

DoorDash runs on many microservices. A single user request may need data from multiple services, such as store metadata, menus, availability, pricing, and fulfillment context. As DoorDash traffic grew early in the company’s history, many services repeatedly requested the same low-mutation data within short time windows.
Even when the data had not changed, each request still triggered gRPC calls, repeated computation, and sometimes backend database reads. At DoorDash scale, this created unnecessary service resource usage, higher database load, and worse P90/P99 latency.
These repeated calls also increased reliability risk. When one dependency became slow or unavailable, retries and growing concurrency could spread pressure across dependent services, turning a small issue into a larger incident.
Local caches helped, but they were service-specific, inconsistent, and required each team to build and maintain its own caching logic. We needed a shared caching layer that could reduce repeated work, protect upstream services during partial outages, and be adopted without application code changes.
That motivated us to create Entity Cache.
What we built
Entity Cache is a transparent HTTP/gRPC caching proxy running inside DoorDash’s Envoy-based service mesh. It sits in the request path and serves frequently accessed responses from a centralized cache, without requiring each service to implement its own caching logic.
Because Entity Cache is integrated with the service mesh, services continue making the same HTTP or gRPC calls as before. Onboarding is done through service mesh configuration, so client and upstream service code do not need to change.
For example, a gRPC endpoint can be routed through Entity Cache with a config like this:
- name: example-service/grpc/50051
redirect:
enabled: true
entity_cache: true
endpoints:
- path: ^/example.v1.ExampleService/GetExample$
headers:
- name: :method
string_match:
exact: POST
rollout: 1By serving cached responses before requests reach upstream services, Entity Cache helps DoorDash:
- Improve latency by avoiding repeated cross-service HTTP/gRPC calls.
- Reduce upstream load by cutting repeated computation and backend database reads.
- Increase reliability by serving cached data when upstream services are slow or unavailable.
- Lower infrastructure cost by reducing unnecessary compute and database resource usage.
- Reduce engineering effort by providing a centralized cache instead of requiring each service to build its own caching layer.
Since launch, Entity Cache has been onboarded across many low-mutation Tier 0 and Tier 1 endpoints. It now serves over 1.5 million requests per second, achieves over 90% cache hit rates on many endpoints, and has become a platform-wide performance and reliability layer built on DoorDash’s service mesh foundation.
High-level architecture overview
Entity Cache deploys as a dedicated caching proxy that integrates with our Envoy-based service mesh. Client services do not change their code. As shown in Figure 1, the service mesh automatically routes outbound requests through Entity Cache first, with the upstream service configured as fallback. When a request comes in, Entity Cache checks if a valid cached response exists. If it does, that response is returned immediately; cache misses are forwarded to the upstream service, which generates a response that then is cached for future requests.
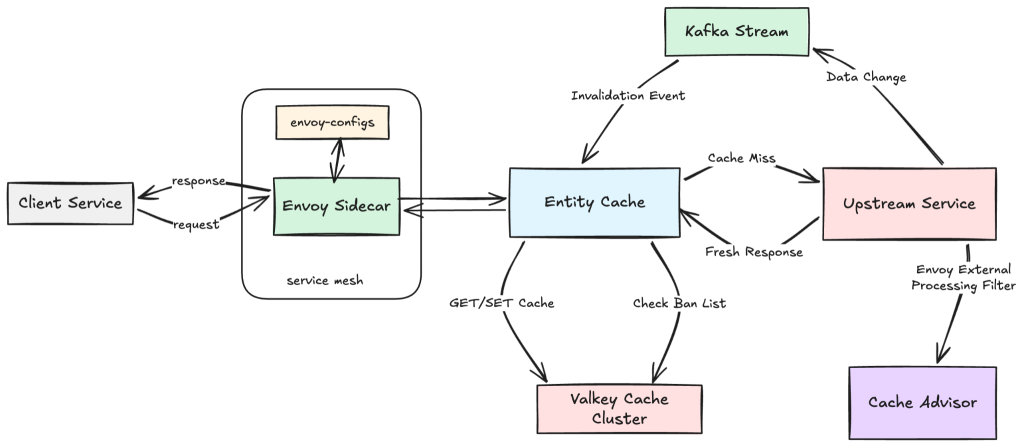
- Request path: Envoy routes requests to Entity Cache first, falling back to the upstream service if needed. On a cache hit, Entity Cache serves the response directly from Valkey, bypassing upstream dependencies. On a miss, it forwards the request to the upstream service, stores the response in Valkey according to the cache policy, and returns it to the client.
- Cache invalidation path: When underlying data changes, upstream services emit change events as part of their normal write workflows. These events flow through Kafka to Entity Cache. Instead of deleting cached entries across all instances, Entity Cache records that a specific entity was updated and notes the time of the update. On each request, Entity Cache compares the time the response was cached with the recorded update time. If the cached response is older than the update time, it is treated as stale. Entity Cache then fetches fresh data from the upstream service and updates the cache. This approach avoids complex distributed deletion while still ensuring updated data is reflected quickly.
- Traffic analysis path: Entity Cache continuously validates correctness using sampled production traffic. For a subset of requests, it compares cached responses with live upstream responses and computes divergence in the background. This validation mechanism ensures that caching remains accurate over time and provides the safety foundation for controlled rollouts. To support this, we built Cache Advisor, a separate service focused on identifying endpoints with low mutation rates that are strong candidates for caching. It runs independently at upstream ingress using Envoy’s external processing filter to observe request patterns and surface these opportunities.
- Automatic failover: Envoy automatically falls back to the upstream service if Entity Cache becomes unavailable.
Implemented features
Entity Cache is not a single optimization, but a collection of reliability and performance-focused features designed to work together at DoorDash scale. This section highlights the core mechanisms that make caching safe, predictable, and effective in production.
1. Graceful degradation with dual TTLs: As shown in Figure 2, Entity Cache uses two expiration thresholds: A "soft" time-to-live (TTL) that defines freshness —- for example, 60 seconds — and a "hard" TTL that defines the absolute maximum age — for example, five minutes. Under normal conditions, cached data refreshes according to the soft TTL definition. When upstream services become slow or unavailable, Entity Cache continues serving slightly stale data from cache rather than propagating errors to clients.
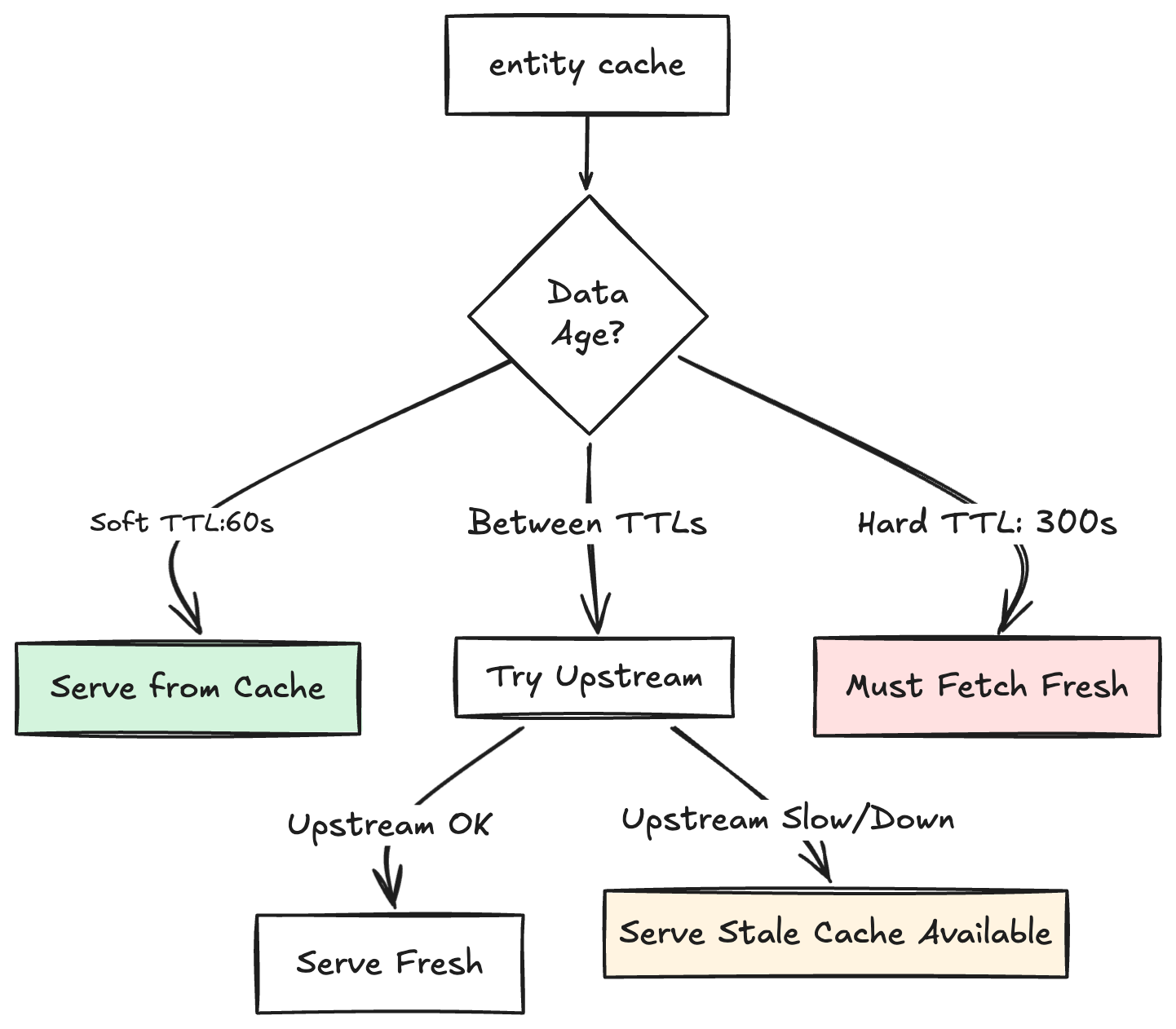
This design proved critical during a multi-hour upstream outage, when Entity Cache continued serving stale but valid cached data instead of failing, preventing a platform-wide incident.
2. Real-time cache invalidation with ban lists: Direct deletion in a distributed proxy fleet would require reconstructing cache keys, coordinating across pods, and handling race conditions where stale data could be written back immediately after removal. It also introduces memory overhead for tracking key associations. The timestamp approach avoids cross-pod coordination and remains correct even if events arrive out of order.
Caching traditionally forces a tradeoff between long TTLs for performance and short TTLs for consistency. Entity Cache addresses this with event-driven invalidation using a ban list. When underlying data changes, origin services publish an invalidation event to Kafka. An Entity Cache consumer records an invalidation timestamp in Valkey for the affected entity and identifiers. On a cache hit, Entity Cache checks this entry. If the cached object was retrieved before the invalidation timestamp, it is treated as stale and refreshed from upstream. Rather than deleting cache keys, the system relies on timestamp comparison. Each cached object stores its retrieval time; invalidation simply records a newer timestamp. This design allows endpoints to maintain long soft TTLs for high hit rates while still achieving near real-time consistency, with P99 invalidation latency targeted at about one second.
3. Envoy-based outlier detection — automatic failover: Entity Cache integrates with our Envoy-based service mesh. As shown in Figure 3, Envoy monitors cache pod health and automatically ejects unhealthy pods from the load balancing pool. If all cache pods become unhealthy, Envoy routes traffic directly to upstream services, ensuring availability even during complete cache failures.
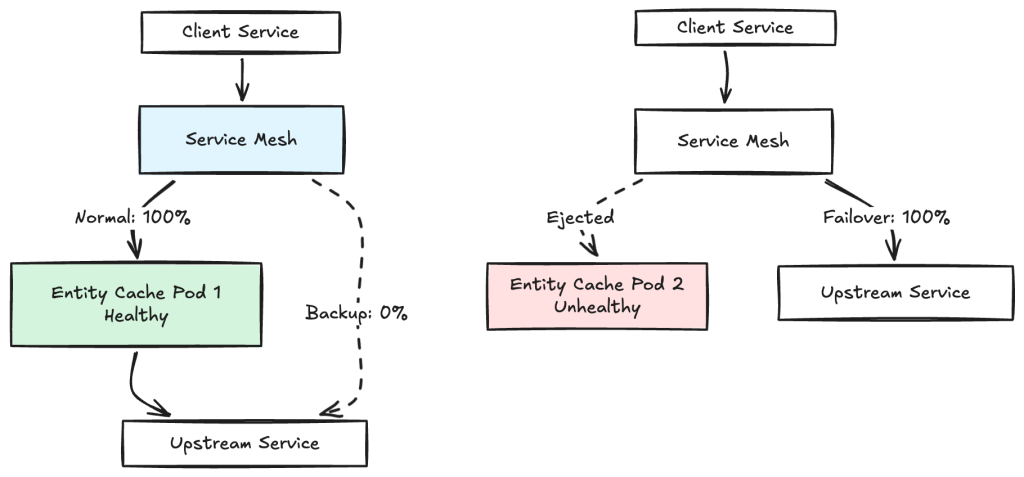
This automatic fallback design means Entity Cache adds resilience without introducing a new single point of failure. During onboarding, if a misconfiguration causes cache pods to crash, traffic automatically falls back to upstream. Teams can enable caching with confidence.
Scaling to millions of requests per second
Operating at millions of requests per second introduced system-level bottlenecks where small inefficiencies quickly amplified. Memory allocation, request coordination, and cache behavior all began to impact tail latency and upstream stability. To sustain performance, we focused on reducing contention, smoothing traffic patterns, and eliminating redundant work across hot paths.
- Memory management at scale: Frequent allocations on hot paths increased garbage collection (GC) pressure and caused latency spikes. We implemented custom buffer pooling to reuse memory and minimize allocations. This reduced GC overhead, stabilized memory usage, and lowered P99 request overhead latency to around 2.1 ms while maintaining consistent throughput.
- Cache stampede at scale: For hot entities, TTL-based expiration concentrated refresh traffic at a single point in time, creating spikes in upstream load. We implemented probabilistic early refresh based on the XFetch algorithm. As entries approach their soft TTL, each request has an increasing chance of triggering a refresh. This spreads traffic over time, reducing spikes and stabilizing upstream load.
- Concurrency at million-request scale: Concurrent requests often duplicated the same work, especially for connection setup and cache misses on hot keys. We introduced a single flight pattern using atomic, lock-free structures. Compare and swap ensures only one goroutine performs a dial or fetch per key, while others reuse the result. Deduplication happens per pod without cross-pod coordination. This eliminated redundant work and reduced contention. Per-pod throughput increased roughly five-fold, allocation rates decreased by 50% to 60%, and P99 latency spikes were reduced by up to 80%.
- Identifying what to cache: With thousands of endpoints, identifying strong caching candidates manually was not scalable.
We built Cache Advisor to analyze real production traffic and guide onboarding. Running at ingress via Envoy’s external processing filter, it samples requests, tracks response stability, and estimates update frequency. It recommends TTL values and surfaces strong candidates. This identified over 130 onboarding opportunities, enabling broader and safer adoption of caching.
User/business impact
Entity Cache has become a core reliability layer at DoorDash, now serving over 1.5 million requests per second with 99.99999% availability. More than 100 endpoints across 50 services have been onboarded, delivering measurable improvements across latency, scalability, and failure resilience.
From a performance perspective, Entity Cache adds minimal overhead while delivering substantial gains:
- P99 request overhead latency of approximately 2.1 ms
- Cache hit rate consistently above 90%
- 60% to 95% reduction in upstream requests during normal operation
- Up to 90% latency reduction for newly onboarded endpoints
- Even for services with local caches, end-to-end latency is often reduced by roughly half because of fewer cross-service network calls at client egress
Beyond performance, Entity Cache has materially strengthened platform reliability. During several production incidents, it prevented up to 90% of requests from reaching degraded upstream services. By serving stale but valid data when necessary, it has shielded services from upstream outages, eliminated stampede-driven amplification through probabilistic refresh, and reduced the blast radius of traffic spikes.
Continuous divergence monitoring enables safe adoption, giving teams confidence to enable caching without risking correctness. While infrastructure cost savings are a secondary effect, reduced upstream load also has lowered provisioning requirements and improved overall efficiency across the platform.
Next steps
- Dynamic traffic splitting based on error rate comparison: Today, traffic splitting between Entity Cache and upstream is based on static config. We are building dynamic traffic shifting that adjusts routing based on real-time error rate comparisons, sending more traffic upstream when cache health degrades, and shifting back as health improves.
- Noisy neighbor isolation per upstream cache cluster: Currently, all services share a single cache cluster. We're moving toward dedicated cache clusters per high traffic service to provide hard resource boundaries, preventing issues in one service from impacting others.
- Adaptive concurrency limiting: Static concurrency limits are suboptimal, either wasting capacity during low load or causing latency spikes during high load. We're implementing adaptive limiting that continuously measures system performance and automatically adjusts concurrency based on observed latency and throughput, maximizing capacity while maintaining latency targets.
Acknowledgements
Building Entity Cache was a collaborative effort across many teams at DoorDash. We would especially like to recognize the Core Infra team: Dakota Baber, Hochuen Wong, Yifan Yang, and Tejas Lodaya, whose contributions were invaluable to building, operating, and scaling the platform.
We are also grateful to Ivar Lazzaro, Muneeb Ansari, Karthik Katooru, Pushkar Raste, Matt Ranney, Thai Pham, Allen Meng, Madhav Gali, Jay Weinstein, Matt Zimmerman, and Sebastian Yates for their guidance, feedback, and support throughout the project.
