

At DoorDash, our software engineering internship program is designed to be immersive and impactful. Software engineering interns don’t just observe - they are embedded into our Engineering teams, contributing to meaningful projects that our Dashers, merchants, consumers, and internal employees use. This post is part of a 4-part series highlighting the innovative work from our Summer 2025 interns - check out Part 2 and Part 3. Their projects demonstrate not only strong technical and problem-solving abilities but also how fresh perspectives can help shape the future of innovation at DoorDash.
In-house DoorDash Language Model Automates Never-Delivered Order Feature Extraction
By: Anning Li
A never-delivered designation, or ND, occurs when a customer reports an order was not received, despite the Dasher marking the order as delivered. With about 2 billion orders annually through DoorDash, every ND order can negatively impact overall revenue and user trust.
Historically, each ND was reviewed manually by reviewing conversations between Dashers and consumers — a slow and expensive process. Instead, we developed a custom in-house language model that automatically extracts key features from these conversations, accelerating the review process and improving our downstream attribution model.
ND review workflow
Given the volume of deliveries each day, it’s not easy to figure out why an order would become ND. Possibilities range from a consumer’s mistake or an issue with a Dasher to potential fraud. Before we implemented our model, agents had to review everything manually, as shown in Figure 1.
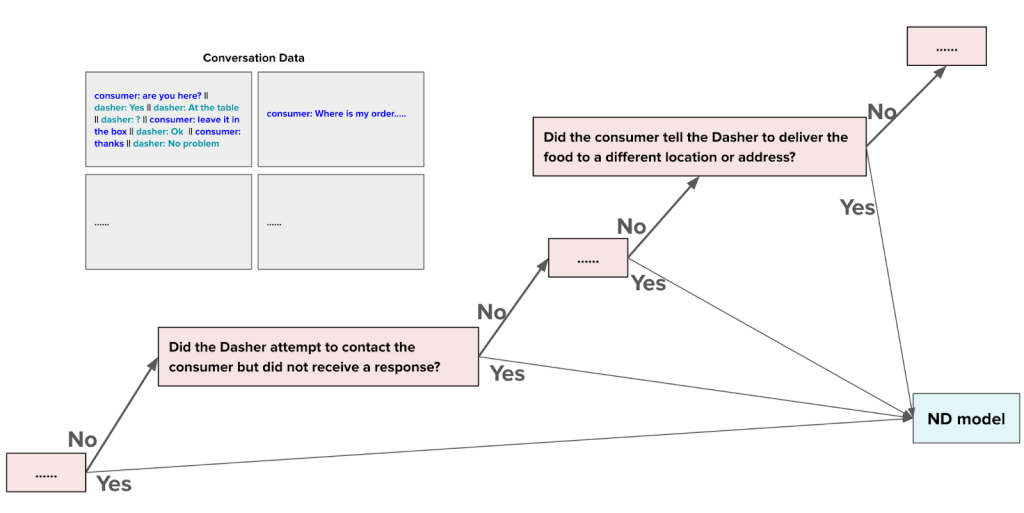
Our language model automates this general pipeline, starting with the communications between the Dasher and the consumer. Based on this input, the model steps through the resolution process, predicting viable answers at each juncture. Answers are passed as a feature to the downstream ND model. Currently, this labeling process is performed manually by customer support agents, a slow process that limits resolutions to just a few cases each day. Through automation, agents can instead focus on more complex tasks, rather than repetitive case reviews.
Dealing with data imbalance
One of our major challenges was data imbalance. For example, only about 1% of ND orders had a “yes” response to the question “Did the Dasher attempt to contact the consumer but did not receive a response?” Because these cases were so rare, the model lacking data balancing would simply ignore this question, always predicting "No" rather than allowing for that rare “yes” response. To address this, we oversampled the rare “yes” cases to ensure the model paid attention to the question. We also used the F1 score as our main evaluation metric to better balance precision and recall. These changes made our model much better at recognizing those rare but important situations, helping us achieve higher accuracy and fairer results.
Automating feature extraction with in-house LLMs
We built a lightweight, in-house language model to extract key features from conversation dialogues and to automate the labeling process. This enables rapid backfilling and helps the ND model improve over time. We compared several models, including a fine-tuned Meta Llama 3 model and our custom-trained DistilBertForSequenceClassification. Although general-purpose reasoning models like Llama 3 are powerful at understanding and generating text, its performance was limited for our specific classification problem — deciding whether certain events in the conversation happened or not. Because we wanted precise and consistent classification, a specialized model like our fine-tuned DistilBertForSequenceClassification was much more accurate and reliable, especially after addressing data imbalance. As shown in Table 1 below, our in-house model achieved auto-labeling with the highest F1 score.
| Model | Precision | Recall | F1 Score | Accuracy | Latency (s) |
| llama3-70b | 0.4857 | 0.6071 | 0.5397 | 0.9555 | 0.3067 |
| finetuned-llama3-70b | 0.5122 | 0.7500 | 0.6087 | 0.9585 | 0.3275 |
| llama3-8b | 0.3889 | 0.2500 | 0.3043 | 0.9508 | 0.1555 |
| finetuned-llama3-8b | 0.4444 | 0.4286 | 0.4364 | 0.9524 | 0.3075 |
| finetuned-DistilBertForSequence Classification | 0.7917 | 0.6786 | 0.7308 | 0.9785 | - |
| finetuned-DistilBertForSequence Classification (with balanced data) | 0.8630 | 0.7975 | 0.8289 | 0.9870 | 0.0936 |
The following is a live example of the model at work:
| Question: Did the consumer ask the dasher to deliver to a different location? Conversation: consumer: I put in the wrong address || dasher: Hi || dasher: what are you saying? || consumer: <consumer address> that's the right place || consumer: Can you deliver it to here || dasher: Ok || consumer: Okay || consumer: Are you coming to the new address? || dasher: Yes Inference time: 0.159 seconds Prediction: [1] |
In this case, the language model processed reasoning in 0.159 seconds and correctly predicted that, yes, the customer did change the delivery location. This example shows how quickly our automated model can find key details in real customer conversations. By automating this feature extraction process, we can reduce investigation costs and speed up response times.
Next steps
The project will now focus on making the pipeline generic so that it can extract any features within the workflow. The same pipeline can be adapted to extract a wide variety of features, including address change requests, requests for delivery experience signals, item issues, or any other custom signals from different parts of the ND workflow. Automation speeds response times and allows DoorDash customer support agents to focus on high-priority and more complex tickets.
Conclusion
We have demonstrated that automating feature extraction for ND orders using language models can speed investigations and reduce costs through eliminating formerly manual processes. In the future, this work can expand to automate answering a wide range of questions accurately using any customer conversation.
Building DoorDash’s scalable knowledge base and chatbot as a service
By: Rakshit Kadam
Chatbots play a critical role at DoorDash in addressing a wide range of Consumer and Dasher needs - from answering frequently asked questions to resolving support issues and surfacing timely information. As adoption increased across teams, two major limitations became apparent:
- There was no centralized, scalable platform to manage knowledge bases (KBs).
- Teams lacked a unified API to easily create and deploy their own chatbots, as no plug-and-play infrastructure existed.
Previously, teams stored article embeddings in a vector database, while managing metadata separately in spreadsheets. This meant they had to first locate an article in the spreadsheet and then use its associated ID to query the vector database - a workflow that was both error-prone and unscalable. To address the challenges of fragmented article management and the lack of reusable chatbot infrastructure, we built a centralized Knowledge Base Management Service and a generalized Chatbot-as-a-Service.
This unified system empowers any DoorDash team to quickly launch a chatbot powered by a Retrieval-Augmented Generation (RAG) framework, offering:
- Automated ingestion, embedding, and retrieval of knowledge base articles
- Isolated, schema-flexible collections and customizable embedding models per bot
- Prompt-driven, context-aware answer generation via the GetRagResult API
- A reusable chatbot interface compatible with any RAG-based system
- Standardized onboarding and seamless integration across teams
- Configurable bot behavior for both successful retrievals and fallback scenarios (when no relevant answer is found), enabling distinct personalities and tailored responses
Knowledge base management service APIs
This set of APIs enables teams to manage and evolve their KBs independently. Each bot receives a dedicated collection, allowing for schema flexibility and embedding model customization.
- UpsertArticle: Adds or updates an article in a specific collection. Automatically generates embeddings using the specified embedding model provider and stores additional metadata, including the embedding configuration, in the vector database.
- GetArticle: Retrieves a single article from a collection using its ID.
- ListArticles: Returns a filtered, paginated list of articles by applying exact-match filters on any article attributes or metadata.
- DeleteArticle: Deletes an article and its embedding from the vector store.
- ReembedCollectionWithNewModel: Re-embeds articles using a new embedding model. This API accepts a source embedding model, a target embedding model config, a source collection, and a target collection as input. It filters for articles in the source collection that were embedded with the source model as identified via stored metadata. Matching articles are then re-embedded using the new model and upserted with the same ID via UpsertArticle. If the source and target collections differ, the original articles are deleted after migration.
API for chatbot-as-a-service
The GetRagResult API enables any team to deploy their own RAG-based chatbot using shared infrastructure. Each bot operates within an isolated collection, ensuring schema independence and allowing for customizable embedding logic. Executing the full RAG workflow, the API retrieves relevant knowledge base articles, combines them with the user’s conversation history and a customizable prompt, and generates a context-aware response.
In addition to the generated reply, the API also returns a list of referenced articles used during the retrieval step, providing transparency and enabling features such as guardrails or audit logging. Teams can define their own prompt templates, allowing for tailored bot behavior and responses specific to their use case.
Onboarding new bots to the platform
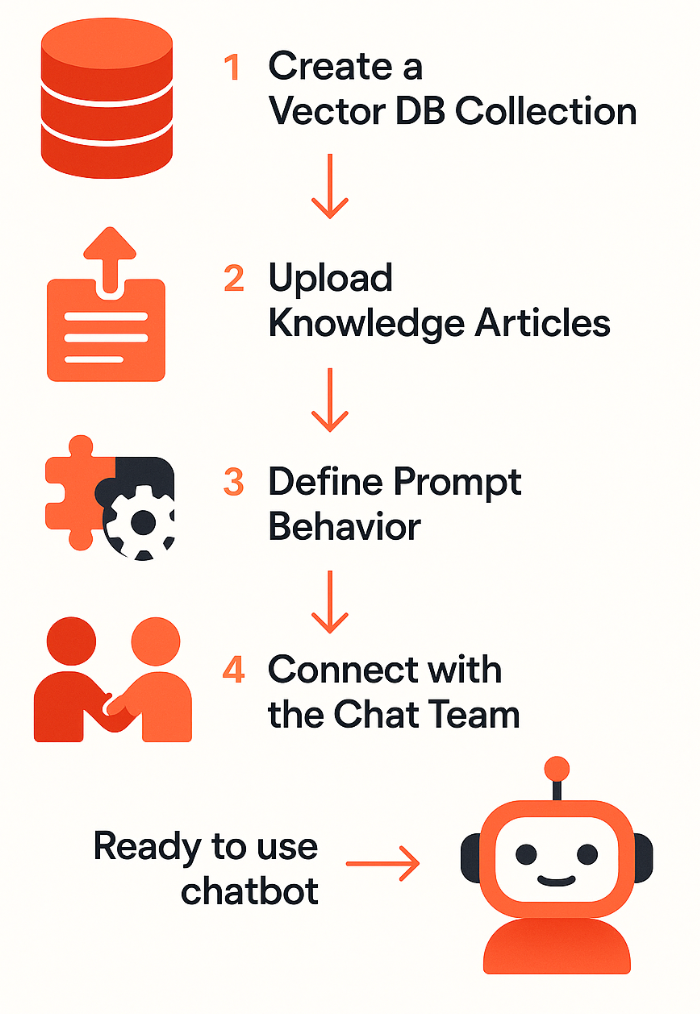
Our platform provides a simple, self-serve onboarding flow that enables any team to launch their own RAG-powered chatbot in just a few steps, as shown in Figure 1:
- Create a vector DB collection: Each bot is provisioned with an isolated collection, ensuring schema flexibility and support for future model customization.
- Upload knowledge articles: Teams upload their content through the knowledge base management API. The platform automatically handles embedding generation and metadata storage, streamlining the entire ingestion process.
- Define prompt behavior: Teams configure how the bot should respond both when relevant knowledge is retrieved and when fallback behavior is needed. This allows for the creation of distinct bot personalities and responses tailored to specific scenarios.
- Connect with the Conversation team: The team shares the intent and prompt configuration with the Conversation team. The intent serves as a lookup key used by the GetRagResult API to fetch the appropriate prompts at runtime. Once registered, the bot is ready to deliver responses aligned with its use case.
After following these steps, the team is ready to use their chatbot in production.
Impact and future direction
This system currently powers our Dasher-facing assistant and is designed to support many more bots across the company. It significantly reduces the time required to deploy new chatbots and simplifies ongoing content updates by offering centralized infrastructure and standardized tooling.
Looking ahead, we plan to expand support for using different embedding models per bot and introduce a user-friendly UI for the knowledge base management system, further empowering teams to manage and iterate on their content with ease.
Conclusion
By building a centralized knowledge base management system and a reusable chatbot backend, we’ve laid the foundation for scalable conversational interfaces at DoorDash. Teams can now manage knowledge more efficiently, onboard chatbots faster, and reuse a common framework that accelerates development across the organization.
DoorDash agent support tool built on server-driven UI
By: Rakhi Chadalavada
DoorDash’s frontline agent support tool is used in hundreds of resolutions each week to assist consumers and Dashers. Its interface plays a critical role in delivering key insights, such as account flags or special instructions, to support agents in providing fast and accurate assistance.
What is SDUI?
Server-driven UI, or SDUI, is a design pattern in which a user interface’s structure and content are defined on the backend, rather than hard-coded into the front-end application. Instead of requiring a new app deployment every time the UI changes, the front-end simply renders what the server tells it to display, often using a predefined set of reusable components.
The support tool’s banners and tags are tightly coupled to front-end logic. Any change, new banner, or tag logic update requires code changes and engineering bandwidth.
To solve this, we built a fully backend-powered solution using DoorDash’s Mosaic server-driven UI framework. With a new library to do this, we allowed the UI to be coupled with logic, streamlining the backend-to-frontend process to enable config-driven updates, faster launches, and smoother workflows.
By introducing an SDUI approach using the Mosaic framework, we built a fully backend-configurable system that allows teams to launch new banners and messages without needing front-end code changes.
Why traditional UIs were holding us back
Before SDUI, the content — including banners and tags — was defined in both front-end and back-end code. This dual dependency meant:
- Slow iteration: A new banner could take two to three days to ship.
- Multi-team friction: Even small updates needed coordination with engineers.
- Lack of agility: Ops and Product couldn’t own or test their messaging without engineering help.
But for efficient customer support, timely and personalized insights are critical!
The Solution: Server-driven UI in the tool
We introduced thq-sdui, a backend library that generates fully hydrated Mosaic configurations for banners and tags. Its key features include:
- Context-driven display: Banners are rendered based on request context such as delivery UUID or customer ID, allowing for dynamic targeting.
- Centralized configuration in Asgard: All logic lives in thq-sdui, eliminating redundant logic across systems.
- Hydrated views served via SPP: We use DoorDash’s self-help presentation platform to serve Mosaic JSON payloads to the front end, which renders them instantly, requiring no deployment.
Architecture overview
As visualized in Figure 1, the end-to-end flow begins with the Product or Ops team writing structured config files. These configs are ingested by thq-sdui, which generates Mosaic UI layouts. The front-end app then requests these views dynamically and renders them immediately.

Impact: Faster development and smarter support
As shown in the table, switching to SDUI brings immediate benefits, including reducing the time to deliver new banners and tags to under a day and delivering modifications in less than an hour.
| Task | Before SDUI | After SDUI |
| Add a new banner/tag | 2-3 days | <1 day |
| Modify banner/tag logic | 1 day | <1 hour |
| Coordinate multi-team change | Needed | Not Needed |
Looking ahead
SDUI’s success with banners and tags is just the beginning. The future roadmap includes:
- Making structured config interfaces accessible to non-engineering teams.
- Extending SDUI to other components, such as widgets and smart modules.
- Piloting LLM-generated flows for common use cases using pre-defined templates.
Conclusion
With thq-sdui, we’ve taken a big step toward making DoorDash’s platforms more dynamic and efficient. This project set the foundation for scalable, backend-powered UIs throughout WHAT?.
Acknowledgments
Huge thanks to my mentor Vikas Jindal and the entire Teammate Experience teams — especially Abhinav, Aman, Harim, Kevin, Leo, Matt, Zac, Karen, Timothy, Wanning, and Han — for their support, feedback, and collaboration throughout the summer. Shoutout to the Self-Help team as well. And to everyone at DoorDash and the university program, thank you for making this such a rewarding summer!
Redesigning the annotation pipeline for store-level tags
By: Riley Phan
Store-level tags such as “Japanese,” “seafood restaurant,” or “pizzeria,” are essential metadata within DoorDash. They not only help merchants enhance visibility but also shape the customer experience across search, discovery, personalization, order experience, and ads. Until recently, however, DoorDash’s pipeline for tagging stores suffered from quality gaps and lacked observability, leading to incorrect or missing tags and, ultimately, a potential revenue loss and reduced access to the total addressable market.
My project redesigned the tag annotation pipeline using a Kafka consumer and Cadence workflow orchestration, backed by a single source of truth in CockroachDB. This architecture improves reliability, observability, and tag delivery performance for millions of DoorDash’s merchant partners.
Legacy challenges
The original tagging pipeline was built atop a fragile extract, transform, and load (ETL) process that was heavily reliant on complex SQL queries and nested joins across disparate tables. This introduced two key problems:
- Complex joins can break and cause mismatches or incomplete data, resulting in 500 to 1,500 unusable or missing tags weekly.
- A flawed tag selection heuristic that uses a majority-voting mechanism to resolve conflicting annotations may not cover all edge cases, such as unclear majority or missing store information. For example, if two annotators voted incorrectly and labeled the Olive Garden restaurant as “Italian,” but another annotator voted correctly for “American,” the system could favor the wrong vote without accounting for annotator reliability.
Implementation
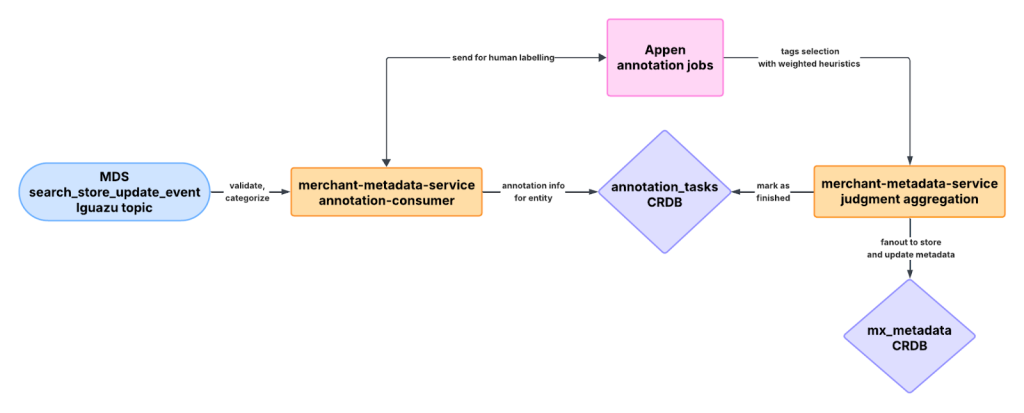
The annotation pipeline, as shown in Figure 2, was rebuilt using two core components:
Kafka-based tag ingestion
To simplify the complications inherent to an SQL-drive ETL, I developed a Kotlin-based Kafka consumer, following the controller-service-repository architectural pattern for better maintainability and scalability, shown in Figure 3. This annotation consumer residing in the metadata service performs preliminary validations and categorizations for tag-worthy store update events before ingestion. After tags are extracted from protobuf events, they are cross-referenced against a curated label list and existing store metadata for filtering and deduplication. The final payload, enriched with business metadata, is compiled into a data access object and sent to Appen for annotation, then stored in a dedicated annotation CRDB. This table serves as a single source of truth (SOT), eliminating redundant checks and manual validations for all annotation tasks.
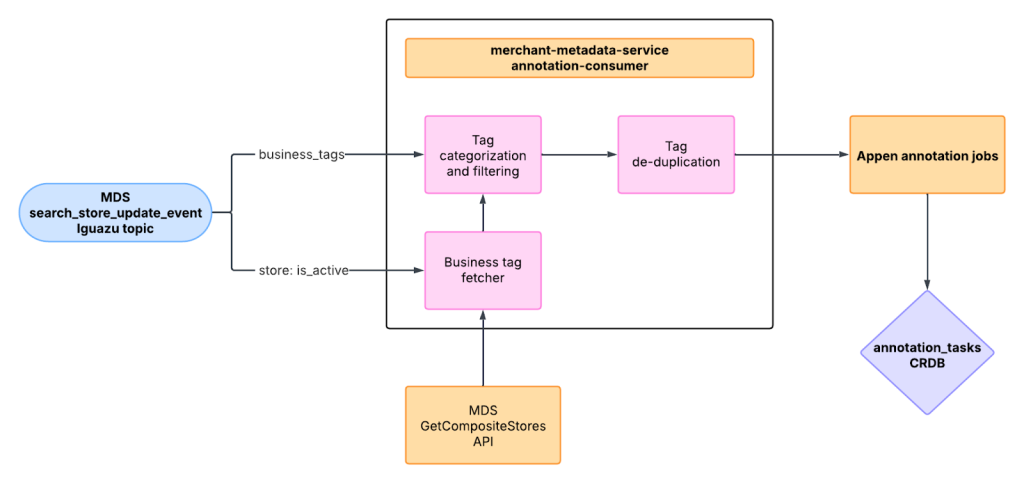
Cadence workflow result processing
Figure 4 illustrates the architecture of the result processing pipeline. Doubling down on CRDB as an SOT for business annotation details, I built a Cadence workflow, triggered by the job scheduler cron every two hours, to query for in-progress tasks from the annotation table. Our annotation service then calls GET requests to Appen to check for results, processes gathered judgments, and fans out to all active stores that belong to the task’s business ID.
The most interesting part of our annotation service is how we chose to handle tag selection. Appen's default approach aggregates annotations once a reviewer's trust score passes a threshold. We decided to take this further: instead of letting the platform's algorithm decide, we pull the trust scores for every annotation and compute the most likely correct answer ourselves. By reusing reviewer ratings and auditing patterns as weighted signals inside our pipeline, we've turned what was once a blunt mechanism into a more reliable and nuanced decision process.
As the diagram below shows, the final store tags are populated with path IDs to connect them to the DoorDash food knowledge graph and then upserted into the metadata database, which powers search and the homepage.
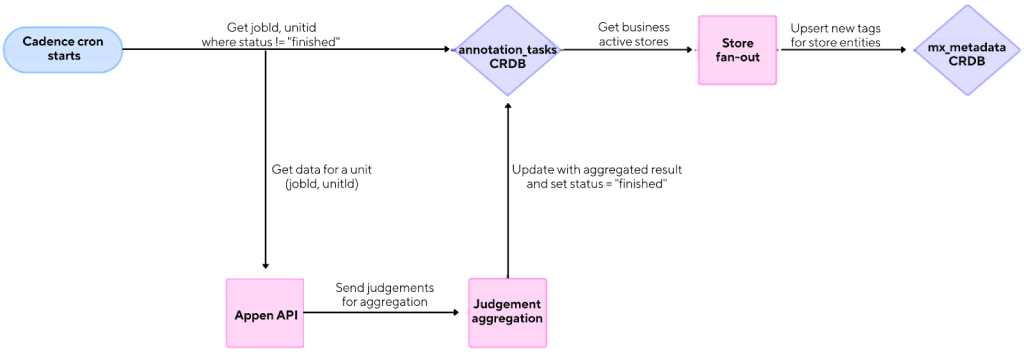
Outcome
As long as the Kafka topic polls and publishes new messages, the service’s end-to-end pipeline ensures smooth automation of tag ingestion, processing, annotation, and judgment of aggregation, preparing everything for display on the store page.
The processor takes in an average of one to two requests per second, with a P99 latency of three seconds, the bulk of which falls on external HTTP requests to Appen. Despite the external dependency, we observe over 1,000 new records in our CRDB that accurately account for Appen units with complete business metadata. Deduplication also ensures that previously seen and stored tag metadata are not re-sent, minimizing redundant annotations and reducing load on downstream services and storage systems.
Initial testing on the Cadence workflow also shows promising results in both stability and effectiveness. Integrating Appen's annotator trust scores with the selection logic demonstrates higher accuracy and resilience against noisy annotations; all test values return desirable results. Additionally, early metrics indicate that the pipeline maintains consistent throughput and latency across varying load conditions, further validating the decision to use Cadence as the orchestration framework. Its support for stateful, long-running workflows will be instrumental in reliable scaling of the annotation process.



