
When consumers search on DoorDash, they are usually trying to accomplish something quickly. They have a specific idea in mind when they type a query, and they expect the results to match that intent. The same expectation can be said to apply to ads, as well. The best ads do not feel like interruptions; they feel like useful results that belong in the search experience. Poorly matched results not only hurt the user experience but can also lead to revenue loss. That makes it critical to show only those ads that are truly relevant to the search query.
We address this problem at DoorDash with query-item relevance prediction. Recent developments in small language models (SLMs) have made it practical to use relevance prediction in production ads served at scale. What results is a more robust relevance layer that combines stronger semantic understanding with fast online prediction for sponsored results that better match search intent.
In this post, we describe how we used an offline large language model (LLM) to generate relevance supervision at scale and then trained an SLM to conduct low-latency online relevance prediction.
Why relevance matters
Because people tend not to use product catalog language when they search, not every eligible item should be shown as a result, especially when it comes to ads. A query such as “healthy snacks” reflects a goal, not a specific item. Searching the phrase “birthday candles” may signal a use case, not an exact product. A search on the term “sparkling water” can imply openness to different brands and formats, even if product titles vary.
This kind of semantic understanding is crucial in local commerce, where catalogs are broad, merchant content is inconsistent, and the same intent can be expressed in many ways. A sponsored item may seem to fit the search term, but may be a weak semantic match; serving up this kind of weak result can make ads feel noisy. When relevance is strong, sponsored results feel like a natural part of the search experience.
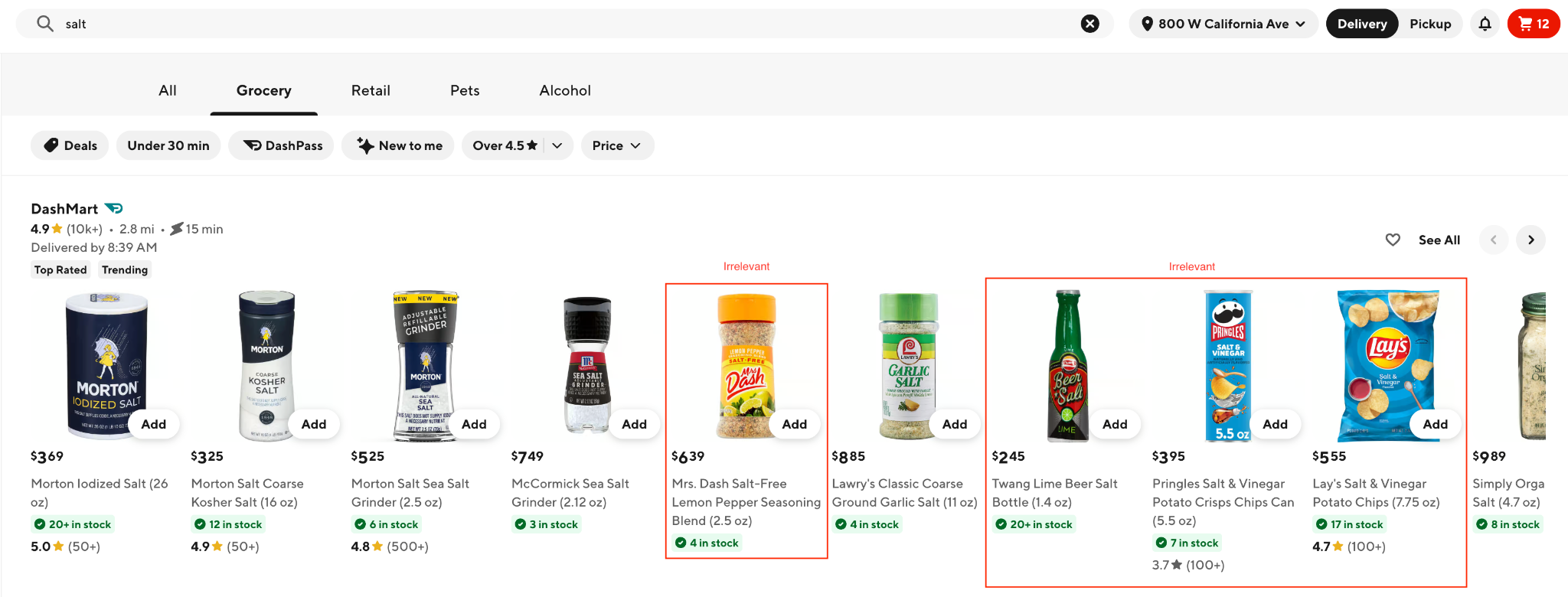
A purely keyword-based retrieval system matches item documents with a search query and is optimized for recall. Such retrieval systems can fetch irrelevant items simply because of overlapping keywords. Ranking models, on the other hand, optimize for personalization. For example, if a user has previously bought a lot of chips, that user’s propensity for engaging with chips is considered high. But when the same user searches for salt, the keyword-based retrieval logic retrieves salted chips; the personalization only amplifies the experience. As shown in Figure 1, the search term “salt” includes irrelevant items like “Pringles Salt & Vinegar Potato Crisps Chips Can (5.5 oz)” or “Lay’s Salt & Vinegar Potato Chips (7.75 oz)”. Personalization alone doesn’t solve the relevance problem, creating a need for a separate relevance prediction task. While the retrieval system optimizes for recall, the relevance model focuses on precision.
How to define the relevance prediction task
Instead of inferring relevance indirectly from clicks or folding it into ranking, this user-agnostic model evaluates query-item relevance directly. Operating as a dedicated query and item task at a high degree of granularity, it is based on the principle that certain results — such as a milk item for a "chips" query — are objectively irrelevant for all users. This approach explicitly contrasts with personalization, which relies on such things as user purchase history and specific historical propensities. By isolating relevance at the query-item level, it becomes easier to reason about what the model should learn and how explicit constraints should be applied.
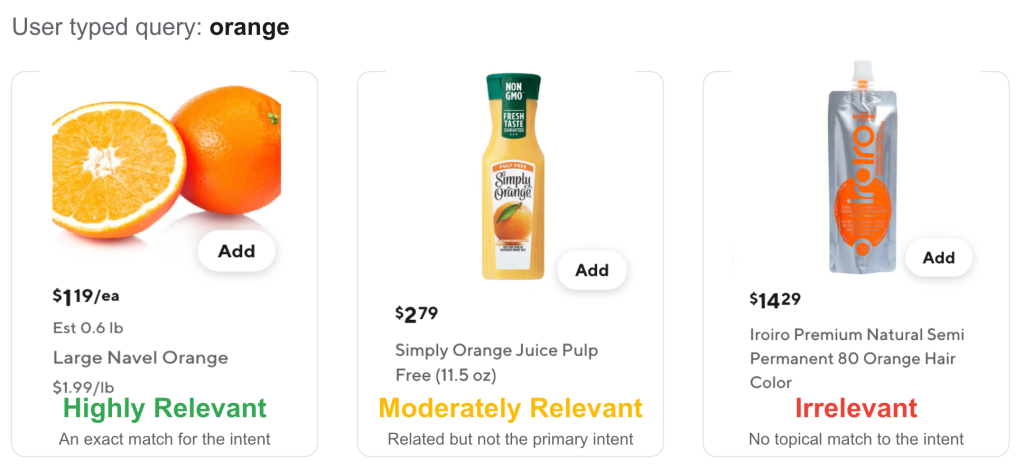
Relevance labels follow a 0-1-2 scale, where each label carries a precise meaning:
- 0 = Irrelevant: Disconnected product sharing no meaningful intent match; perceived as noise.
- 1 = Moderately relevant: An acceptable substitute, such as Pepsi for Coke, or a secondary user intent, such as orange juice for the query “orange,” that is missing specific attributes or formatting.
- 2 = Highly relevant: Direct hit that precisely satisfies the search mission and user intent.
This three-level scale preserves partial matches, which are neither clearly correct nor clearly incorrect. Training on 0-1-2 labels gives the model a more nuanced notion of relevance, which leads to more precise scoring at serving time. The examples in Figure 2 illustrate this distinction:
The relevance prediction system acts as a gate: Label 0 keeps the auction fair by filtering out irrelevant items beforehand while ensuring with Label 2 that highly relevant items are considered for the most prominent ad slots.
Dataset curation and model training paradigm
Once the problem is framed correctly, the next challenge is how to generate supervision at scale. Training a strong relevance model requires labeled examples of query-item pairs. Human labeling provides a strong foundation, but it does not scale well across a large and constantly changing catalog. Search systems contend with far too many query-item combinations to rely on manual labeling alone. This is where LLMs become especially useful, as shown in Figure 3.

As shown in Figure 4, the LLM acts as a teacher. To develop it, human annotators labeled some 700,000 query-item pairs to create detailed guidelines, which could then supervise adaptation of an LLM for the relevance prediction task. On this dataset, the teacher model achieved an accuracy of 86% on the 0-1-2 classification task; agreement was strongest on clear positives and clear negatives. Combining both the moderately relevant and highly relevant items resulted in a two-class accuracy of nearly 91%. Such two-class accuracy is important because filtering irrelevant items from the search funnel is paramount. We then generated labels offline using the fine-tuned LLM for the query-item pairs generated from real production traffic over six months. This mirrors the same judgment a human rater would make, but applies it consistently and at scale across millions of pairs. Because this step runs offline, it is not constrained by serving latency. It is a batch process, which gives us the freedom to generate high-quality labels at a volume that would be impractical to produce manually. The role of this model is to generate scalable supervision for the production model.
The SLM serves as the production inference engine. It is trained on the relevance labels generated offline by the fine-tuned LLM. Based on bidirectional encoder representations from transformers, or BERT, the SLM is a compact architecture optimized for real-time relevance prediction in production serving.
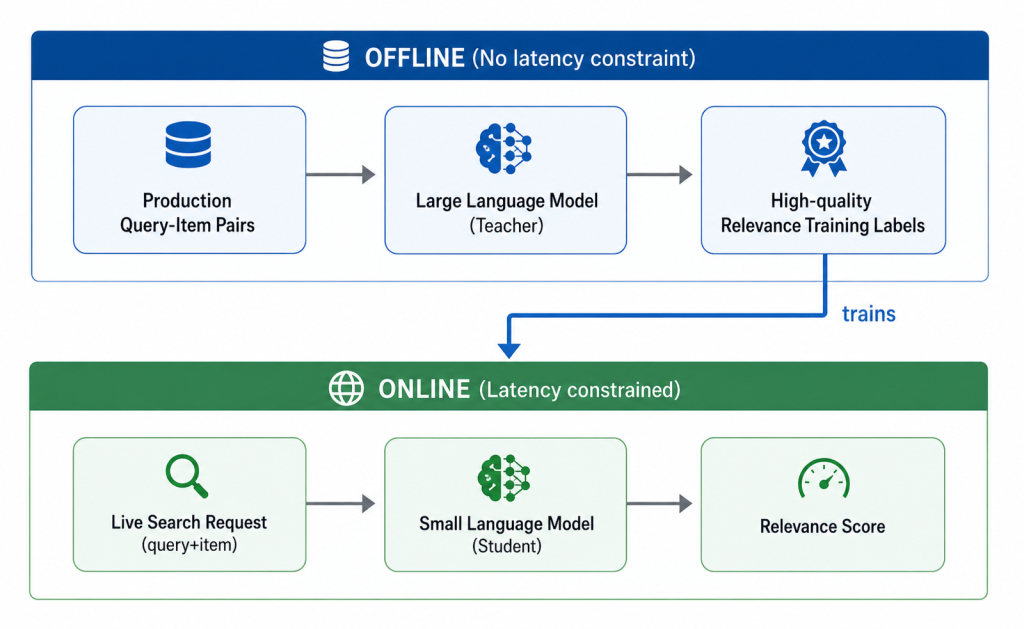
This architectural separation follows a teacher-student pattern: The LLM generates high-quality relevance labels offline and the SLM learns to reproduce that judgment in a compact form that is suitable for latency-constrained production serving.
Model architecture and training
The production relevance model uses a bi-encoder architecture chosen specifically for the latency requirements of online search. In a bi-encoder, the query and the item are passed through two independent BERT-based encoder towers, each producing a dense vector representation, as shown in Figure 5. Embeddings for queries and items are computed through an offline cron job and cached in a key-value store. During serving, the online predictor fetches these embeddings and uses a bilinear layer to compute the relevance score.
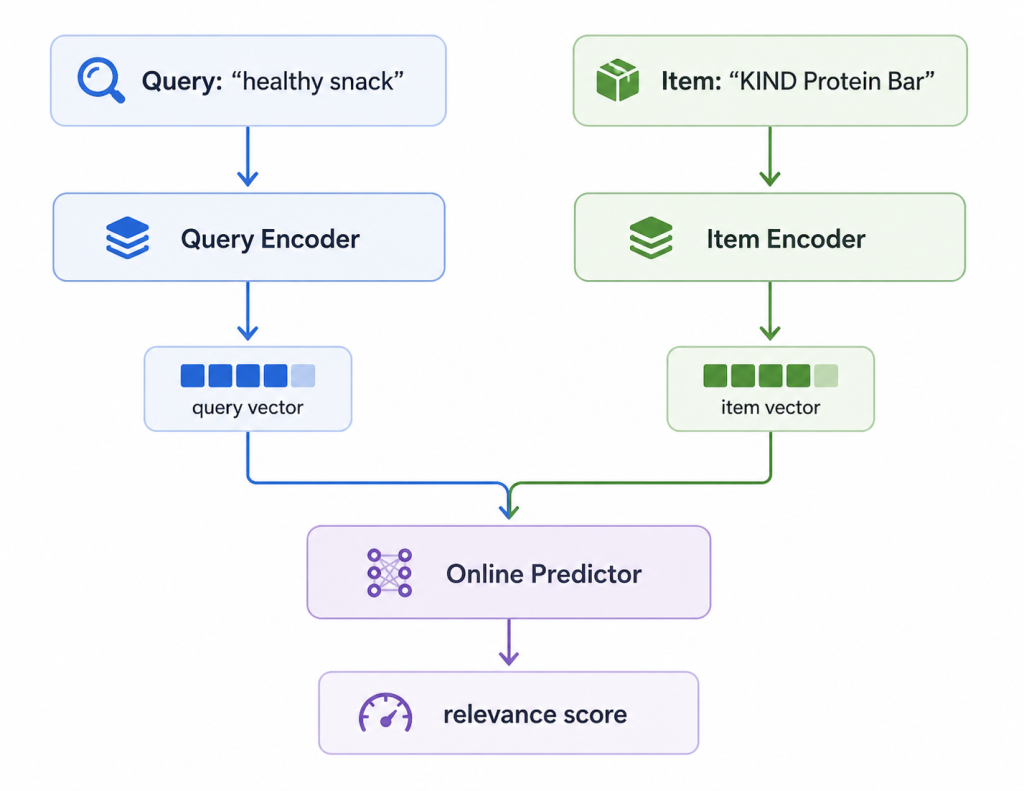
To identify the right production architecture, we evaluated several BERT-based encoder backbones, including DistilBERT, DeBERTa, RoBERTa, ALBERT, TinyBERT, and E5. We also explored different pooling strategies, such as CLS pooling and mean pooling, to understand the quality-latency tradeoffs of each configuration.
Because the serving system operated under strict latency constraints, embedding size was an important design consideration. We explored compact representations that could preserve relevance quality while keeping online scoring efficient. For dimensionality reduction, we evaluated two approaches: A direct linear projection layer on top of the encoder output and Matryoshka training, which is designed to produce embeddings that remain useful at smaller dimensionalities. In the end, we selected the direct linear projection approach because it provided the best balance of simplicity, efficiency, and production readiness for our use case.
Across these experiments, a 64-dimensional embedding struck the best balance between relevance quality, dimensionality reduction, and serving latency. The final production model used a DistilBERT bi-encoder with shared encoder weights for the query and item towers, CLS pooling, 64-dimensional embeddings, and an online bilinear layer for low-latency relevance scoring.
We trained these models using a distributed data parallel framework across multiple GPUs, which allowed us to scale training efficiently over a large relevance dataset. Training used the AdamW optimizer, with cross-entropy as the initial loss function. We also evaluated the COnsistent RAnk Logits, or CORAL, framework, an ordinal regression method that better reflects the ordered structure of the 0-1-2 relevance labels. We selected the final production checkpoint based on validation accuracy; the best-performing model reached 97%.
Relevance model in the overall serving pipeline
Integrating the relevance model into the serving pipeline requires careful placement so that system performance and reliability are preserved. Figure 6 shows the serving pipeline and where the relevance model fits within it.
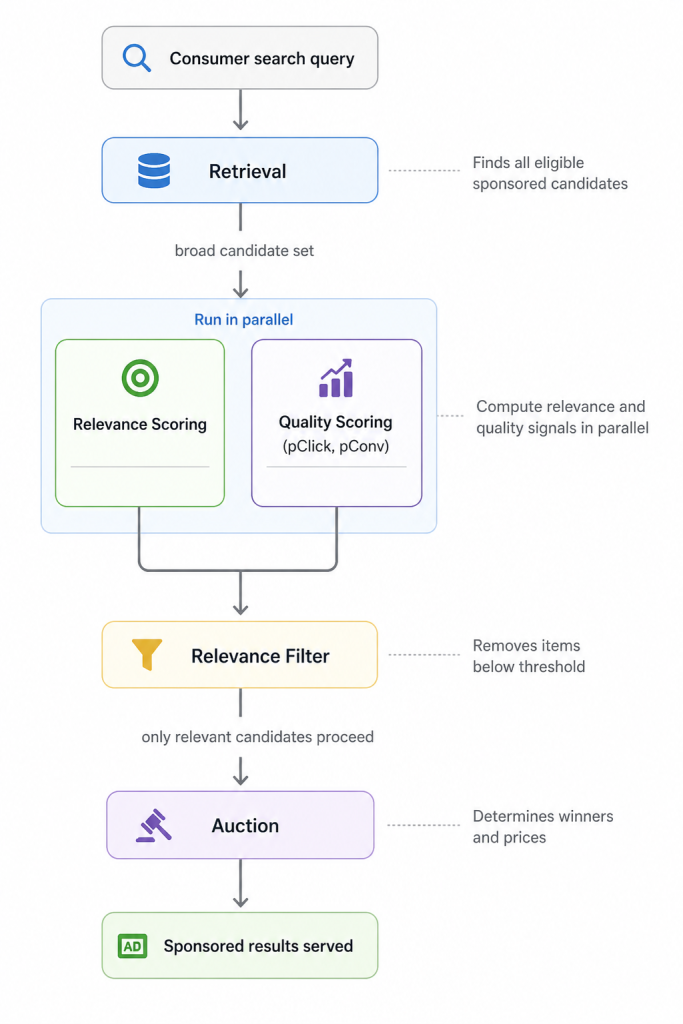
Relevance and quality scoring are executed in parallel. A separate model is used for quality scoring, which predicts the probability a consumer will click or convert. Because neither depends on the other’s output, they run simultaneously. The relevance filter combines both signals and runs after both are complete. This keeps the latency impact of adding a relevance scoring layer close to zero.
The relevance filter is applied before the auction. That sequencing matters. The auction determines which item wins and what price is paid, so it should operate over a candidate set that has already been filtered for relevance. As a result, a well-funded campaign targeting irrelevant inventory cannot win simply by bidding aggressively because it is removed before the auction begins.
Online evaluation results
We assess relevance using metrics such as Precision@2 and NDCG@10, in which we leverage fine-tuned generative pre-trained transformer models to provide a scalable and consistent measurement of result quality. The new SLM-based relevance model achieved a 5.2% relative gain in Precision@2 over the incumbent gradient boosted decision tree production model during online A/B testing.
Conclusion and future work
In practice, the query-item relevance model improves the system by helping it serve candidates that better match consumer intent. This approach was shaped by two key ideas: Framing relevance as a direct, user-agnostic query-item matching task, and separating the LLM teacher used for offline label generation from the fast student model used in serving.
Our current LLM teacher model uses a fine-tuned, closed-source model for generating scalable offline supervision. A potential future direction to explore would be to migrate to a fine-tuned open-source alternative for label generation and assess its efficacy as a teacher model.



