

DoorDash handles a large volume of user-generated content every day, including millions of messages and hundreds of thousands of images. While the majority of this content is respectful and positive, a small portion may include inappropriate communications.
In an era where artificial intelligence — AI — is often perceived as a buzzword, DoorDash is applying AI in a principled, high-impact way to help keep our platform respectful and safe. This post highlights how SafeChat, a set of functionalities built in-house and backed by AI, addresses real-world issues at scale. SafeChat's purpose is to screen chat communications between Dashers and customers for offensive or inappropriate content. This gives Dashers the option to report an issue or unassign the delivery, enabling immediate action when needed. With SafeChat, DoorDash is using AI not merely for automation or optimization, but to solve critical challenges affecting both operational integrity as well as consumer and Dasher safety.
Scale of moderation
DoorDash currently processes and moderates millions of chat messages each day. It also processes hundreds of thousands of images and calls daily. We take action whenever any of these are flagged as unsafe. By proactively moderating interactions, SafeChat allows DoorDash to act quickly when intervention is needed.
SafeChat consists of two main pieces: Content moderation and actions. Content moderation is performed for every piece of content exchanged between parties in the system. Its architecture differs depending on the content type — text, image, or voice. The actions generally are the same across content types, but there may occasionally be different rules based on the victim’s role or the delivery stage. It’s helpful to dig first into the distinct architectures for content moderation and how they evolved.
Text moderation architecture
Text moderation ensures that every message exchanged on the platform is checked before delivery. Our systems analyze each message to identify and block or censor unsafe content.
Phase 1
Our first implementation used a three-layered approach, leveraging three different AI models. The first layer focused on moderation and was free of charge. The second was a fast, low-cost LLM. The third was a more precise, higher-cost LLM.
- Layer 1: Moderation API — The moderation API served as the first filter. It provided a low-cost, high-recall, low-precision, and low-latency screen. The threshold was set extremely low, allowing us to automatically clear about 90% of all chat messages. Because this API was free, it helped us keep overall moderation costs low.
- Layer 2: Fast LLM — Messages not cleared by the first layer were moved to a fast LLM model. This layer had higher precision and latency than the moderation API and incurred a cost. We avoided using it as the first filter to prevent unnecessary expense. At this stage, around 99.8% of messages were identified as safe, leaving only 0.2% for the third layer.
- Layer 3: Precise LLM — The final layer used our most precise model. It was also the slowest and most expensive. By this point, we were confident that the message being evaluated had the potential to be unsafe. The model scored each message from 0 to 5 across three categories: profanity, threats, and sexual content. These scores allowed us to build additional safety features. For example, if a consumer sent an abusive message that scored 4 or higher in at least two categories, we gave the Dasher the option to cancel the order.
Phase 2
We ran the three-layered approach for several months and accumulated around 10 million data points. We used these data points to train an internal model that is cheaper and faster. This allowed us to move to a more efficient two-layered approach.
- Layer 1: Internal model — The newly developed internal model became the first layer. For each incoming message, it produces two values: safeScore and unsafeScore. These always sum to 1. If the safeScore is high, the message is automatically cleared. If the unsafeScore is high, the message is considered suspicious, requiring further evaluation. This layer handles the vast majority of traffic quickly and at no extra cost.
- Layer 2: Precise LLM — Only a small percentage of messages flagged by the internal model move to the precise LLM. Because this layer is resource-intensive, we reserve it for ambiguous or high-risk cases. The precise LLM scores messages across the three categories and helps us decide whether to block a message or allow a Dasher to cancel.
With this two-layered system, 99.8% of messages are handled by the internal model alone. The system has become more sustainable, scalable, and cost-effective without sacrificing safety.
The low-precision, layer 1 model responds in under 300ms for most messages. For the few it flags as unsafe, responses can take up to three seconds. This is acceptable because latency is added only for what ultimately could be unsafe messages.
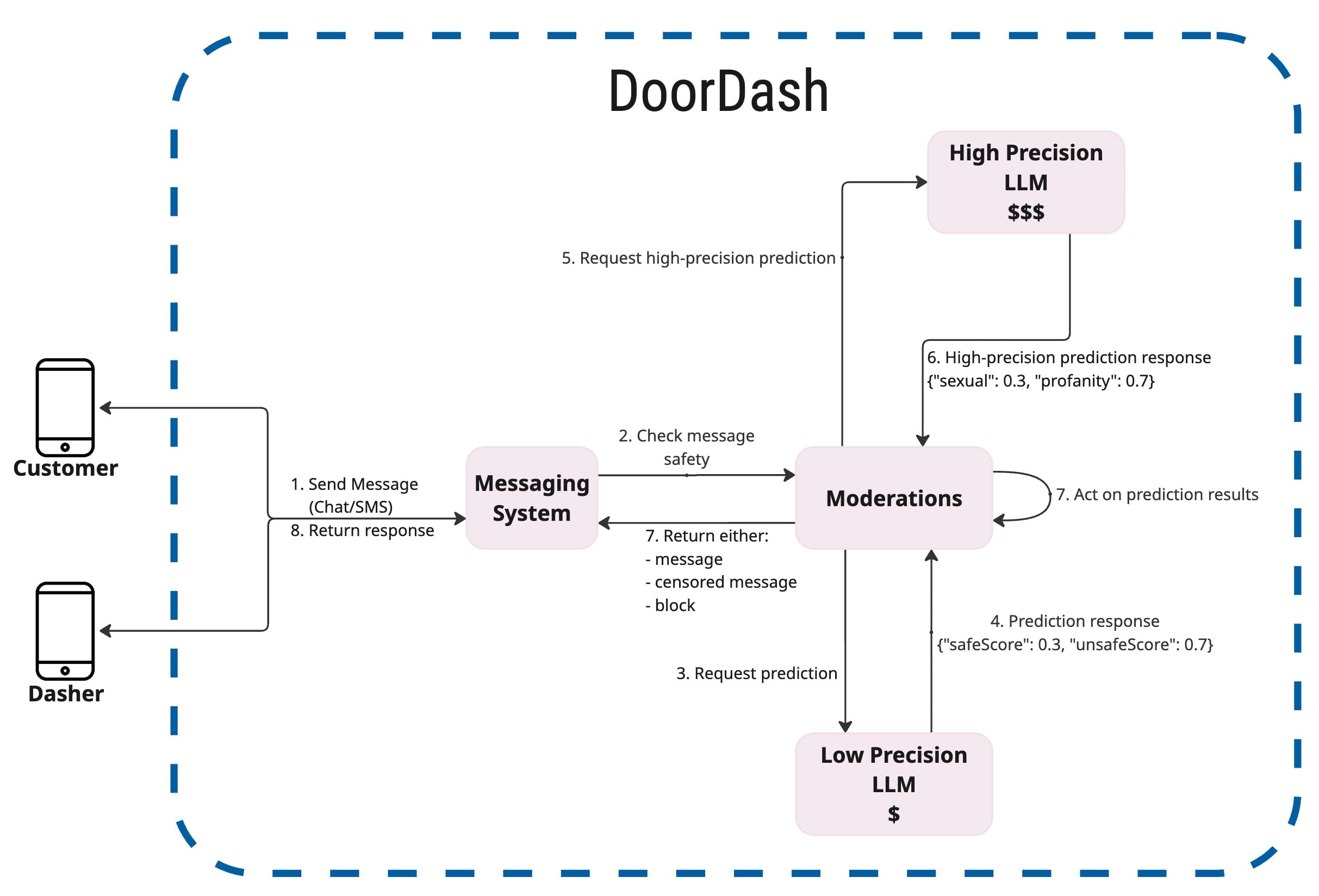
Image moderation architecture
DoorDash also moderates images exchanged within the app. Most images are shared between Dashers and consumers during delivery or when a Dasher provides drop-off proof.
Our first step was a shadow test with an external vision API. For two weeks, we sent every image through the service. We collected results and manually reviewed flagged images and a sample of unflagged ones. The outcome showed a significant false positive rate, making it unsuitable for production.
We then explored other computer vision models with greater granularity. Unlike the initial API, which only returned broad categories, the new model that we selected produced a richer set of subcategories, each with a confidence score. This allowed us to fine-tune thresholds for different content types and apply more nuanced decisions.
Granularity was key. Safety issues in images can be highly diverse. They may include explicit content, violent imagery, or other sensitive material. Treating them all as a single “unsafe” category was not sufficient. We needed a system that could differentiate types of risks so we could respond appropriately.
When we tested the model against a curated dataset that included inappropriate content and previously misclassified images, results improved significantly. Most earlier false positives were corrected, and any remaining flagged cases showed strong indicators of harmful content.
Fine-tuning resulted in real success. After multiple rounds of manual review, we optimized thresholds and categories to balance precision and recall. This reduced both false positives and false negatives.
We also compared cost and latency. The selected model not only offers more accurate results but also faster responses at a lower cost. Each moderation adds about 500ms of latency, which is an acceptable trade-off for safety.
Stay Informed with Weekly Updates
Subscribe to our Engineering blog to get regular updates on all the coolest projects our team is working on
Please enter a valid email address.
Thank you for Subscribing!
Voice detection
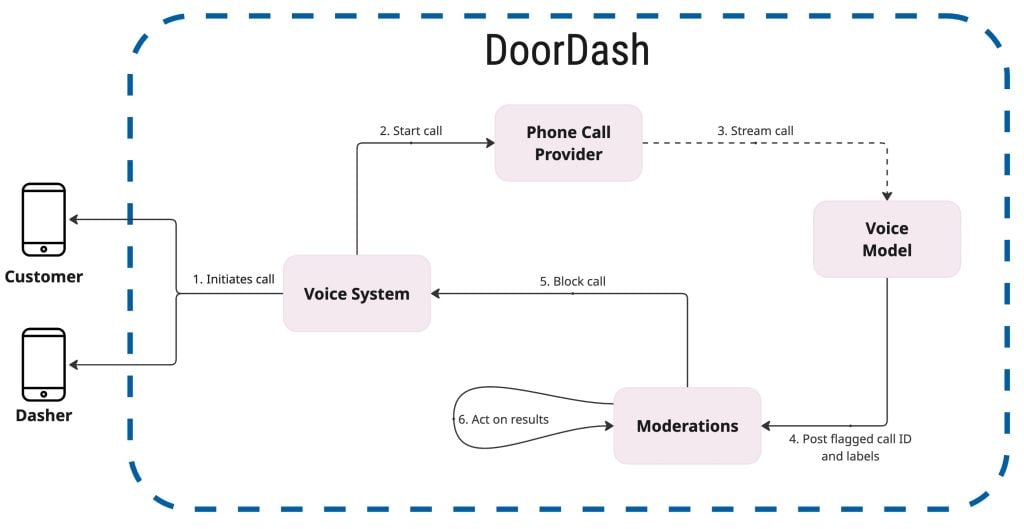
The most recent addition to SafeChat functionality is voice moderation. Voice presents unique challenges compared to text or images. We cannot always prevent harmful language from being spoken in real time. However, we can stop it from spreading further and we can mitigate additional damage.
Our system processes calls in real time, analyzing voice tone, spoken words, and conversational context across multiple languages. Each call is streamed into the moderation pipeline, where it is labeled under categories with confidence scores. These labels allow us to assess the nature and severity of any safety concerns.
When introducing voice moderation, we enabled the engine for all calls but did not allow automatic action to be taken. Instead, flagged conversations were manually reviewed, allowing us to refine categories and thresholds until results were reliable. Once accuracy standards were met, we began acting on the outcomes. For example, unsafe calls could be terminated automatically or further contact between the parties restricted.
This phased approach began with passive monitoring. It was then refined with a human-in-the-loop review, eventually moving into automated action. These steps gave us confidence to scale responsibly while ensuring safety.
Moderation actions
When unsafe content is detected, the system decides how to act. The response depends on the severity of the offense and the risk involved. Our goal is simple: Prevent escalation and stop further harm.
We take four types of actions:
- Block or censor communication: Harmful content in synchronous channels, such as chat and images, can be blocked before reaching the recipient. This prevents offensive or threatening material from being delivered.
- Cancel or reassign deliveries: When an interaction itself poses a risk, the system can cancel or reassign the delivery. In many cases, we give the Dasher or consumer the option to cancel or reassign without cost or penalty. This ensures safety without adding burden.
- Restrict or terminate communication: In asynchronous channels, such as phone calls, the system can drop the call in progress and prevent further contact between the same parties. This is critical when escalation could put someone at risk.
- Escalate to human review and enforcement: Severe or repeated offenses are reviewed by human safety agents. Based on severity, recurrence, and context, actions may include temporary suspension or permanent removal from the platform.
By layering responses, we can act proportionally. The system can censor a single message or block repeat offenders. This ensures interventions are fast and effective. Above all, the goal is to stop unsafe situations from escalating and to protect Dashers and consumers in real-time.
SafeChat’s impact
SafeChat is more than a safety feature. It demonstrates how a thoughtful AI system design can deliver real-world impact. By adopting a hybrid architecture, we combined the strengths of multiple models, both internal and external. This ensured that each message was evaluated at the right cost, with the right level of attention, and minimal impact on user experience.
This flexibility allowed us to scale moderation intelligently. Low-risk content is handled quickly, while high-precision resources are reserved for edge cases. The result is a system that protects users in real time and does so sustainably across millions of daily interactions.
Most importantly, SafeChat has reduced safety-related incidents. Since launch, we have seen a 50% decrease in low/medium-severity occurrences. This is more than just a safety metric. Fewer incidents translate directly into higher Dasher and consumer trust, reduced customer support volume, and stronger platform reliability. In other words, principled AI decisions not only protect people but also improve operational efficiency and long-term retention.
From lowering incident rates to reinforcing user trust, the technical choices behind SafeChat have translated directly into business impact. At DoorDash, we believe AI should do more than optimize; it should protect.
