DoorDash utiliza el aprendizaje automático para determinar en qué invertir mejor su presupuesto publicitario, pero la rápida evolución del mercado y los frecuentes retrasos en la recopilación de datos dificultaban nuestros esfuerzos de optimización. Nuestro nuevo modelo de previsión de atribución nos permite predecir la eficacia de las campañas publicitarias a partir de sus datos iniciales, lo que nos ayuda a tomar antes decisiones empresariales críticas".
Normalmente, tenemos que esperar algún tiempo para medir el rendimiento de los anuncios debido a nuestra metodología de atribución. Esta lentitud de reacción significa que, si un canal publicitario funciona especialmente bien, no podemos trasladar rápidamente nuestros fondos de marketing a ese canal.
Nuestro nuevo modelo de previsión de atribución predice el volumen de conversión final de un anuncio tras observar únicamente sus datos iniciales. Esto nos permite utilizar datos más recientes, optimizando nuestras conversiones por gasto publicitario al escalar los mejores canales a medida que el rendimiento cambia con el tiempo.
Más allá de la optimización rutinaria, este marco de previsión es especialmente útil durante los experimentos de marketing -donde identificar antes el anuncio ganador acelera el impacto- y podría extenderse a otros problemas de información diferida, como la venta de entradas para conciertos, las reservas hoteleras o la venta de flores navideñas.
Introducción a la metodología de atribución
Antes de hablar del modelo de previsión, analicemos qué es un sistema de atribución y cómo elegir uno. Un sistema de atribución ayuda a las empresas a medir la eficacia de las campañas de marketing. Tiene dos elementos clave: el método de atribución y la ventana de atribución.
Revisión de los métodos de asignación
El método de asignación determina cómo asignar el crédito a través de los puntos de contacto de marketing cuando un nuevo consumidor realiza su primer pedido, lo que comúnmente se denomina conversión. Los métodos de asignación pueden ser monotáctiles o multitáctiles, dependiendo del número de canales que obtengan crédito por la conversión. Véase la ilustración de la figura 1.
- El contacto único asigna todo el crédito de conversión a un único canal, asumiendo que el primer o el último punto de contacto impulsa la conversión.
- Multi-touch tiene en cuenta todos los puntos de contacto a lo largo del camino hacia la conversión. Como ejemplo sencillo, podría distribuir el crédito entre todos los puntos de contacto por igual.

Compromiso en las ventanas de atribución
Intuitivamente, el impacto del marketing no siempre es inmediato. Después de que el cliente del ejemplo anterior viera el anuncio de DoorDash en televisión, podría haber tardado días o incluso algunas semanas antes de realizar su primer pedido. Por lo tanto, otra cuestión clave en la metodología de atribución es cuántos días mirar hacia atrás al definir los puntos de contacto de marketing. Este período de tiempo es la ventana de atribución.
Una ventana de atribución larga permite a las empresas reconocer más conversiones para un anuncio determinado. La figura 2, a continuación, muestra la diferencia en la curva de costes entre dos ventanas de atribución. Con una ventana de atribución más corta (la atribución de siete días abajo en rojo), los nuevos clientes que se convirtieron después de siete días no se acreditan al anuncio, lo que lleva a una curva de costes que subestima la eficacia del anuncio.
Manténgase informado con las actualizaciones semanales
Suscríbase a nuestro blog de ingeniería para recibir actualizaciones periódicas sobre los proyectos más interesantes en los que trabaja nuestro equipo.
Introduzca una dirección de correo electrónico válida.
Gracias por suscribirse.
Al mismo tiempo, los patrones de conversión varían según los anuncios. Por ejemplo, algunos anuncios, como los de los canales de búsqueda, conducen a una conversión rápida, mientras que los anuncios de otros canales, como la televisión o la radio, son más lentos. Una ventana de atribución más corta hará que subestimemos más la atribución de los anuncios más lentos, lo que dará lugar a decisiones de marketing subóptimas.

Sin embargo, una ventana de atribución demasiado larga tampoco es deseable porque requiere un tiempo de espera más largo para medir completamente el rendimiento de un anuncio. En un mercado que cambia con rapidez, los tiempos de espera más largos pueden dar lugar a curvas de costes desfasadas. Si pudiéramos incluir de algún modo estos datos que aún no están disponibles, la información adicional mejoraría materialmente nuestras curvas de costes y, a su vez, las decisiones de marketing, como se muestra en la Figura 3:

El problema de nuestro antiguo sistema de atribución
Actualmente, DoorDash utiliza un sistema de atribución de último toque de varios días para todos los canales de marketing digital, lo que proporciona un buen equilibrio entre una visión holística de las conversiones para la mayoría de los anuncios y un tiempo de espera razonable para un rendimiento de atribución totalmente actualizado.
Sin embargo, una ventana de atribución de varios días sigue significando que los anuncios publicados en los últimos días se basan en datos de atribución incompletos, que no pueden informar las decisiones de marketing hasta que la ventana haya transcurrido. Dados los rápidos cambios en el panorama del marketing de entrega de comida, tener que esperar antes de reaccionar a los datos recientes no es lo ideal. Necesitábamos una forma de desbloquear nuestros datos más recientes.
Previsión de los resultados finales
Antes de entrar en detalles, hablemos de la solución ideal. Nuestros canales publicitarios tienen formas y tamaños diferentes. Por ejemplo, publicamos un pequeño número de anuncios de televisión de alto coste y un gran número de anuncios de búsqueda de bajo coste (a veces dirigidos a palabras clave concretas y poco conocidas, como errores ortográficos de "DoorDash"). Lo ideal sería que nuestra solución gestionara tanto anuncios pequeños como grandes.
El enfoque que elegimos fue construir un modelo de previsión que predijera los datos finales de atribución a partir de una cantidad limitada de datos iniciales.
Definición de la precisión de las previsiones
Una forma sencilla de medir el rendimiento de nuestro modelo de previsión es mediante el backtesting. El backtesting consiste en entrenar el modelo con datos antiguos y comprobar si puede predecir datos más recientes.
La principal métrica de rendimiento elegida es el error medio absoluto (MAE),

donde ci son las conversiones atribuidas al anuncio i y el sombrero ^ distingue una predicción del valor real. Como el MAE simplemente toma el valor absoluto de los errores de predicción, no está sesgado hacia los anuncios más grandes (a diferencia del error cuadrático medio, RMSE) o los más pequeños (a diferencia del error porcentual absoluto medio, MAPE).
Sin embargo, uno de los inconvenientes del MAE es que varía con el volumen de conversiones, lo que dificulta la comparación entre canales u otros segmentos, como el día de la semana. Para facilitar la comparación, normalizamos el MAE por volumen de conversión:

Construcción del modelo de previsión
Queríamos un modelo de previsión que actualizara sus predicciones a medida que recogíamos más datos. Debería ser capaz de predecir el resultado final de la atribución, tanto si hay cuatro días de observaciones como si hay diez. Cuantos más datos iniciales tenga el modelo, más precisa será la predicción.
Evaluamos dos tipos de modelos:
- Modelos heurísticos sencillos
- Modelos de aprendizaje automático
Modelos heurísticos sencillos
Los modelos más sencillos que hemos considerado suponen que el patrón de conversión de un anuncio será el mismo en el futuro que en las N semanas anteriores. Por ejemplo, supongamos que queremos predecir el número de conversiones atribuidas a un anuncio al final de una ventana de 30 días, c(30 d). La predicción para el día t (día t tras la publicación del anuncio) es

donde c(t) es el número de conversiones atribuidas observadas hasta el momento. Este enfoque aplica directamente un coeficiente histórico para predecir las conversiones finales a partir de la observación actual.
A continuación se presentan algunos de los parámetros o variaciones que exploramos con este modelo heurístico. Seleccionamos el mejor modelo parametrizado mediante backtesting, como se describe en la sección anterior.
- Número de semanas N utilizado para calcular el índice de conversión histórico. Este parámetro corresponde a la cuestión de cuánto tiempo se mantiene el patrón de conversión: demasiado tiempo ( N mayor) podría ser lento para captar los cambios del mercado, mientras que demasiado corto ( N menor) podría ser ruidoso. Hemos considerado valores de una a doce semanas.
- Agregación. En relación con el punto anterior, los anuncios pequeños pueden generar muy pocos datos para calcular con seguridad el ratio de conversión histórico. Agregar anuncios similares (por ejemplo, del mismo canal, creatividad o región) al calcular el ratio puede reducir el ruido.
- Ajustes de estacionalidad. La estacionalidad, especialmente el día de la semana, desempeña un papel importante en la conversión de nuevos clientes. Por ejemplo, es más probable que un consumidor haga su primer pedido un fin de semana por la noche que un martes por la noche. Para tenerlo en cuenta, podríamos calcular un ratio histórico diferente para cada día de la semana.
Modelos de aprendizaje automático
Esta previsión es un problema de regresión típico. Probamos los siguientes métodos de regresión de aprendizaje automático:

Resultados
Como se muestra en la Figura 4, los modelos LightGBM y heurístico simple superan significativamente a los demás modelos.

Sin embargo, ¿cómo se traduciría esta mejora de la precisión en mejores decisiones de marketing? Para comprender mejor el verdadero impacto, volvimos a incluir las predicciones del modelo de previsión en nuestro flujo de trabajo descendente y las utilizamos para dibujar curvas de costes. La figura 5, a continuación, muestra que cuando se incluyen estas predicciones, la curva de costes de un anuncio de ejemplo captura la eficacia del gasto con mayor precisión, lo que a su vez nos ayuda a asignar nuestro presupuesto de marketing de forma más óptima. En este caso, sin las predicciones, subestimaríamos el rendimiento del anuncio y asignaríamos por error parte de su presupuesto a otros canales.

Al igual que en el caso de la precisión de las previsiones, hemos realizado pruebas retrospectivas de la precisión de las curvas de costes utilizando el mismo método y la misma métrica MAE normalizada. Actualmente, las curvas de costes son capaces de alcanzar un MAE normalizado razonable con datos históricos retrasados, como muestra la figura 6. Al introducir las predicciones, los mejores modelos (heurístico simple y LightGBM) reducen aún más el error.

En conclusión, al aprovechar los datos recientes con mayor rapidez, el modelo de previsión de atribución mejora notablemente nuestra capacidad para trazar curvas de costes y tomar decisiones de marketing. Comprobamos que los modelos heurístico y LightGBM tenían un rendimiento similar, por lo que optamos por producir el modelo heurístico porque es más sencillo e interpretable.
Resumen y próximos pasos
Llegados a este punto, cabe preguntarse por qué el modelo más sencillo es el que mejor funciona. Creemos que hay dos razones:
- Patrones sólidos existentes: Las conversiones de los consumidores tras un punto de contacto de marketing suelen seguir un patrón determinado. La mayoría de los consumidores van a convertir en los primeros días, y el número se reduce gradualmente. Los factores externos desempeñan un papel relativamente pequeño a la hora de influir en el comportamiento del consumidor cuando el embudo de incorporación es corto. Por lo tanto, una simple heurística capta adecuadamente el flujo de conversión.
- Cantidad limitada de datos: Normalmente, sólo disponemos de varios días de observaciones en los que basar una predicción. Con esta pequeña cantidad de datos, los modelos ML más complejos no muestran muchas ventajas.
Cuando los patrones son menos obvios, o los anuncios de interés abarcan una jerarquía de diferentes regiones o países, una simple heurística podría no funcionar tan bien y podría estar justificado un modelo más avanzado.
Una metodología similar podría aplicarse a los sistemas de atribución de otras empresas. En función de los datos disponibles, un modelo sencillo como la heurística simple podría ser un buen punto de partida. Más allá de la atribución de marketing, las aplicaciones también podrían incluir otras situaciones de respuesta retardada. Por ejemplo, predecir el volumen final de entradas de un concierto a partir de los primeros días de venta, o predecir la ocupación final de un hotel en un día determinado a partir de las primeras reservas. Conocer antes el resultado final permite reaccionar con mayor rapidez y tomar mejores decisiones.
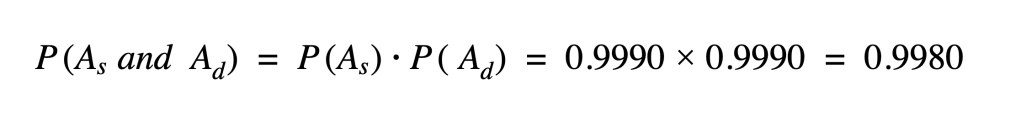






 lo que nos da un coeficiente de variación de la previsión combinada del 14,4%. Simplemente agregando variables aleatorias, conseguimos reducir la varianza con respecto a la media en más de un 40%.
lo que nos da un coeficiente de variación de la previsión combinada del 14,4%. Simplemente agregando variables aleatorias, conseguimos reducir la varianza con respecto a la media en más de un 40%.