

DoorDash’s software engineering internship program immerses interns within our Engineering teams, where they contribute to meaningful projects that power the experiences of Dashers, merchants, consumers, and internal employees. Designed to be both hands-on and impactful, the program offers real opportunities for learning and growth. This post is part of a 4-part series highlighting the innovative work from our Summer 2025 interns - check out Part 1 and Part 2.
Building a Feedback Loop to Recognize Impactful User-Generated Content
By Cassidy Xu
Many DoorDash customers leave thoughtful reviews, but rarely know if they’ve made an impact. This summer, I built a feedback system that notifies users when their content achieves high visibility or recognition to help them feel valued for their contributions while encouraging their continued engagement.
Across the industry, user-generated content, or UGC, drives purchasing decisions, yet contributions are seldom acknowledged. At DoorDash, this has meant missing opportunities to recognize valuable reviews and strengthen community trust.
We started the project with these key questions: What if leaving a review didn’t end in silence? What if we celebrated when a review reached more than 100 views or became the top-ranked review for a restaurant? Our UGC feedback loop alerts customers when their content makes a real impact. Building it required working across platforms, navigating extract-transform-load (ETL) pipelines, and orchestrating personalized notifications at scale.
Architecting the feedback loop: System design
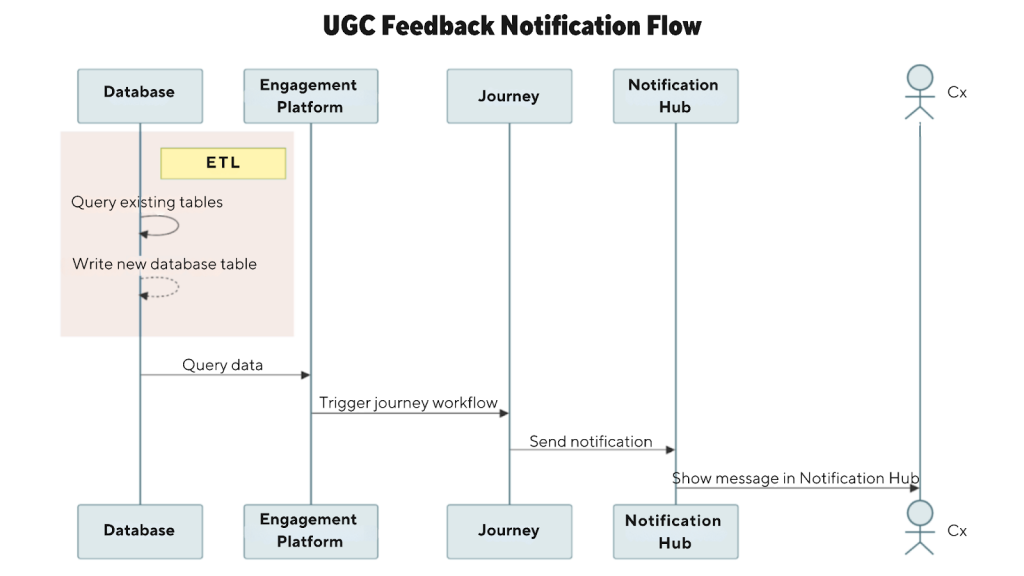
At the core of the system is a pipeline that tracks high-performing reviews and sends timely notifications to their authors. I created two new database tables, each refreshed regularly using scheduled data workflows:
- ugc_weekly_stats: Aggregates views per review over the past seven days.
- top_ugc_for_stores: Identifies the top-ranked review for each store daily.
To ensure efficient querying, I filtered the data to include only reviews from the past 30 days and pre-computed view metrics. This setup allows downstream tools to target users based on well-defined thresholds without exceeding performance limits, as shown in Figure 1.
Designing the notification experience: Templates and triggers
We implemented two notification types to highlight different kinds of impactful content:
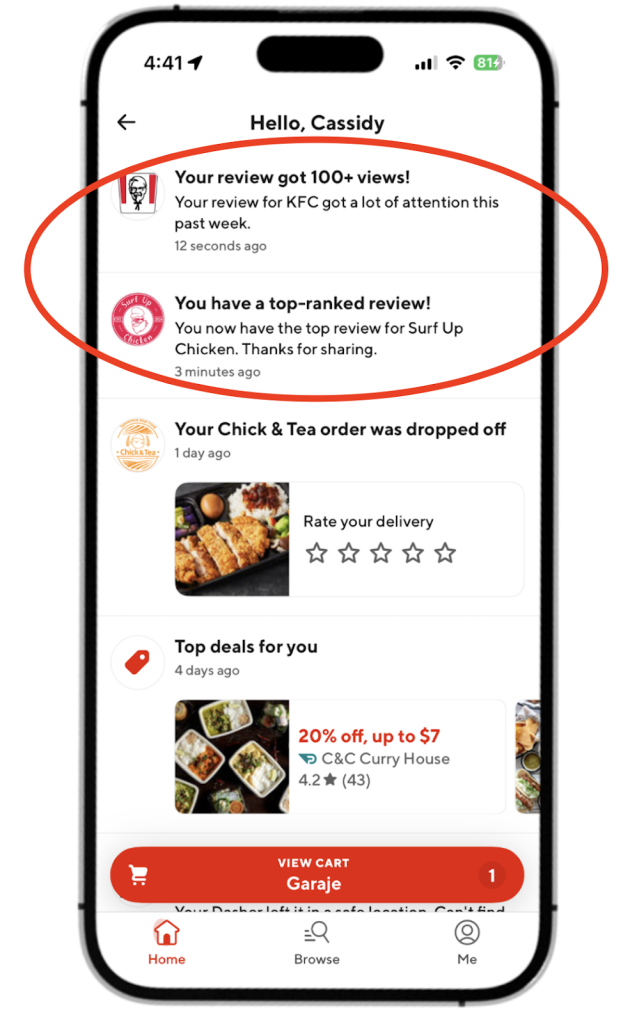
- Milestone view notification: Triggered when a review crosses a view threshold — for example, more than 100 views — to encourage continued contributions through linking to the user’s profile
- Top-ranked review notification: Triggered when a review becomes the most prominent on a store’s page; this celebrates standout content by linking to the store
As shown in Figure 2, notifications are personalized with dynamic fields such as store name and view count to keep the experience relevant and rewarding.
Integrating the engagement platform and journey
Rather than building custom backend logic to trigger push notifications, we used two internal platforms already built for this purpose:
Engagement platform (EP): Defines and filters the audience using our database SQL queries.
Journey: Orchestrates when to send notifications and supports personalization.
Using internal tooling allows us to schedule recurring sends, personalize content with minimal code, and experiment efficiently with new notification formats. It also makes future updates or iterations more accessible to non-engineers.
Preventing notification fatigue
During testing, we discovered that the default deduplication logic in the notification hub only removed duplicates from the user interface. It still sent identical messages to users. This could create a repetitive experience if a user’s review continues to meet the same criteria week after week.
To address this, I added a custom deduplication step directly to the EP queries. By joining with a log of previously sent notifications, I filtered out users who had already received a given message in the previous 30 days. This ensures that each notification feels timely and intentional, rather than redundant.
Conclusion
The UGC feedback loop demonstrates how thoughtful systems design can drive user trust, enhance content quality, and create impactful product experiences. From writing SQL and building ETL pipelines to orchestrating personalized journeys and tracking performance, working on this project exposed me to DoorDash’s full stack and allowed me to design and implement end-to-end engagement features. It’s even more fulfilling to realize that this work will be available to all users for a long time to come.
Because this was the Social Team’s first implementation of EP + Journey for push notifications, I’ve documented the setup so future engineers can easily expand on it in future.
Huge thanks to my mentor, Shinyou Zhang, for her steady guidance and kind encouragement and to my manager, Chun-Wei Lee, for always advocating for my work and providing constant support. I’m also grateful to the entire Social Team for their kindness and collaboration.
Building Customer Trust Through Transparency in Service Slowdowns
By: Scott Figueroa-Weston
At DoorDash, even a few minutes of delay can make or break the customer experience. Until recently, we only notified users during full market outages. We lacked a scalable way to communicate during service slowdowns, when deliveries are still active but slowed by broader market conditions, such as a severe weather event or peak holiday demand.
This summer, I worked on a system that combines streaming data, anomaly detection, and in-app banners to notify customers in real-time when their area is experiencing delivery disruptions. The result: Clearer expectations, fewer customer support tickets, and stronger customer trust.
Speeding communication about slowdowns
When deliveries run late without warning, customers feel confused and frustrated, which erodes their trust in the platform. A poor delivery experience can make customers less likely to order again, impacting long-term retention and brand reputation. At the same time, these delays trigger a surge in support requests, which can overwhelm customer support agents with repetitive inquiries as to why delivery is taking so long. This creates a stressful workload for the support team and makes it harder to provide timely assistance.
Our goal is to create a real-time data pipeline that can detect slowdowns and surface explanatory banners within minutes.
Transforming raw data into real-time alerts
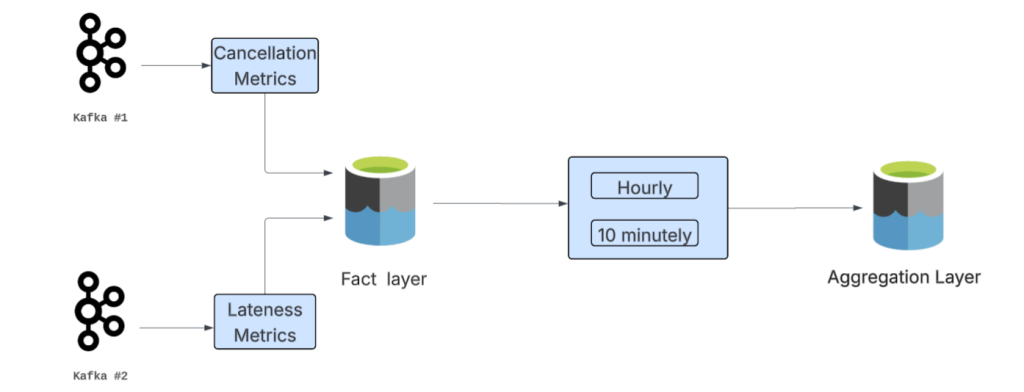
The pipeline consumes delivery event streams from Apache Kafka and processes them with Apache Spark Structured Streaming, persisting into layered Delta tables, including:
- Fact layer: A store of raw delivery events that includes cancellation and lateness, as well as derived fields such as a binary flag with a latency of around 20 seconds for orders that exceed 20 minutes past the promised estimated time of arrival.
- Aggregation layer: Aggregates fact-level delivery metrics into 10-minute and hourly windows, quantifying cancellations and late orders with a latency of around five minutes. As shown in Figure 1, outputs are calculated across multiple dimensions, such as store and region, and serve as the foundation for anomaly detection. Because aggregated metrics are expensive to compute, this layer plays a crucial role in reducing costs while ensuring consistency across all aggregated outputs.
Detecting true slowdowns
Not every late order means degraded service. A few delays can happen for normal reasons, so we need a way to distinguish random noise from true market-wide issues. To do this, we apply anomaly detection at the neighborhood level within specific geographic regions.
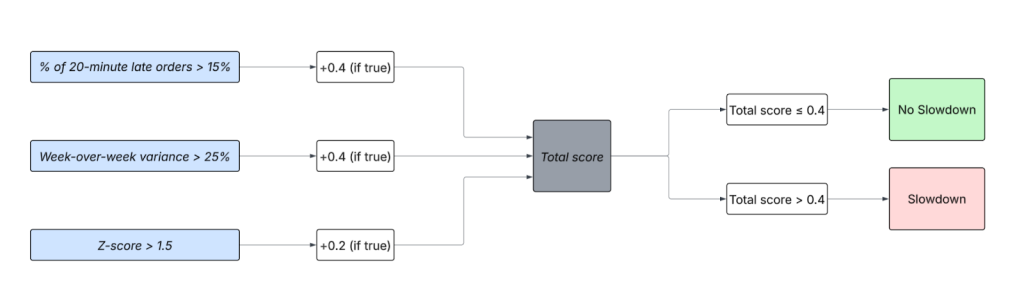
The system evaluates three signals:
- % of 20-minute late orders > 15% flags when too many deliveries are significantly late, a clear sign customers will notice disruptions.
- Week-over-week variance > 25% catches neighborhoods that suddenly perform worse than their own baseline.
- Z-score > 1.5 identifies unusual spikes outside normal fluctuation.
As shown in Figure 2, each condition contributes a weight to the total slowdown score. Only when the score passes a defined threshold do we flag the neighborhood as experiencing a slowdown. Stakeholders can adjust these weights and thresholds to fit their needs
Closing the loop with customers
Flagged neighborhoods are pushed to an existing promotion service, which triggers in-app banners for customers in affected areas, as shown in Figure 3.

The same data powers dashboards for Operations teams, helping them investigate root causes for these slowdowns.
Impact
Because of this project, customers are no longer left in the dark during slowdowns. The system improves transparency and trust by proactively notifying customers when delays are occurring in their area, helping set realistic expectations and preventing frustration. It reduces customer support volume by addressing the most common question — “why is my order late?” — before customers need to reach out. This frees up agents to focus on more complex issues. The system also provides Operations with better visibility into regional disruptions by surfacing real-time data through dashboards, enabling teams to quickly diagnose problems, allocate resources, and resolve issues at scale.
We anticipate scaling our ability to communicate proactively through expanding this foundation to other metrics such as “never delivered,” “missing items,” “incorrect items,” and “poor food quality.”
How End-to-End Testing Enhances Reliability at DoorDash
By Saloni Bedi
DoorDash’s subscription service, DashPass, offers users waived delivery fees, reduced service fees, and other exclusive promotions to make DoorDash more affordable. My work this summer focused on creating a reliable experience using DashPass, starting with signups.
Presenting the upsell
The DashPass Signups team, with whom I worked, functions within the larger DashPass engineering organization to support surfaces that drive signups. One such surface is an upsell, which lets users know about the savings they can reap if they sign up for DashPass. Consumers may see a variety of different upsells based on their attributes, such as duration on DoorDash, participation in a campaign, and free trial eligibility. The DashPass Growth Service is a set of evaluators that decide which upsell to show a user. The end result of that process is shown in Figure 1.
Getting in the flow
A consumer's time on the platform can be boiled down to one or more user flows — a set of consecutive consumer actions. For DashPass signups, this flow might occur in the following way: Consumer logs in → clicks on a restaurant → adds an item to the cart → navigates to the order cart page → continues to the checkout page → clicks on the upsell checkbox → sees the DashPass subscribe button and → subscribes to DashPass.
End-to-end, or E2E, tests automate these user flows to assess quality assurance and reliability. The testing platform we use — Maestro — uses a single test to click through several user actions and ensure that everything is working as intended.
A bug in the critical flow — say, if a consumer couldn’t click on “subscribe” from an upsell — damages user trust, reduces the number of DashPass signups, and wastes hours of engineering time examining what went wrong. E2E tests prevent these consequences by catching bugs before consumers encounter them.
Establishing preconditions
End-to-end tests can have preconditions, which are requirements of the test user/system state before the test can be executed. Our team couldn’t create upsell-specific E2E tests because we had no automated or on-demand method to set up preconditions.
To solve this problem, we turned to Kaizen and dynamic variables.
Kaizen flows to the rescue
A Kaizen flow is a set of steps that call one or more endpoints in a specific order to recreate an existing flow. Although similar to an E2E test, it serves a different purpose.
Let’s say we want to create an E2E test to verify that the “resume” upsell is working properly. Users only see this upsell if they (1) subscribe to a DashPass plan, (2) pause their subscription, and (3) no longer have DashPass benefits — in other words, their current billing cycle has ended. We can create a Kaizen action to accomplish each necessary step; the output of each action is input to the following one to create a Kaizen flow. This addresses the first set of tests requiring automation to set up preconditions.
However, a Kaizen flow cannot accommodate any modification to a test user’s state to align with preconditions. For example, we may want to run an E2E test on the functionality of a multi-plan upsell — one in which a consumer sees multiple subscription options, rather than just one. Such an upsell is only shown to consumers if they have a specific user attribute x added to their account. To test this upsell, the user created by our E2E test must have our precondition attribute x. But we have no clear way to add attribute x to a specific consumer, rendering our Kaizen setup moot.
Dynamic variables step in
A dynamic variable, or DV, stores a value based on certain contextual input variables, such as consumer or submarket ID. Values can be of various types, such as Boolean or integer, or may even be an object. At DoorDash, we often wrap code changes with a DV.
Let’s say that we only want a small number of test users — with IDs 123, 198, and 147 — to be affected by our new code. The DoorDash developer console allows us to set up DVs and their corresponding rules so that if a consumer’s ID is in the list {123, 198, 147}, our DV will have the value true. Otherwise, it will have the value false. Then, in our code, we can write:
if (testing_dv == true): do new code
else: do old code
We can use this tool to override code that makes a consumer see a specific type of upsell. If we want a test user to see a multi-plan upsell, we can find the logic that shows this to a user only when a user has the specific attribute x, and modify it like so:
if (multi_plan_dv == true): do new code (show multi-plan upsell)
else: do old code (check for attribute x before showing multi-plan upsell)
DVs allowed us to override logic within our codebase to force a test user to see something specific, addressing our second set of tests with more intricate preconditions.
Impact
This work with DVs and Kaizen flows allowed us to unlock 16 E2E tests for the DashPass Signups team. The tests were high priority because they simulated golden flows — critical user flows that a large percentage of consumers see; for example, the tests covered variations of signing up for DashPass from an order cart upsell, which is the source of roughly one-third of signups. Running these tests regularly gives us confidence in the experience’s reliability by reducing the risk that a preventable bug could impact hundreds of thousands of consumers. In turn, the effort contributes to DoorDash’s mission of empowering local economies by helping more consumers reliably access DashPass benefits, driving engagement with merchants, and fostering trust in the platform.
Improving Efficiency with Budget Signals for Sponsored Brand Ads
By Jack Myles
Digital advertising leaves little margin for waste. Every additional millisecond adds hidden costs, from infrastructure spend to lost revenue. When a merchant chooses to display a sponsored brand, or SB, ad on DoorDash, the pipeline must quickly retrieve all eligible campaigns and choose which to show. A campaign may be ineligible for any number of reasons, but here we will focus on the daily budget set by the brand. Until recently, the system fetched all eligible active campaigns that matched a query — even those with an exhausted daily budget — only to discard them milliseconds later.
My summer intern project was to eliminate this redundancy. By embedding a real-time budget-capped flag directly into DoorDash’s in-house search index, we were able to prevent out-of-budget ads from ever reaching the filtering stage. This resulted in a 43% drop in search processor latency and a 45% reduction in discarded candidates. These efficiency gains not only improve today’s sponsored brand performance but will multiply as the SB business continues to scale.
Why budget-capping matters
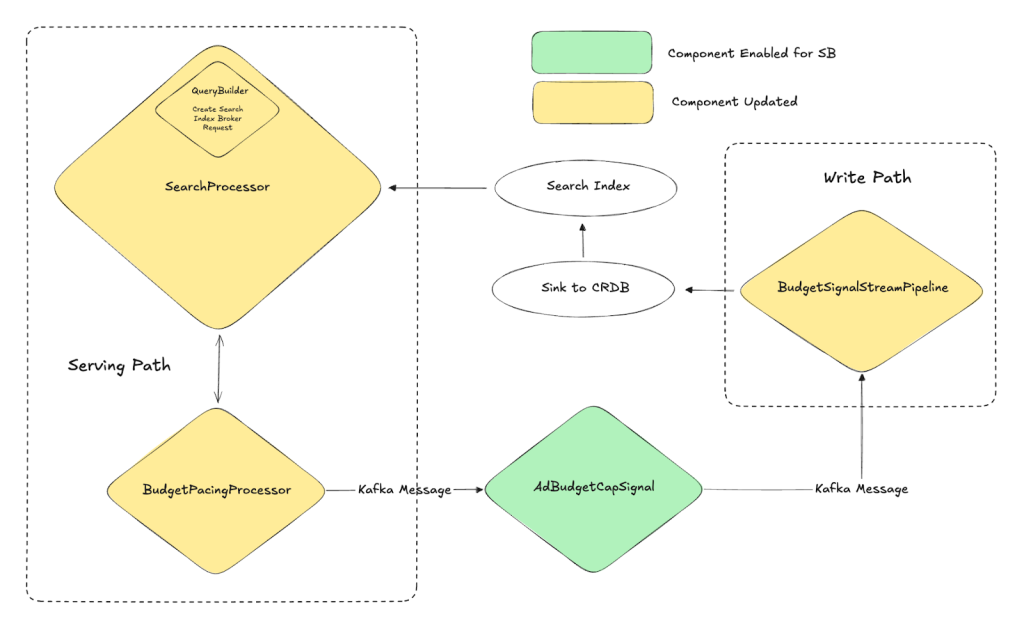
If an ad is shown after its campaign’s daily budget is spent, the advertiser isn’t charged, which means that DoorDash is giving away inventory for free while paying the computational cost of serving up the ad. To prevent this, the BudgetPacingProcessor filters out SB candidates with exhausted daily budgets, , but this approach inflates tail latency: At peak, nearly half of retrieved ads were discarded. We needed the serving path to know a campaign’s budget state before it left the index, not after. Equally important, merchants expect their campaigns to resume as soon as they increase their budgets. Any budget-aware system therefore needs both fast capping and fast uncapping. We already rely on a budget-cap signal for our more established ad formats — sponsored products and sponsored listings — and it has proven both stable and effective. This project ports that proven mechanism to the newer sponsored brand channel while adding a time-zone-aware expiration timestamp.
Increasing end-to-end flexibility
We followed these steps to add a flexible budget signal:
- A more flexible signal: The Ads Economics team asked for a way to override the old “expire at midnight EST” rule because merchants in other time zones may want to use a local time as a more logical reset point. We extended the signal to include an optional expiration timestamp. In the absence of an expiration value, we continue to use midnight EST.
- Kafka as the transport layer: When the budget pacing processor detects that spend has hit the daily limit, it publishes a record to a Kafka topic that identifies the campaign and how long the budget cap should last; we currently can manually configure this. Kafka, together with Apache Flink and transactional sinks, enables exactly-once delivery guarantees while decoupling real-time serving from the slower batch world.
- Streaming the signal into storage: An Apache Flink streaming job consumes the topic, then:
- Converts the expiration or midnight fallback to an epoch-seconds integer;
- Writes that value into a new column — DAILY_BUDGET_CAPPED_UNTIL — in our CockroachDB table of ad products;
- Emits a change event that triggers the search index to re-index just the affected campaign document. Because the timestamp lives with the rest of the campaign metadata, no joins or external lookups are required later.
- Quick uncapping on budget updates: If a merchant increases their daily budget mid-day, a separate change-data-capture pipeline spots the increase and clears the capped-until field. The next retrieval cycle immediately treats the campaign as eligible again with no manual intervention required.
Retrieval without regret
With the budget state now part of every indexed document, the SB query builder simply ignores campaigns when their capped-until timestamp is still in the future. Because the exclusion happens inside the index, out-of-budget campaigns never leave storage and thus never need to be filtered out later.
Impact
Following the launch, the P99 latency for the SearchCandidateProcessor dropped sharply to approximately 20 ms, with the improvement visible immediately after the deployment. In parallel, as shown in Table 1, the BudgetPacingProcessor’s candidate drop percentage stabilized at 0% over an 11-day period after the changes were deployed, ensuring more consistent performance.
| Metric | Before | After | Δ |
| SB search-processor P99 latency | 35 ms | 20 ms | –15 ms (-43%) |
| Peak candidate drop rate | 45% | 0% | –45% |
Conclusion
A single, thoughtfully placed eligibility flag proved to be a high-leverage optimization: It eliminated unnecessary candidate retrieval, reduced latency, and aligned spend tracking with merchant expectations through customizable expirations. The core insight is simple but powerful — move dynamic “should-serve” decisions as close to the data as possible. As sponsored brand inventory grows, the milliseconds saved today will compound into critical capacity needed to support future expansion.
Using GenAI to Reimagine In-App Shopping
By Sai Kolasani
When you search for an item like “fresh vegetarian sushi” on DoorDash, you likely expect to see something that matches your craving: Something flavorful, something plant-based, something personalized. Historically, however, the platform has struggled to preserve such specific user intent.
This summer, I worked on the Core Consumer ML team to design and build a genAI-powered context shopping engine. My project tackled the real-world challenge of context loss, leveraging embedding-based retrieval and reranking powered by a large language model (LLM) to personalize store experiences in real time. We aimed to increase conversions by making item discovery more intelligent and contextual.
Exploring methodologies and challenges
The key challenge in creating a personalized shopping experience stems from a complex blend of factors: Lost user context, decision fatigue caused by generic recommendations, and stringent performance constraints. We conducted in-depth evaluations of several retrieval methodologies to understand their feasibility and limitations, including:
- Deep neural network-based retrieval
- Concept: Predicts click-through rate or conversion rate for user-item pairs, offering semantic matching within a single model.
- Pros: Unified inference pipeline with strong potential for highly relevant recommendations.
- Cons: Not practical because of extensive data requirements and significant resource investments needed to train and maintain such models at scale. The cost of data collection and processing also poses substantial hurdles.
- Large language model, or LLM-only pipeline
- Concept: Relies solely on an LLM for context understanding, candidate generation, and ranking in a single call.
- Pros: Provides rich, highly contextualized outputs, significantly enhancing clarity and the relevance of recommendations.
- Cons: Severe latency issues of more than 20 seconds, making it unsuitable for real-time consumer-facing environments. Practical deployment also constrained by extremely large prompt sizes and processing overhead.
- Embedding-based retrieval (EBR)
- Concept: EBR converts search queries and items into numerical vectors — embeddings — and, with simple business-rule filters, quickly fetches relevant items from that vector database.
- Pros: Achieves near-instantaneous retrieval with minimal computational overhead.
- Cons: Offers limited personalization, often returning duplicates or irrelevant items by failing to consider nuanced user preferences, such as dietary restrictions or taste profiles.
- Hybrid: EBR plus LLM pipeline
- Concept: Combines rapid nearest-neighbor search using FAISS (Facebook AI Similarity Search) candidate retrieval with refined LLM-based reranking and filtering.
- Pros: Balances quick retrieval with LLM’s sophisticated context and relevance evaluation. Significantly enhances personalization, precision, and contextual depth while maintaining acceptable latency.
- Cons: Increased system complexity and orchestration challenges caused by reliance on multiple models and stages.
Hybrid proves its worth
The last method — hybrid EBR+LLM pipeline — proved superior to the other options because it successfully addresses the shortcomings of the other single-method approaches. However, adopting this hybrid method introduced specific implementation challenges:
- Latency management: DoorDash’s strict latency constraints demand careful optimization. The hybrid approach requires parallelizing retrieval and LLM operations to maintain low latency.
- Cost optimization: It was crucial to strategically manage the usage and scale of costly LLM calls. This demanded efficient orchestration to ensure economic feasibility.
- Context balancing: It was challenging to ensure the system appropriately balanced real-time context signals and stable user preferences, necessitating advanced query expansion techniques and embedding optimizations.
Building the context-based personalization engine
To effectively implement the hybrid approach, we constructed a multi-stage retrieval engine designed to balance speed, personalization, and scalability, as outlined in Figure 1. We approached development through several stages.

Stage 1: Context and embedding fetching: During this stage, we conducted real-time compression of user profiles, including dietary preferences, historical interactions, and contextual session data. Using these precomputed embeddings, the LLM model converted item descriptions into vector representations for efficient semantic matching.
Stage 2: Candidate retrieval via EBR: We used query expansion techniques to enhance retrieval quality, injecting user-specific terms such as dietary restrictions and taste preferences — for example, "vegan," "savory," or "spicy" — into embedding vectors, which refined and personalized search results. The process used semantic similarities between relevant item candidates from the embedding database and implemented intelligent query expansion techniques to refine results by embedding user preferences directly into the retrieval process.
Stage 3: LLM-based reranking and carousel generation: We applied the LLM model for precise reranking, significantly improving recommendation accuracy by evaluating semantic relevance and contextual alignment. We also leveraged the LLM model to dynamically generate compelling carousel titles and detailed item descriptions, enhancing user experience with contextual explanations.
Experimentation, results, and impact
Our extensive experimentation validated the hybrid retrieval engine’s performance and impact.
Latency achievements: Initial tests with single-method approaches revealed impractical latency of more than 20 seconds using LLM alone. Our optimized hybrid solution achieved end-to-end latency of approximately six seconds, with store page load times consistently under two seconds, which is fully compliant with DoorDash's strict performance guidelines.
Cost efficiency: Through strategic use of EBR combined with selective LLM calls, we significantly minimized compute resources and associated costs, proving the economic scalability of our approach.Enhanced user experience: User experience demonstrations clearly illustrated the transformation from static, generic menus to dynamic, personalized item carousels. Preliminary feedback indicated notable improvements in user satisfaction, with increased perceived relevance and ease of navigation, underscoring the tangible impact of enhanced personalization.
As shown in Figure 2, the development and successful implementation of the hybrid retrieval approach represent a significant step forward in real-time personalization for DoorDash’s consumer platform. By balancing computational efficiency, latency constraints, and deep contextual relevance, this innovative solution significantly improved user engagement and reduced decision fatigue. The insights gained throughout this process highlight the immense potential of hybrid approaches in large-scale consumer applications, paving the way for further enhancements and continued innovation in personalized digital experiences.
Improving Stability of DoorDash’s CPG Campaigns Third-Party API
By Dominic Charles
DoorDash’s first-party ads manager is a powerful tool used by companies to manage a variety of advertisement campaigns. To provide a flexible alternative, DoorDash also offers a third-party API which is a popular alternative that some of our largest partners commonly use. As our ads platform evolves with new features, the existing API version has presented some structural and usability limitations. This summer, my project was to address some of this technical debt by focusing on a new version of the API, specifically improving its reliability and refactoring its campaign endpoints.
Implementation and key milestones
This project’s goal was to modernize the API design by making it more consistent and easier for external partners to work with.
Standardized error handling
One of the key pain points for external API users has been inconsistent error messages. To address this, I worked to standardize error responses across the third-party API. This involved updating all endpoints to return errors using a single, consistent format.
Before:
{
"timestamp": "2024-06-30T23:45:29Z",
"status": "404",
"type": "RESOURCE_NOT_FOUND",
"path": "/sp/campaigns/550e8400-e29b-41d4-a716-446655440000/SP",
"method": "GET",
"errors": [
{
"type": "RESOURCE_NOT_FOUND",
"message": "Campaign with id=550e8400-e29b-41d4-a716-446655440000 not found"
}
]
}After:
{
"timestamp": "2024-06-30T23:45:29Z",
"status": "404",
"type": "RESOURCE_NOT_FOUND",
"path": "/sp/campaigns/550e8400-e29b-41d4-a716-446655440000/SP",
"method": "GET",
"errors": [
{
"type": "RESOURCE_NOT_FOUND",
"message": "Campaign with ID '550e8400-e29b-41d4-a716-446655440000' was not found or user does not have permission to access it."
}
]
}This change makes error handling more predictable and transparent for developers, which ultimately reduces the need for support. I also refined existing error messages to ensure they are clearer and provide actionable guidance.
Endpoint renaming
To improve clarity, I focused on renaming both internal and external endpoints. To ensure a smooth transition and avoid disrupting existing integrations, we utilized a feature flag to control access to the new v2 endpoints. I also helped to implement the renamed v1 endpoints, which now use a more standardized path format.
Before (Old 3P path):
- /ads/api/v1/{campaignType}/campaigns
After (New 3P path):
- /3p/campaigns/v1/{campaignType}
Additional testing
The last key part of my project this summer was the planned introduction of a new end-2-end testing system. This new layer of testing is an additional reinforcement that can protect systems from failing due to unexpected changes that can break integrations. This testing will help ensure greater robustness and confidence in future releases, providing a much-needed safety net when releasing changes to production.
Impact
This project was a crucial step in laying a reliable foundation for DoorDash’s growing ads platform. As other developers build off this project, this new foundation will likely allow for more efficient implementation and fewer bugs.
Getting to improve a widely used tool gave me a lot of insight into the importance of enforcing consistency when building large-scale systems and working in a rapidly changing environment. It's a vital step towards ensuring the API can support future features without disrupting our external partners





