

At DoorDash, users commonly conduct searches using precise queries that compound multiple requirements. As a result, our search system has to be flexible enough to generalize well to novel queries while also allowing us to enforce specific rules to ensure search result quality.
For instance, a query such as “vegan chicken sandwich,” for which a retrieval system that relies on document similarity — such as an embedding-based system — could retrieve documents (i.e., items) such as:
- Vegan sandwiches
- Vegetarian sandwiches
- Chicken sandwiches
- Vegan chicken sandwiches
For these keywords only the last set on that list matches the user intent exactly. But preferences may vary for different attributes. For instance, a consumer might be open to considering any vegan sandwich as an alternative but would reject a chicken sandwich that is not vegan; dietary restrictions often take precedence over other attributes, like protein choices. Several approaches could be used to show users only the most relevant results. At DoorDash, we believe a flexible hybrid system is most likely to meet our needs; a keyword-based retrieval system, combined with robust document and keyword understanding, can effectively enforce such rules as ensuring that only vegan items are retrieved. Here, we will detail how we have used large language models, or LLMs, to improve our retrieval system and give consumers more accurate search results.
Anatomy of a search engine
Typical search engines contain different stages, which can be separated into two main journeys: one for documents and another for queries. At DoorDash, documents refer to items or stores/restaurants, while queries are the search terms users enter into the search bar.
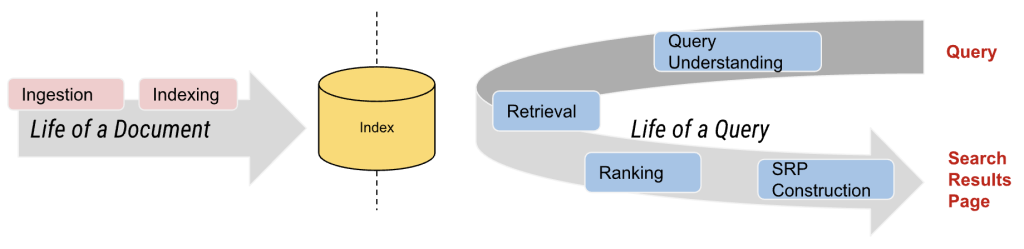
As shown in Figure 1, the first step in a query's journey is to understand it. The query understanding module typically includes steps such as parsing and segmenting the query, annotating it with helpful information, linking it to specific concepts, and/or correcting spelling errors, among other stages. In our case, it also includes more specific steps, such as predicting the vertical intent of the query, whether the search is for a retailer/grocery item or a restaurant/food item.
Similarly, on the document side, we have essential stages where we annotate and process documents with helpful information — metadata — before these are ingested into the search index and made available for retrieval. This information is leveraged not only for search use cases but also for other product surfaces, such as filters and analytical tools.
Document and query understanding
At DoorDash, document processing relies in part on the knowledge graphs we have built for both food items and retail product items. These graphs allow us to define relationships between different entities, providing a better understanding of our documents.
This means that stores and items contain rich metadata — tags and attributes — that help us understand our catalogs better. For example, for a retail item such as “Non-Dairy Milk & Cookies Vanilla Frozen Dessert - 8 oz,” we can have metadata that describes valuable information, including:
- Dietary Preference: "Dairy-free"
- Flavor: "Vanilla"
- Product category: "Ice cream"
- Quantity: “8 oz”
We’ve previously written about how we’ve built DoorDash’s product knowledge graphs with LLMs; you can read more about that process here.
Queries can be segmented and then linked to the concepts available in our knowledge graphs. For example, a query like “small no-milk vanilla ice cream," can be segmented to create chunks such as these:
[“small”, “no-milk”, “vanilla ice cream”]We can then link each segment to attributes that are part of the metadata of the previous product. We might, however, find it difficult to link some of these segments to the precise attributes depending on the granularity of the segments; for “vanilla ice cream” we need to link to two different fields: the dish type “ice cream” and the flavor attribute “vanilla.” Our solution should be context aware to allow appropriate segmentation and entity linking.
LLMs for query understanding
Query segmentation
Traditionally, query segmentation relies on methods such as pointwise mutual information (PMI) or n-gram analysis to determine which words in a query are likely to form meaningful word segments. These methods can be effective if the queries are relatively simple. They begin to fall short when dealing with complex queries that include multiple overlapping entities or when the queries have a high degree of ambiguity.
For instance, in the query “turkey sandwich with cranberry sauce,” – is “cranberry sauce” a separate item or is it an attribute of the “sandwich”? Lacking context, traditional methods might struggle to capture relationships between these word segments.
However, given the correct information, most modern LLMs can understand complex queries and provide accurate segmentations that consider word relationships within different contexts.
One problem with LLMs, however, is that they are prone to hallucinations. We needed to develop a controlled vocabulary to create meaningful segmentations that are both factual and valuable for our retrieval system. Luckily, our knowledge graph work already offered an ontology that gave us access to multiple taxonomies that could guide this process. Instead of breaking down a search query into arbitrary segments, we prompt the model to identify meaningful segments and categorize them under our taxonomies. Even though the hallucination rate on the segmentation process is low — less than one percent — we also benefit from the immediate classification of the output in a valuable category for our retrieval system.
We have taxonomies for restaurant items that define hierarchical relationships for cuisines, dish types, meal types, and dietary preferences, among many others. Similarly, we have taxonomies for retail items that include brands, dietary preferences, and product categories.
As an example, let’s take another look at the previous query: “small no-milk vanilla ice cream.” Instead of asking the model simply to find meaningful word segments such as:
[“small”, “no-milk”, “vanilla ice cream”]we prompt it to provide a structured output mapping each meaningful word segment to one of our taxonomy categories:
{
Quantity: "small",
Dietary_Preference: "no-milk",
Flavor: "vanilla",
Product_Category: "ice cream"
}Our evaluations have shown that this approach results in more accurate segmentations, likely because the structured categories provide the model with additional context about possible relationships.
Entity linking
Once a query has been segmented, we want to map these segments to concepts available in our knowledge graph. Because the knowledge graph has been ingested into the search index as part of our document understanding work, we can make many rich attributes available for retrieval. A segment like “no-milk” should be linked to our “dairy-free” concept to ensure that we retrieve a candidate set that contains this attribute without restricting it to exact string matching in the item name or description, which can hurt recall.
LLMs have proved very useful for this task as well. However, as we mentioned in the query segmentation section, they can sometimes generate outputs that are factually incorrect or hallucinated. In the context of entity linking, this could mean mapping a query segment to a concept that doesn't exist in our knowledge graph or mislabeling it entirely. To mitigate this, we employ techniques that constrain the model's output to include only concepts within our controlled vocabulary – in other words, our taxonomy concepts.
We reduce these types of errors by providing the LLM with a curated list of candidate labels retrieved via approximate nearest neighbor (ANN) techniques. This approach ensures that the model selects from concepts that already are part of our knowledge graph, maintaining consistency and accuracy in the mapping.
Consider the earlier query segment “no-milk,” for which our ANN retrieval system might provide candidate entities like “dairy-free” or “vegan.” The LLM then only needs to select the most appropriate concept based on the context, ensuring that the final mapping is accurate and within our knowledge graph.
To do this, we leverage retrieval-augmented generation, or RAG. The process generally goes as follows:
- For each search query and knowledge graph taxonomy concept (candidate label), we produce embeddings. These can be from closed-source models, pre-trained, or learned in-house.
- Then, using an ANN retrieval system, we retrieve the closest 100 taxonomy concepts, or candidate labels, for each search query. We need to do this because of context window limitations and to reduce the noise in the prompt which can degrade performance (for details, see this paper).
- We then prompt the LLM to link queries to corresponding entities from specific taxonomies such as dish types, dietary preferences, cuisines, etc.
This process ultimately generates a set of linked taxonomy concepts for each query that we can use directly to retrieve items from the search index. The overall process is outlined in Figure 2 below.
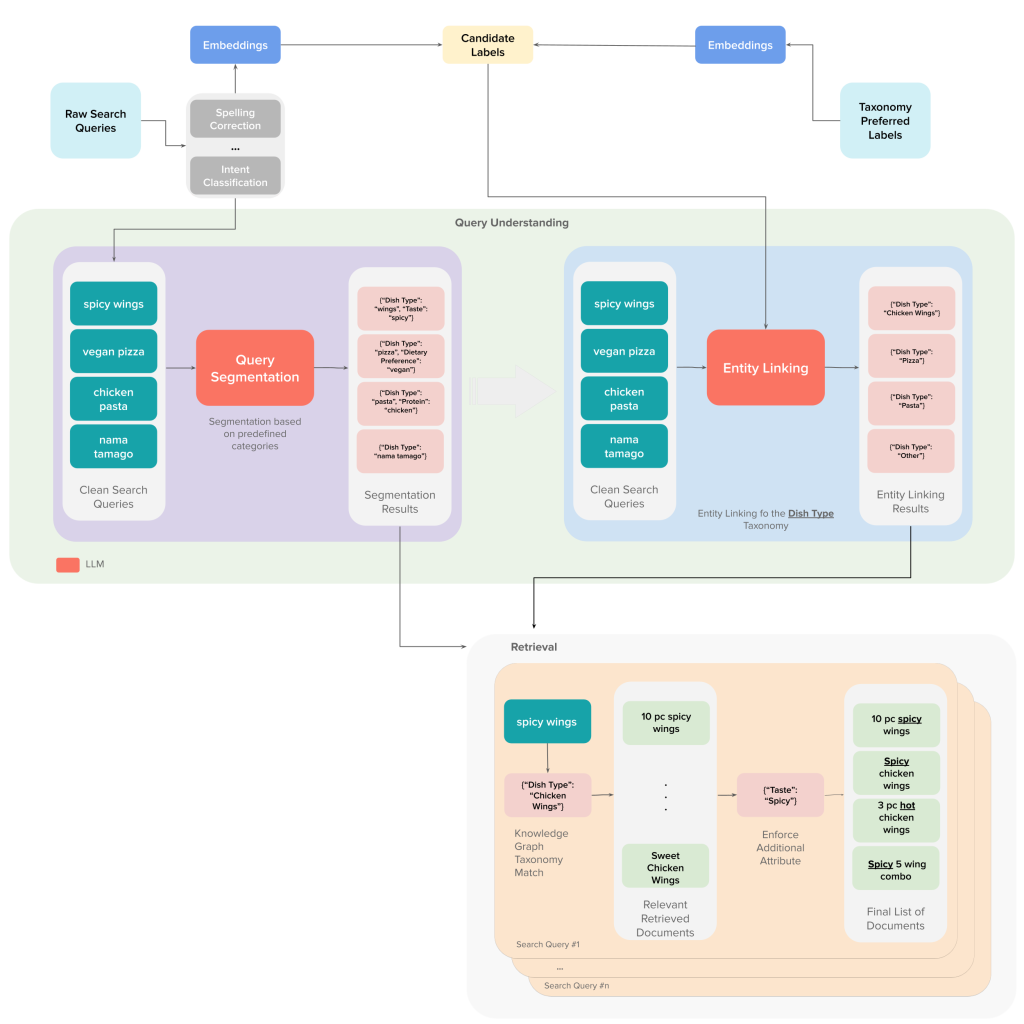
After this process, the final query understanding signal for “small no-milk vanilla ice cream” would match with many of the attributes of the document, or item, in our catalog described as “Non-Dairy Milk & Cookies Vanilla Frozen Dessert - 8oz”:
{
Dietary_Preference: "Dairy-Free",
Flavor: "Vanilla",
Product_Category: "Ice cream"
}This makes it easier to control what to retrieve by implementing a specific retrieval logic, such as making all dietary restrictions a MUST condition and allowing flexibility of less strict attributes such as flavors as a SHOULD condition.
Evaluations
Maintaining high precision in our query understanding pipeline is crucial, especially when dealing with important attributes such as dietary preferences. To ensure this, we developed post-processing steps to prevent potential hallucinations in the final output and ensure the validity of both our segmented queries and their linked entities. After these post-processing steps, we perform manual audits on each batch of processed queries to measure the quality of our system.
Annotators review a statistically significant sample of the output to verify that query segments are correctly identified and accurately linked to the appropriate entities in the knowledge graph. This manual evaluation helps us detect and correct systematic errors, refine prompts and processes, and maintain high precision.
Memorization vs. generalization trade-offs
While our process shows that LLMs provide a good framework for query understanding, it’s important to keep in mind the trade-offs between memorization and generalization. Using LLMs for batch inference on a fixed set of queries can provide highly accurate results. This approach works well when the query space is limited and well-defined, but it becomes challenging as we move further into the long tail of the distribution.
There are serious drawbacks to relying solely on memorization, including:
- Scalability: As new queries emerge, especially in DoorDash’s dynamic environment, it becomes impractical to pre-process every possible query in a timely manner.
- Maintenance: The system requires frequent updates and re-processing to incorporate new queries or changes in the knowledge graph.
- Feature staleness: Some segmentations and links likely become stale over time.
Fortunately, other methods generalize well to unseen queries, such as embedding retrieval, traditional statistical models, and other rule-based systems that can handle new queries on the fly. Such methods provide advantages such as:
- Scalability: The ability to process any query without prior exposure.
- Flexibility: Adaptation to evolving language usage and emerging trends.
- Real-time processing: Immediate handling of queries without batch processing delays.
As we mentioned, however, these methods may lack LLMs' deep contextual understanding, potentially reducing precision. A hybrid approach strikes the right balance between memorization and generalization. By combining the approach we outline here with other methods that generalize well to new query-document pairs – including lightweight heuristics, statistical methods such as BM25, or more complex approaches like embedding retrieval – we can leverage multiple strengths to achieve higher precision while maintaining adaptability.
System View: Integrating the new query understanding signal into the search pipeline
The effectiveness of our query understanding system also depends on how well it integrates with other components of the search pipeline, particularly the rankers. Rankers are responsible for ordering the retrieved documents — items or stores — based on their relevance to the query.
After introducing the new query understanding signals, we needed to make them available to the rankers. As the rankers caught up with the new signals and also the new patterns of consumer engagement that our retrieval improvements introduced, relevance and business metrics rose, as reflected in our online tests (see additional details below).
By aligning the ranker's capabilities with the precision of our query understanding system, we are able to deliver more accurate and relevant search results. This synergy is essential to meet our users’ evolving and complex needs, as demonstrated in the following use case.
Results and a use case
DoorDash’s popular dish carousel, shown in Figure 3, relies on this retrieval pipeline to display relevant results for queries that reflect a specific dish intent.
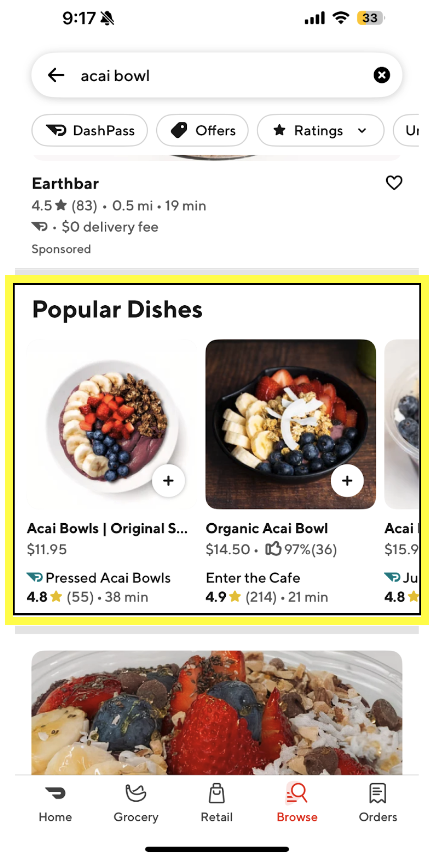
When consumers search for something like “açaí bowl,” the example shown in Figure 3, they signal that they are looking for a particular dish. By providing that specific dish directly in the search results page, they can quickly compare different options across many stores.
We saw a substantial increase in the trigger rate of popular dish carousels upon implementation of our new query understanding and retrieval improvements–we are able to retrieve significantly more items. Specifically, we observed nearly a 30% increase over our baseline, which also means we are aligning search results more closely with consumer intent, making it easier for them to place orders.
This increase in trigger rate should lead to more relevant results for consumers. When we accurately segment queries and link them to our knowledge graph, we can retrieve a broader and more precise set of dish items to populate these carousels. A higher trigger rate coupled with high-quality results means that we increase overall relevance. This is shown by our whole page relevance, or WPR, metric, which is designed to measure from the user’s perspective the overall relevance of search results across different query segments and intents. Our approach led to a more than two percent increase in WPR for dish-intent queries, indicating that users were seeing more relevant dishes in general.
Online testing also showed that increased relevance aligns with an increase in engagement and conversion. We observed a rise in same-day conversions, confirming that reducing friction can help consumers decide which items to order.
Furthermore, with new and more diverse engagement coming in from the improved retrieval systems, we could retrain our ranker with a more comprehensive dataset. The new ranker version further improved relevance — as demonstrated by a 1.6% increase in WPR — making it even easier for consumers to discover and order the dishes they wanted, resulting in higher order volume and increasing marketplace value.
Future directions
Now that we have validated how well LLMs can be integrated into the DoorDash system, we have revealed a vast landscape of possibilities to explore. As we continue to automate processes to increase our query and catalog understanding, we can scale up the number of concepts and attributes identified in our catalogs and better understand the relationships between even more entities. Among the many use cases this can unlock are:
- Helping users rewrite queries and recommending search paths they can explore. Our greater understanding of relationships enables us to suggest alternative or related search paths to guide users to new dishes, stores, and restaurants.
- Showing new users which queries they may want to search because we can identify the most popular items in a given market to a high degree of granularity.
- Improving retrieval recall and precision through better coverage of query and document understanding. More granular attributes allow us to retrieve more items without significantly compromising precision.
- Learning more about consumer behavior and profiles. Deeper query and catalog understanding let us better understand the overlap of attributes between entities and create personalization signals that, for example, infer that a consumer likes spicy dishes and Latin American cuisines.
Conclusion
Through combining LLMs for query understanding with our knowledge graph and a flexible retrieval approach, we now can handle more complex and nuanced user queries while unlocking new experiences in a highly dynamic environment. We are excited to continue experimenting with new and emerging technologies, working with our partners to create delightful experiences for our consumers.
Acknowledgments
Special thanks to Ran He, Paul Kim, Emily Strouse, Luoming Liu, Nishan Subedi, Tian Wang, Qilin Qi, Hanning Zhou, Yu Sun, Ying Li, Fushan Li, and the rest of the Knowledge Graph and Search Quality teams; to our cross-functional partners Christian Lai, Alex Levy, Kunal Moudgil, and Jose Grimaldo, who all worked together to make this exciting work happen. Finally, huge thanks to our team of annotators, who contribute significantly to our ML work.
