
Following our earlier engineering overview of Ask DoorDash, this second post in the blog series takes a close look at the intelligence behind the system. Deep dives on evaluation, platform, and user experience will follow.
Introduction
Agents reason in natural language. They plan, decompose tasks, call tools, and respond all through text. But to be genuinely useful, they need to know who they are talking to. Not just a user ID, but a structured understanding of preferences, constraints, habits, and history that persists across sessions and adapts over time.
At DoorDash, this was a key problem we wanted to solve as we started building agents to help consumers discover food, build shopping lists, and reorder groceries through Ask DoorDash, our agentic ordering experience. An agent that remembers your favorite stores, that you keep a well-stocked pantry, and that you prefer Oatly over other oat milk brands is qualitatively different from one that starts from zero every session.
Memory is the threshold that separates a useful agent from a merely impressive one.
We are already seeing that difference in production. Sessions backed by memory showed materially stronger outcomes: grocery-agent sessions converted to checkout basket at a ~24% higher relative rate, while open-ended restaurant-assistant queries converted at a ~15% higher relative rate vs. sessions without memory. Similarly sessions with this memory were ~33% less likely to misunderstand user intent, suggesting that persistent context helps reduce friction and keep agents better aligned with user expectations as measured by our LLM judge evals.
This post is a deep dive into the system that makes that possible for Ask DoorDash: our agent memory system. It connects our long-term memory platform with the agents that consume it, turning raw memory blocks into task-aware, relevant context for our agents, and feeding what those agents learn back into long-term storage.
Where this fits
Our memory platform maintains three complementary memory types, each optimized for a different timescale:

- Long-term memory synthesizes durable preferences from a consumer's behavioral history — cuisine tendencies, brand affinities, store loyalty, basket composition, and ordering cadence. This is generated offline in batch LLM pipelines at a specified cadence and organized into versioned memory blocks: Dietary Preference, Dining Patterns, Item Brand, Item Taxonomy, Store Preferences, Cross-Channel Patterns.
- In-session context captures real-time signals about current intent, such as cart contents, active searches, items viewed and rejected. This carries a recency weight such that what the consumer is doing right now overrides or supplements historical patterns.
- Conversational memory captures preferences a consumer states directly during a conversation. Unlike behavioral inferences that update gradually, explicit preferences are immediate and require explicit modification by the agent to change its understanding of the consumer’s preferences.
Our companion post covers how long-term memory is generated, organized into blocks with versioned components, and encoded into ML-ready representations through dense embeddings and a consumer context graph.
This post picks up downstream of that work, showing how the same memory blocks are served to live agents through the agent memory system, how the system turns the agent's task into a targeted query, and how it feeds what only a conversation can reveal back into long-term storage.
Three Core Gaps
Before diving into the architecture, it is essential to understand the core challenges of bridging memory generation and agent utilization.
| Problem Area | Description & Impact |
|---|---|
| Direct Connectivity | Our unified long-term memory system transforms engagement history into structured, LLM-friendly memory blocks. These include dietary preferences, taxonomy level brand affinities, cuisine tendencies, and lifestyle signals for example. For a user with hundreds of orders, this distills that into 100+ discrete facts, each formatted for LLM consumption. But producing memory blocks and actually using them in an agent are entirely different problems. The agent requires dynamic query planning based on the current task, hybrid retrieval across semantic similarity and structured filters, ranking to surface the most relevant facts, and precise injection into the prompt at the exact right time. |
| Task Awareness | Raw retrieval is necessary but not sufficient. Different tasks require fundamentally different memories. For example, when a user says "find a dinner spot," the agent needs cuisine tendencies, preferred price points, and recent order history; conversely, when they say "I want to make chicken tikka masala," the agent needs pantry inventory, portion sizes, and protein preferences. When the same user says "shop my usuals," the agent needs order history, replenishment patterns, and frequency signals. When they say "get me snacks," the agent needs brand affinities and dietary constraints. A naive approach would be to retrieve the top-K most similar memories for every request. This wastes context budget on irrelevant facts and misses critical ones that happen to not have high cosine similarity to the query. Context windows are finite and expensive. Every token spent on irrelevant memory is a token not available for the agent's actual reasoning. The agent memory system must understand what the agent is trying to do and shape retrieval accordingly. |
| Signal Loss | Perhaps the most underappreciated problem is that valuable signals from conversations routinely die with the session. A user often can casually mention preferences and constraints such as that they keep a well-stocked pantry, or have dietary preferences. These are durable facts that should persist, but in a system without explicit memory infrastructure, they evaporate when the session ends. Raw conversation logs do not work as long-term memory because they are noisy, duplicative, and unstructured. What is needed is a transformation pipeline: extract durable facts from ephemeral conversation, classify them by category and durability, deduplicate against existing knowledge, and write them back to long-term storage in a format that supports future retrieval. This is the conversational memory flywheel – better memory improves agents, and better agents surface more opportunities to capture memory. |
Architecture Overview
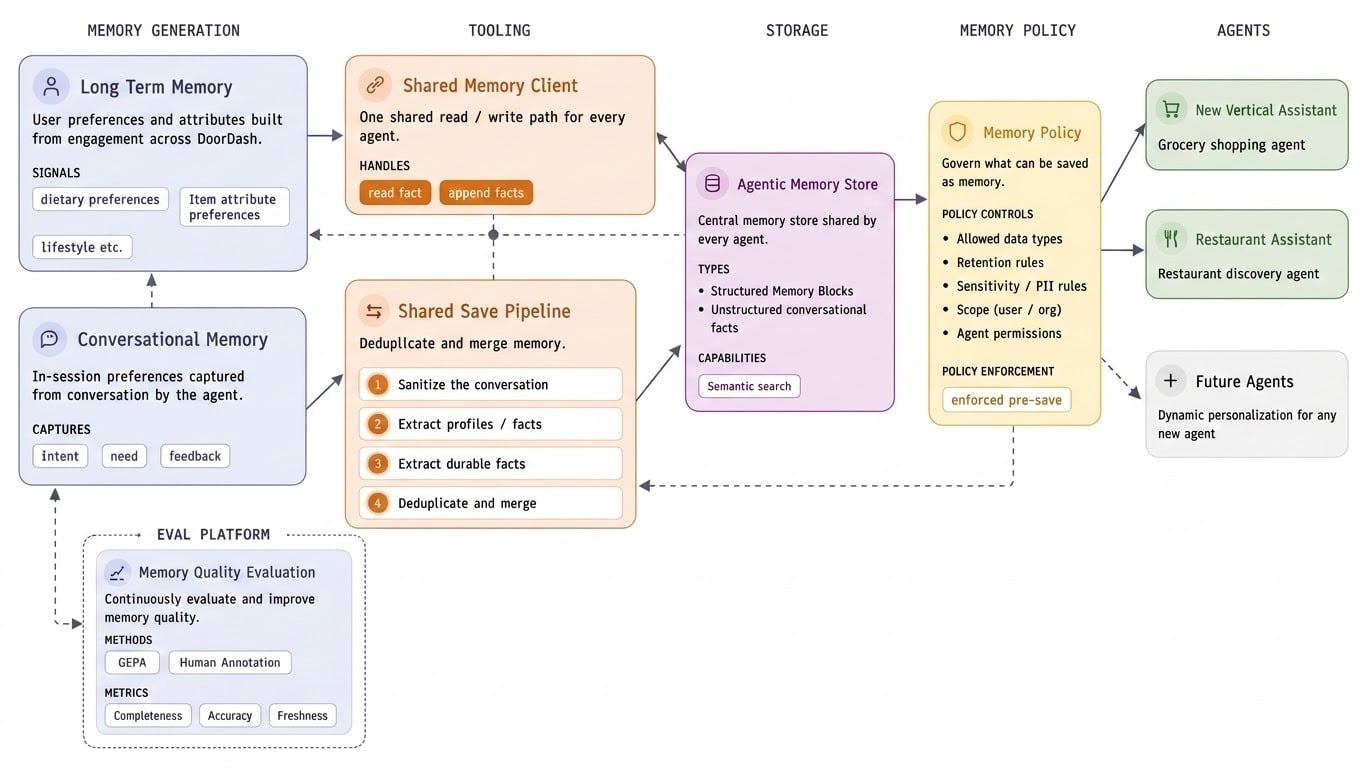
The system has three layers, each with a distinct responsibility:
- Long-Term Memory: The offline intelligence layer that transforms order history and behavioral signals into structured memory blocks. It runs batch pipelines over user data to transform order history and behavioral signals into structured memory blocks, producing facts like "prefers organic produce," "orders Thai food 3x/month," or "buys Oatly oat milk consistently".
- Managed Agent Services: Backed by distributed SQL storage with vector search capabilities. It stores memory blocks with their embeddings, supports semantic search via approximate nearest neighbor (ANN), and provides multi-tenant isolation through namespace partitioning. The persistence layer does not understand tasks or agents; it merely stores and retrieves.
- Tooling: The connective tissue of the system. It sits between generation and persistence on the write path (formatting and ingesting memory blocks) and between persistence and the agent on the read/write path (planning queries, retrieving, ranking, and packaging context). This layer is also where conversational memory extraction happens, turning transient agent interactions into durable knowledge that flows back into long-term storage.
Connecting Memory Generation to Serving
The Ingestion Pipeline
The long-term memory produces memory blocks as structured text, each featuring a concise header and supporting evidence. These blocks must reach our storage service in a format that supports both exact lookup and semantic search.
The pipeline has two paths, designed so that ingestion never blocks reads:
- Immediate Text Availability: Block content lands in storage instantly, making it available to agents with zero wait time for embedding computation.
- Asynchronous Embeddings: Each memory block is embedded via a message queue, decoupling ingestion throughput from embedding latency. The storage service supports dynamic server-side embedding at write time, which became our primary path. This flexibility allows us to swap embedding models without reprocessing the entire corpus, and ensures facts become searchable the moment they are written.
For bulk ingestion — when the offline pipeline processes millions of users in a single run — the system accepts pre-computed embeddings to maximize throughput. For real-time writes like conversational facts or profile updates, dynamic embedding keeps the architecture simpler and far more flexible.
Partitioning for Multi-Tenant Isolation
Memory is partitioned along two dimensions: signal type and consumer identity. Different signal types, such as brand affinities, taxonomy patterns, textual profiles, and conversational facts, live in strictly isolated namespaces. This guarantees independent scaling per signal type, clean access-control boundaries, and domain safety (e.g., ensuring a grocery agent querying brand preferences cannot inadvertently surface restaurant data).
However, some namespaces are deliberately shared. Durable cross-vertical facts like household composition, lifestyle signals, vegetarianism, or recurring habits, live in a unified namespace so a fact saved during a grocery order conversation is immediately available to other agents. The result is a memory surface that feels coherent to the consumer: the agent that learns the household cooks vegetarian is not the only one that remembers it.
Memory Orchestration for Agents
To the agent, the agent memory system surfaces as a set of simple, intuitive tools. From the agent's perspective, the interaction is simple: describe what you need in natural language, get back structured, relevant results. The system handles the four stage pipeline execution for the agent:
Intent and Scope Resolution
The first stage determines exactly what to query based on the task at hand. A recipe request triggers searches against brand and category preferences. A reorder request pulls from order history and replenishment signals. A restaurant discovery request reaches for cuisine tendencies, daypart, and price sensitivity. The resolver also manages freshness constraints, recognizing that some signals, like recent order activity, require a stricter recency floor than others, like long-stated lifestyle preferences.
Query Planning
The second stage translates the resolved intent into executable queries. Rather than relying on blunt semantic searches, the planner parameterizes each query along three distinct axes:
- Modality: Determines the search mechanism: semantic similarity over embeddings, deterministic keyword matching, or a direct structured fetch when the exact data slice is known a priori.
- Target: Scopes the search to specific namespaces or memory chunks.
- Filter Envelope: Establishes the boundaries by applying top-K limits, similarity floors, fact-category constraints, and strict recency windows.
Because strict post-filtering naturally drops candidates, the planner automatically over-fetches to guarantee the agent receives enough relevant facts to reason with, preventing context starvation.
Retrieval and Ranking
Search queries execute in parallel across memory partitions, designed for graceful degradation if any single source fails. Results are scored by semantic similarity, then merged and deduplicated. Recency signals break ties — between two equally relevant facts, the more recently confirmed one wins.
For some agent surfaces, semantic search alone is the wrong primitive. When the agent is reasoning about a shopping list and wants to look up specific brand or category preferences by name, deterministic keyword search is preferable: it offers lower latency, transparent scoring, and the agent already has the tokens it wants to look for.
To make keyword search usable in that mode, the system also exposes a Memory Bank Index, which is a compact directory listing of which tokens actually exist in each namespace for that user, injected into the system prompt once per session. The retrieval tool's description explicitly instructs the agent to anchor its patterns on this index. Searching for tokens that aren't in the index returns nothing, so guessing the user's vocabulary is a waste of tokens. The index serves as a grounding affordance: instead of asking the LLM to blindly guess what is stored, the system shows it the vocabulary footprint first.
Scan Before Read
For massive memory surfaces like order history or conversation logs, pulling full payloads immediately is too expensive for the context window. Instead, the memory tool exposes a scan action. The agent can execute a cheap, parallel directory check to get lightweight metadata (counts, availability, and summary categories) before deciding exactly what to read at full token cost.
Context Engineering
The final stage returns structured results ready for the agent to use. Each result carries its category, content, timestamp, and relevance score:
{
"fact_id": "mem_892a",
"category": "brand_preference",
"content": "Prefers Oatly oat milk",
"timestamp": "2026-05-12T14:23:00Z",
"relevance_score": 0.91,
"durability": "stated"
}The agent's task-specific instructions determine exactly how to use these results: as context for reasoning, as input to product search, or as strict exclusion criteria ("user has olive oil at home, skip it") via a skill-based prompt management system that defines expected behavior for different use cases.
Pluggable Across Agents
This unified set of tools works across different agents with fundamentally different needs. A grocery agent and a restaurant discovery agent register the exact same interfaces but receive vertical-aware behavior: different extraction rules, different retrieval sources, and different ranking signals. The tools are identical in shape, but fully adapted for different domains.
Stay Informed with Weekly Updates
Subscribe to our Engineering blog to get regular updates on all the coolest projects our team is working on
Please enter a valid email address.
Thank you for Subscribing!
The Conversational Memory Flywheel
Why Chat Logs Don't Scale
A single shopping session might produce 20 turns of dialogue, most of it transient, composed of fleeting search results, generic order confirmations, and raw tool responses. Buried deep within that operational noise, however, might be one or two durable facts worth keeping, such as a consumer mentioning they cook for a household of four or always shop on a budget. Storing entire conversation logs and running semantic searches over them later yields terrible signal-to-noise ratios that don't scale.
From Conversation to Knowledge
The conversational memory system bypasses this scaling trap using a three-stage asynchronous extraction pipeline:
- Signal emission. Immediately after a user turn completes, the agent initiates a tool call to execute a memory extraction job in the background. This process is entirely fire-and-forget, meaning it runs asynchronously and adds zero latency to the live user experience.
- Extraction and classification. A dedicated LLM evaluates the raw conversation to isolate durable facts from ephemeral chatter. The extraction prompt serves as a strict policy gate, enforcing explicit guardrails around what can be committed to long-term storage:
- Save vs. Don't Save: The model is instructed to capture explicitly stated, stable facts (e.g., household composition, brand preferences, recurring habits) while explicitly ignoring one-off requests, casual browsing behavior, or passing mentions.
- Domain-aware durability. The durability rules adapt by vertical. In a restaurant context, a user saying "I don't want ramen" is treated as transient unless they use explicit durability language like "always" or "never". Saving it without that signal would make the agent stop offering noodle dishes in the future because of a passing mood. In a grocery context, however, the rule flips: casually stating "I prefer Oatly" is exactly the kind of durable brand signal the agent is designed to capture.
- Active vs. passive intent. Preferences like price sensitivity are saved when the consumer initiates the framing, such as "What's cheap at Safeway?”, not when they merely accept a cheaper store the agent volunteered. Passive acceptance of an agent's suggestion is treated as a transient, not a durable signal, about the person.
- Deduplication and consolidation. Before writing new facts, the system searches for existing memories about the same topic. This prevents duplicates, merges overlapping facts, updates refined preferences in place, and resolves contradictions by removing outdated entries.
Forgetting Carefully
Forgetting data safely is a significantly harder system problem than remembering it. If a user tells the agent to "forget that I prefer Nova's grilled cheese," a naive vector similarity threshold or a loose substring match risks over-deleting adjacent, valuable memories regarding "Nova" or "cheese".
The implementation is two-stage. First, a semantic search on the deletion query gathers a candidate set. Second, a separate LLM call receives the candidates and the original natural-language deletion request, with explicit instruction not to remove facts that are merely related but do not match. The model returns the indices to delete; everything else stays. Selected deletes execute in parallel. Unlike save (fire-and-forget), delete is synchronous so the agent can confirm in its reply exactly what was forgotten.
Memory Has a Lifecycle
Not all facts are equal. Stated dietary self-descriptions (e.g., vegan, vegetarian, gluten-free) change rarely. Food preferences evolve slowly. Ordering patterns are seasonal. Pantry staples get consumed and replenished on a timescale that varies by item.
The principle is that a fact's lifecycle is a function of what it is about, not a uniform decay applied across the store. A blanket "all facts older than X are stale" wastes durable signal (cooking oil purchased eighty days ago is still in the pantry) and over-trusts ephemeral signal (milk purchased twelve days ago is gone). Stated lifestyle preferences carry no TTL and they persist until the consumer says otherwise.
The Compounding Loop
The flywheel works because better memory produces better agent behavior, which produces more opportunities to capture memory. When an agent accurately captures a fact like portion size, it can proactively auto-scale recipe quantities in a future session without prompting the user. This frictionless experience builds user trust, which drives deeper engagement. Deeper engagement inherently surfaces higher-quality conversational signals, feeding more structured facts back into the long-term store and continuously accelerating the personalization loop.
Early Measures of Impact
To validate our agent memory system beyond qualitative "magic moments," we analyzed early production data over a representative seven-day window, comparing sessions backed by consumer memory against a baseline with no computed memory. While these initial metrics reflect an early rollout snapshot rather than long-term longitudinal trends, the directional data demonstrates a clear improvement for our early users. For the grocery agent, utilizing a full memory profile drove a ~24% higher relative checkout conversion rate, a ~17% increase in average basket size, and a ~7% reduction in conversational turns, indicating that the system surfaces the correct products faster when it avoids starting from zero. Similarly, the restaurant assistant achieved a ~15% higher relative conversion rate on open-ended queries, a surface where personalized alignment is uniquely critical.
Crucially, our quality evaluations revealed that operating without this system introduces significant user friction; baseline sessions with memory were ~33% less likely to misunderstand user intent and ~24% less likely to generate egregiously irrelevant results. Although these are early performance indicators, the consistent margin of improvement across both transactional and quality metrics validates our core architectural thesis. Structured long-term context provides a critical technical baseline required to keep live agents accurate, efficient, and aligned with user expectations over time.
Lessons Learned
Memory Changes the Quality Bar
The "magic moments", such as remembering user’s pantry staples, auto-scaling recipes for preferred portion sizes, or surfacing the right brand without being asked, provides concrete validation that long-term memory changes the quality of agent interactions. Users with accumulated memory across sessions received measurably more relevant responses. Hence memory isn't a nice-to-have. It's the threshold that separates a useful agent from a merely impressive one.
Knowing What to Leave Out
One of the non-obvious lessons: exclusion is often harder than inclusion. A user with 100+ memory blocks and a finite context window needs aggressive pruning. Including irrelevant facts doesn't just waste tokens, it actively degrades the model's reasoning. We saw this directly: too many competing facts injected at once caused the agent to start dropping instructions.
The pantry staple workflow is a good example. Instead of adding pantry items to the shopping list and letting the user remove them, the agent proactively excludes items the user already has at home. Getting this right required task-aware retrieval, not just pulling the most similar facts, but understanding which facts actually matter for the task at hand.
Personalization as a Tool
When building a memory layer for AI agents, it is easy to fall into the trap of designing for the first immediate use case. But treating memory as an agent-specific feature forces every subsequent team to independently solve the same fundamental problems: query planning, context budgeting, extraction, and deduplication.
By treating it instead as a tooling layer, it decouples memory orchestration from the specific agent runtime, creating an infrastructure pattern that is highly generalizable across multiple agents.
Embedding Strategy Evolution
We evaluated three approaches for our vector pipeline: pre-computed static embeddings, server-side embedding at write time, and query-time embedding. We initially launched with static embeddings to optimize read latency, but ultimately migrated to dynamic server-side embedding as our primary production path.
The deciding factor was architectural flexibility. Static embeddings freeze your model choices at ingestion time; upgrading your embedding model forces you to reprocess your entire historical corpus. Moving embedding computation server-side allows us to swap models transparently, makes new facts searchable the instant they land with no separate synchronization pipelines to monitor, and keeps our data layer highly maintainable.
Conclusion
Personalization for AI agents is a requirement from the start. However, the gap between having user data and actually using it in a live agent is wide and requires careful design.
The agent memory system provides three things: an ingestion pipeline that connects offline user intelligence to agent accessible storage, an orchestration layer that turns raw retrieval into task aware context delivery, and a conversational memory system that transforms ephemeral session signals into durable memory that improves feedback loops.




