
DoorDash’s Consumer Packaged Goods (CPG) business spans groceries, retail products, alcohol, electronics, pharmaceuticals, and more. At the International Workshop on Multimodal Generative Search and Recommendation gathering in Korea in 2025, we shared how we built a framework to generate generalizable multimodal representations for CPG products and user queries. Through capturing the rich semantic information contained in product catalogs and user query intent, the embeddings have contributed to a significant performance improvement across ranking and retrieval tasks.
To accommodate DoorDash’s continuing growth, the ads quality team set out to build foundational embeddings that can be reused across multiple use cases, such as retrieval, ranking, and relevance. Traditionally, the team has relied on categorical and numerical features such as store attributes, context features, and other handcrafted aggregates as inputs to our machine learning models. While these are important engagement signals, they fail to capture the rich semantic information contained in our product catalogs and don’t reflect a deeper understanding of users’ personal interests. To bring these enhancements into our models, we developed DashCLIP, short for Dash Contrastive Language-Image Pretraining, a unified multimodal embedding framework designed to power personalized ad experiences for DoorDash users.
DashCLIP overview
DashCLIP’s architecture addresses the following functional requirements:
- Multimodality encodings: Products on our platform contain both text and visual information. We leverage contrastive learning on the product catalog to approximate a human-like understanding of products, capturing the complementary information from each modality.
- Domain adaptation: We perform continual pretraining on off-the-shelf models to adapt the embeddings to DoorDash’s data distribution.
- Query embedding alignment: To enable search recommendations, we introduce a second stage of alignment in our architecture for a dedicated query encoder that is trained to generate query embeddings in the same space as the product embeddings.
- Relevance dataset curation: We curate a high-quality relevance dataset that combines internal human annotations with knowledge from large language models (LLMs), providing
robust supervision for embedding alignment. This eliminates the position and selection bias introduced when historical engagement data is used for training.
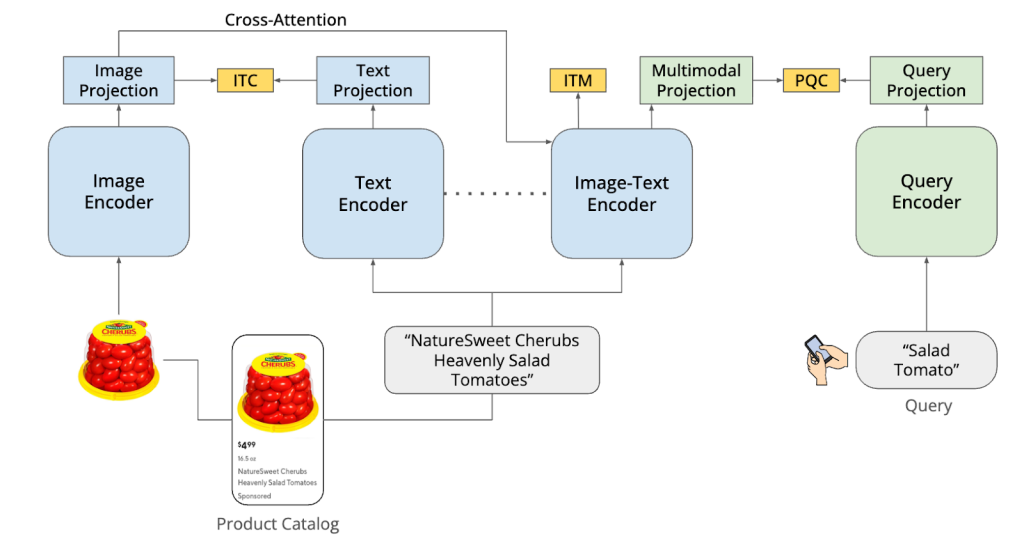
Model architecture
In addition to incorporating the functional requirements described above, DashCLIP also focuses on learning embeddings that can be generalized for use in various DoorDash applications. We show our architecture in Figure 1. DashCLIP includes such components as:
- Image and text unimodal encoders
- An image-grounded text encoder
- A text-only query encoder
Dataset preparation
We curate two main datasets for use in training DashCLIP:
- Catalog dataset: We curated a list of roughly 400,000 products — including their titles, images, and aisle categories — to use their catalog data for continual pre-training and evaluation.
- Query-product relevance dataset: To align the query embedding and product embedding in the same space, we require a relevance dataset that assigns a relevance label — {0: irrelevant, 1: moderately relevant, 2: highly relevant} — to each query/product pair. We started with about 700,000 human labels, which were then used to fine-tune a GPT model and label 32 million pairs to create the final dataset.
Model training
We initialize the image-text product encoders and the query encoder from a pre-trained checkpoint model, BLIP-14M, which is short for bootstrapping language-image pretraining. Following this, we train DashCLIP in two stages:
- In Stage 1, we perform continual pretraining of the product encoders on 400,000 raw product image/title pairs from our catalog. This helps the encoders adapt to the characteristics and patterns of the product domain.
- In Stage 2, we align the query embedding with the product embedding by minimizing a contrastive loss in the projection space of the image-text product encoder and text-only query encoder.
Stage 1 uses the image-text contrastive (ITC) and image-text matching (ITM) losses defined in the BLIP paper. For Stage 2, we design the query-catalog contrastive (QCC) loss, which is defined as:
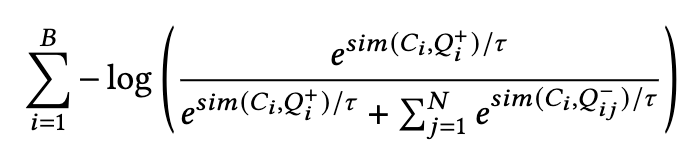
Where 𝐶𝑖 is the multi-modal hidden representation of the 𝑖-th product, 𝑄𝑖+ is the positive (relevant) query for the 𝑖-th product, 𝑄𝑖j- is the 𝑗-th negative query among the 𝑁 negative samples for the 𝑖-th product. We average this loss over the batch size 𝐵. 𝑠𝑖𝑚 is the cosine similarity function, and 𝜏 is the temperature parameter.
Results
We performed extensive offline and online evaluation of DashCLIP across use cases spanning different stages of the ads funnel, as well as general e-commerce applications.
We leveraged the embedding of a user’s query to perform a K-nearest neighbor search in the embedding space of the product to create a ranked list of potential relevant candidates for the next downstream selection, such as ranking. We compared DashCLIP multimodal embeddings to various popular architectures such as CLIP, BLIP, and FLAVA (foundational language and vision alignment). As shown in Table 1, DashCLIP outperformed all baselines by significant gains, demonstrating the effectiveness of product-query alignment in our proposed framework. Off-the-shelf models lack the specificity of the e-commerce domain and frequently fail when used on short but specific queries.
Offline ranking results
DoorDash models the ranking problem as a binary classification task in which the model predicts the probability of the user clicking a given candidate ad. As shown in Figure 2, for the ranking model, we integrated the projected product, query, and user purchase history-derived feature embeddings using the following architecture:
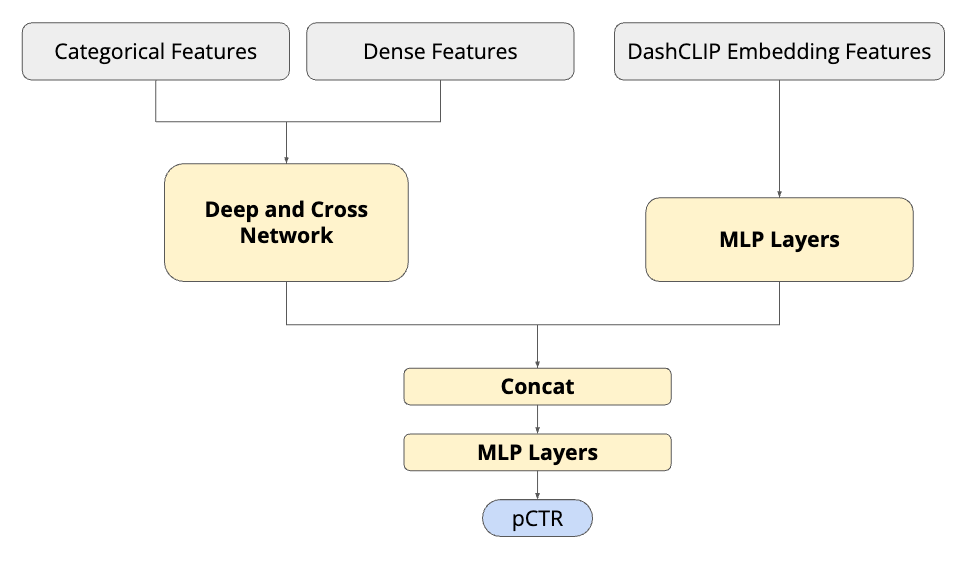
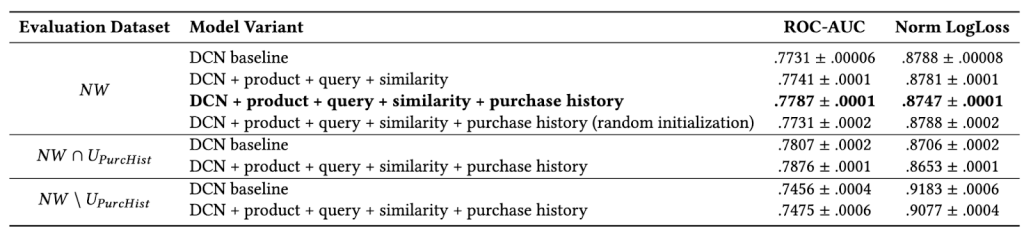
This architecture promotes the crossing between the different embeddings before interacting them with the existing features. As shown in Table 2, our model’s embedding features outperform the baseline deep cross net (DCN) model in terms of the offline area-under-the-curve/receiver-operating-characteristic metric. Users with a purchase history — (𝑁𝑊 ∩ 𝑈𝑃𝑢𝑟𝑐𝐻𝑖𝑠𝑡 ) — benefit more from our embeddings than do users with no purchase history, which demonstrates the effectiveness of DashCLIP embeddings in capturing user interests.
Online deployment
Following the successful offline experiments, we set up an online A/B experiment to evaluate our best candidate against online traffic for about 10 days. The results are shown in Table 3:

Besides significantly improving top-line metrics, our analysis showed that the new model increased engagement rates for most of the top queries and categories, driving more revenue for sponsored products ads and improving the relevance measure. As a result, the model was deployed to serve 100% of traffic.
Applications beyond ranking
As part of our effort to build generalizable embeddings, we wanted to test DashCLIP’s effectiveness in other e-commerce areas. For this, we picked the following two tasks:
- Aisle category prediction: We wanted to test if the embeddings could capture the aisle category, an internal label signifying the type of product.
- Product-query relevance prediction: We wanted to test whether the embeddings could capture the product-query relevance.
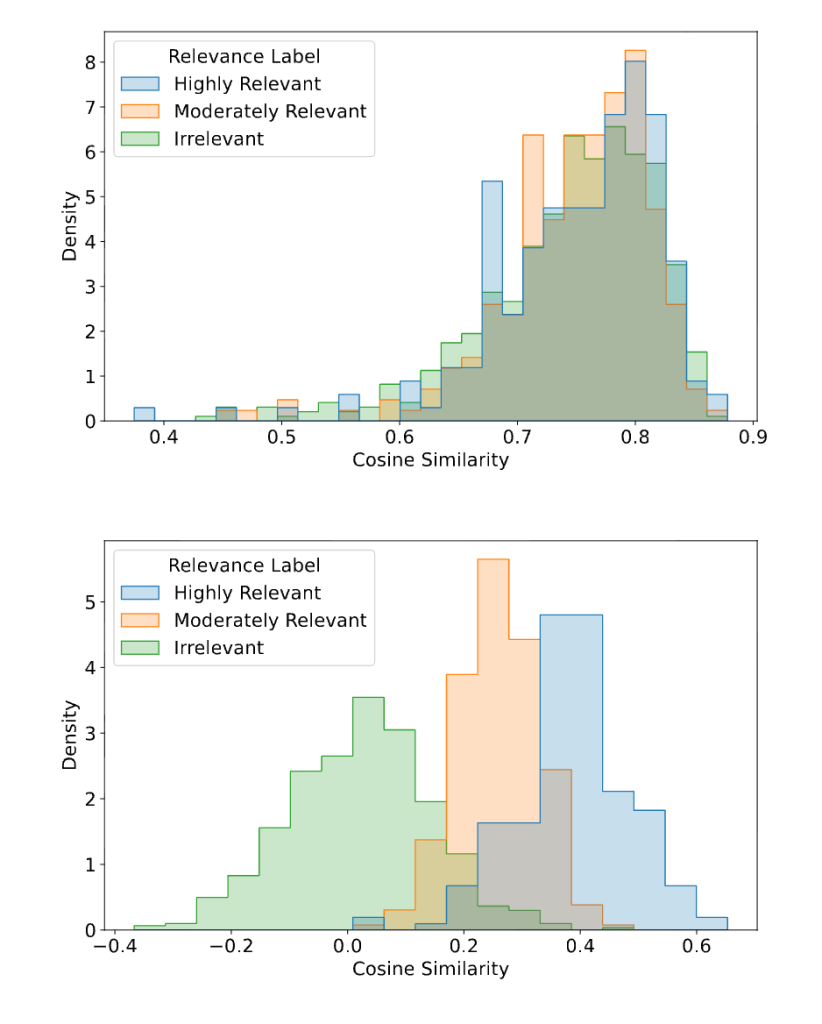
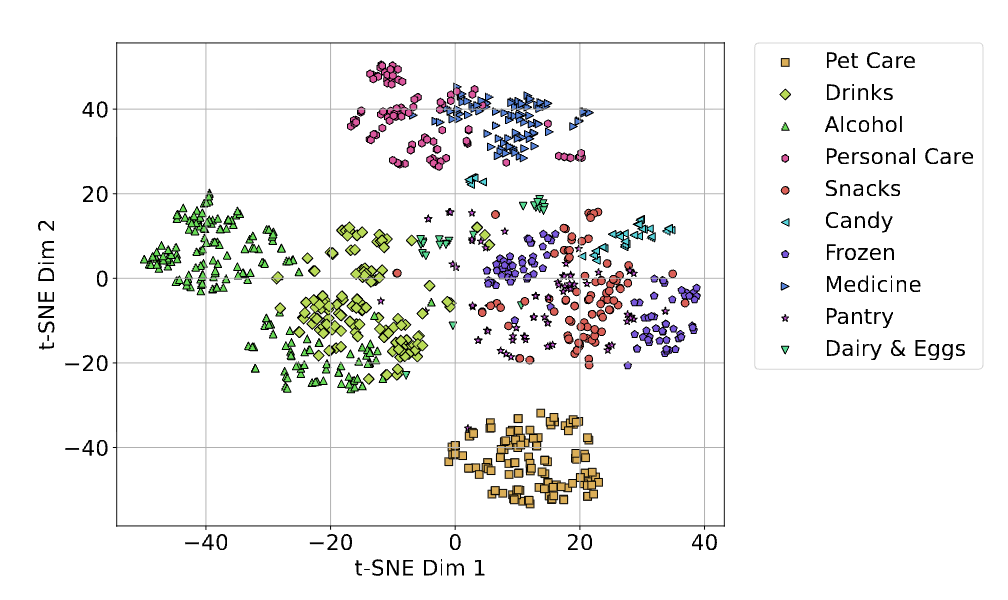
We performed qualitative and quantitative evaluations for both tasks. For quantitative evaluation, we trained simple classifiers using the product embeddings for aisle category prediction, and both product and query embeddings for relevance prediction as inputs. For qualitative evaluation, we plotted the embeddings after t-distributed stochastic neighbor embedding (t-SNE) dimensionality reduction and annotated the aisle category of each product. For the second task, we plotted the distribution of cosine similarity scores between product and query embeddings.
The classifiers trained using DashCLIP embeddings performed significantly better than the baseline BLIP-14M embeddings, as shown in Figures 3, and 4 below.
Future work and takeaways
We plan to extend the ideas behind DashCLIP into our restaurant business to build store and dish embeddings. Moreover, we plan to extend these ideas to learn semantic user representations to encode long-term user behaviors and interests. Ultimately, we plan to transition toward semantic ID representations to enable better generalization.
Overall, we concluded that off-the-shelf models don’t deliver optimal performance. Entity representations should instead be built by pre-training on semantic data before any application-specific optimization. We also discovered that when large-scale human-annotated data is not available, LLMs can provide a dependable alternative to generate high-quality labels.
Join Us
We’re building the next generation of foundational models to power DoorDash ad recommendations. If you’re excited about applied machine learning, large-scale systems, and shaping the future of advertisements, we’d love to hear from you. Check out our open roles!




