated development environment. By allowing them to invoke agents directly within these environments, we eliminate the productivity drain of context switching. An analyst investigating a trend can pull data directly into a Slack conversation, or an engineer can generate boilerplate code without leaving their editor. This seamless integration makes our agentic platform a natural extension of our employees' daily workflows, dramatically accelerating decision-making and execution across the company.
Lessons we’ve learned
We have gleaned some critical insights during our journey from simple workflows to exploring complex agentic systems. First and foremost is the principle of building on a solid foundation. It's tempting to jump to advanced multi-agent designs, but these systems only amplify any inconsistencies in their underlying components. By first creating robust and reliable single-agent primitives — like schema-aware SQL generation and multistage document retrieval — we ensure that the multi-agent systems we develop are trustworthy. This also means using the right tool for the job. We rely on deterministic workflows for certified tasks where reliability is paramount and reserve the more dynamic deep-agent capabilities for exploratory work where the path is uncertain.
Perhaps the most important lesson is that guardrails and provenance are non-negotiable features. Trust is the currency of any AI system, and it is earned through transparency and reliability. We've implemented a multi-layered guardrail system to ensure this. At a foundational level, we have common guardrails that apply across the platform, such as EXPLAIN-based validation for all generated SQL to catch errors and anti-patterns before they run. We also have guardrails for LLM behavior correction, ensuring outputs adhere to company policy and formatting standards. On top of these, we build custom, agent-specific guardrails. For example, an agent interacting with Jira might have rules to prevent it from closing tickets in a specific project. Every action is logged with full provenance, so users can always trace an answer back to its source queries, documents, and agent interactions. This makes the system auditable and speeds up iteration by making it easier to debug.
Finally, we've learned the importance of managing the practicalities of a system that can, in theory, run indefinitely. Memory and context are product choices, not just technical ones. Persisting every intermediate step can bloat context, reduce accuracy, and increase costs. We are deliberate about what state is passed between agents, often sharing only the final artifacts rather than the full conversational history. To keep latency and costs predictable, we budget the loop by enforcing strict step and time limits and implementing circuit breakers. These controls prevent agentic plans from thrashing and ensure the system remains responsive and efficient, which is essential for shipping these capabilities into real production workflows.
Dependencies and open standards
At a high level, our architecture can be visualized as a computational graph. To implement this, we use frameworks like LangGraph to decompose complicated architectures into a series of executable nodes with defined transitions between them. The resulting execution graph resembles a finite state machine, with states representing the steps in a task and transition rules governing how the system moves from one state to the next.
This system is designed to be built upon open standards. MCP standardizes how our agents access tools and data; it’s the bedrock of our single-agent capabilities, ensuring secure and auditable interactions with our internal knowledge bases and operational tools. We are exploring A2A to standardize how agents communicate with each other; it is key to our future vision — unlocking deep agents and swarms at scale.
Moving forward
Our journey is phased, reflecting our evolutionary approach:
- Phase 1: agentic platform foundation and marketplace (launched) — We built the core single-agent primitives and a marketplace to discover and use these agents
- Phase 2: AI network (in preview) — We are rolling out the marketplace and implementing our first deep-agent systems for complex analyses.
- Phase 3: A2A integration and swarm architecture (exploration) — We are exploring A2A protocol support to enable asynchronous tasks and dynamic swarm collaboration.
Acknowledgements
Agentic platform and the AI Network are collective efforts across DoorDash Foundations, Data, Analytics, and Product. Thanks to current and former teammates Karan Sonawane, Lokesh Sharma, Mikhail Shutov, Kushagra Kasliwal, and David Lin
Thanks to our Analytics and S&O: Gunnard Johnson, Avi Scher, Melissa Brown, Paula Castelblanco, Ethan Zhu, Yuanyuan Cui, Mauricio Gonzalez, Steven Staples, Craig Belisle, Diana Ly, Jaime Foley
Engineering and Product Leadership: Vaibhav Jajoo, Matan Amir, Jacopo Himberg, and Pavel Astakhov
Join us
If building interoperable, multi‑agent systems that blend rigorous data work with real‑world operations sounds fun, we’re hiring.
Further reading
- LangGraph multi‑agent concepts — Supervisor, handoffs, hierarchical teams, and patterns for composing agents; useful for thinking about routing vs. collaboration.
- LangGraph multi‑agent how‑tos — Practical guides and examples for building supervisor/swarm graphs and agent handoffs.
- Deep agents (LangChain blog) — Why planning, sub‑agents, and a workspace/file system matter for long‑horizon tasks.
- Deep agents (Docs) — Implementation details: planners, critics, artifact persistence, and state management patterns.
- Context quarantine notebook — Techniques to minimize per‑agent context to improve accuracy by scoping prompts to the active subtask.
- Swarm of AI agents example — A community walkthrough of building agent swarms and role handoffs; good for mental models.
- MCP — Intro and spec for standardizing tool/data access across agents and hosts. GitHub
- Google A2A — Design goals and primitives for agent discovery, messaging, and async task lifecycles.
- Guardrails and trusted AI — Patterns for policy, provenance, and evaluation loops in production systems.





