

One of challenges we face almost everyday is to keep our API latency low. While the problem sounds simple on the surface, it gets interesting sometimes. One of our endpoints that serves restaurant menus to our consumers had high p99 latency numbers. Since it’s a high traffic endpoint we naturally use caching pretty intensively. We cache our serialized menus in Redis to avoid repeated calls to the data base, and spread out the read traffic load. By the end of this post we will present how we used compression to not only improve our latency, but also to get ourselves more space to cache.
The problem with large values
After some deep instrumentation and inspection we determined the problem in this particular scenario was that some of our menus were almost half a MB long. Our instrumentation showed us that reading these large values repeatedly during peak hours was one of few reasons for high p99 latency. During peak hours, reads from Redis took more sometimes at random took more than 100ms. This was especially true when a restaurant or a chain with really large menus were running promotions. Why this happens should be a surprise to no one, reading or writing many large payloads over the network during peak hours can end up causing network congestion and delays.
Compression to the rescue
To fix this issue, we obviously wanted to reduce the amount of traffic between our server nodes and cache. We were well aware of techniques like LevelDB using snappy to compress, and decrease the on-disk size. Similarly, our friends at CloudFlare also used a similar technique to squeeze more speed out of Kafka. We wanted to do something similar i.e. use a compression algorithm, with good speed and a decent compression ratio.
Like other folks we did our benchmarks, and found that LZ4, and Snappy were two nice options. We also considered other famous options like Zlib, Zstandard, and Brotli but found their decompression speeds (and CPU load) were not ideal for our scenario. Due to the specific nature of our endpoint, we found LZ4 and Snappy were more favorable. Both libraries were in the Goldilocks zone of compression/decompression speed, CPU usage, and compression ratio.
There are a plethora of benchmarks on the internet already comparing compression speeds and ratios. So without going into detail and repeating the same benchmarks, here are some examples and a summary of our findings:
- 64,220 bytes of Chick-fil-A menu (serialized JSON) was compressed down to 10,199 bytes with LZ4, and 11,414 bytes with Snappy.
- 350,333 bytes of Cheesecake factory (serialized JSON) menu 67,863 bytes with LZ4, and 77,048 bytes with Snappy.
Here are our overall observations:
- On average LZ4 had slightly higher compression ratio than Snappy i.e. while compressing our serialized payloads, on average LZ4 was 38.54% vs. 39.71% of Snappy compression ratio.
- Compression speeds of LZ4, and Snappy were almost the same. LZ4 was fractionally slower than Snappy.
- LZ4 was hands down faster than Snappy for decompression. In some cases we found it to be 2x faster than Snappy.
In case you are curious, when comparing different compression techniques yourself you can use lzbench. Our benchmarks clearly showed LZ4 to be more favorable, then Snappy. Due to higher compression ratio, almost same compression time, and (most important of all) fast decompression speed LZ4 emerged as our favorite option.
Connecting the dots
To see things in action before deploying them to production, we setup a sandbox and chose 10K random menus. The sample contained a good mix of menu sizes ranging from 9.5KB - 709KB when serialized. Getting and setting these entries in Redis without compression, with Snappy, and with LZ4 yielded following numbers:
| Redis Operation | No Compression (seconds) | Snappy (seconds) | LZ4 (seconds) |
|---|---|---|---|
| Set (10000) | 16.526179 | 12.635553 | 12.802149 |
| Get (10000) | 12.047090 | 07.560119 | 06.434711 |
The above numbers confirmed the hypothesis of potential gains while doing read/write operations using LZ4 compression. With these results, we made appropriate changes in our code, and slowly on-boarded different stores.
Conclusion
After deployment in production our instrumentation not only confirmed a drop in p99 latency, but we also noticed reduced Redis memory usage.
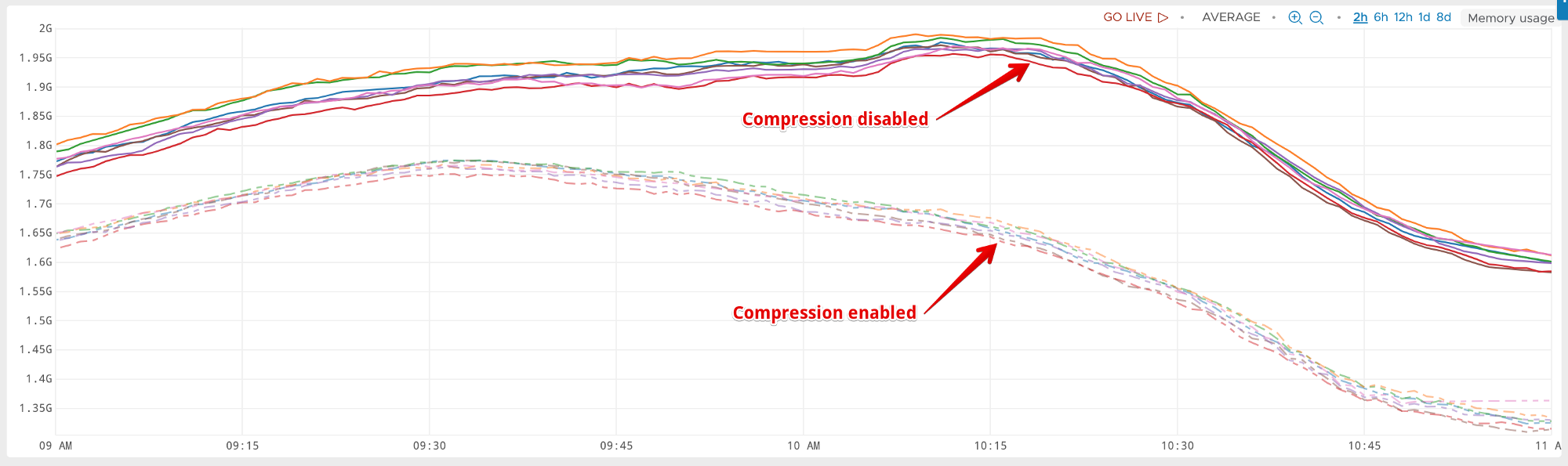
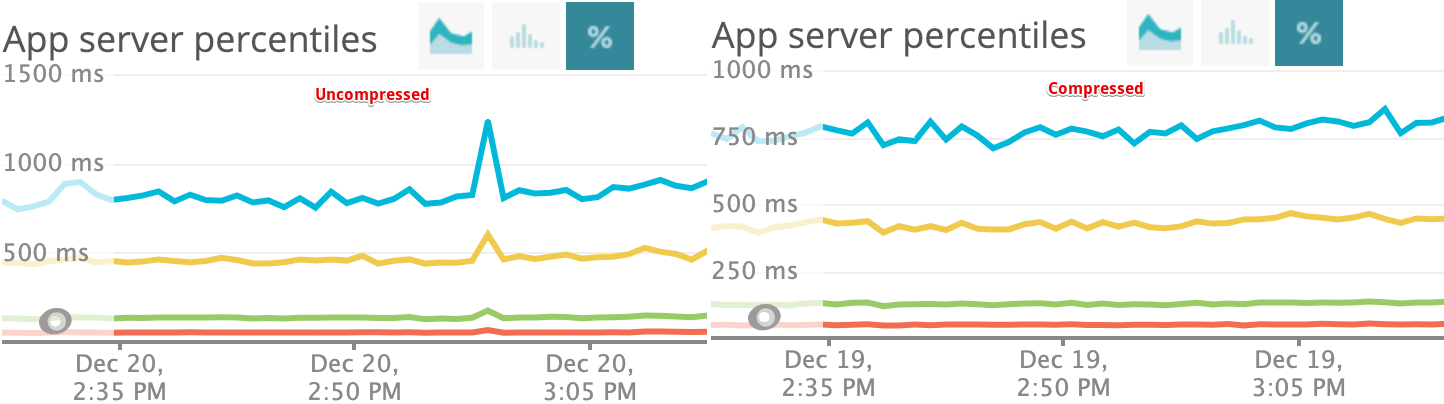
p99 latency and a spike for uncompressed values (compared on same time when values are compressed)
While the choice and the observed effect looks obvious now; understanding, and diagnosing the problem was hard at the beginning. Not only we are reducing any potential congestion during peak hours, but we are allowing ourselves to cache more data in Redis.
At DoorDash it’s really important for us to make the consumer experience as positive as possible! We look for every possible opportunity to improve, and optimize our system. In this particular scenario compression helped us improve our system when dealing with large payloads and Redis.