

En el vertiginoso mundo de la entrega de alimentos, las predicciones precisas de la hora estimada de llegada, o ETA, no son sólo una comodidad; son un componente crítico de la eficiencia operativa y la satisfacción del cliente. En DoorDash, donde gestionamos más de 2.000 millones de pedidos al año, el reto de proporcionar ETA precisas es a la vez complejo y esencial.
Tradicionalmente, hemos confiado en modelos basados en árboles para prever los plazos de entrega. Aunque estos modelos producían previsiones razonables, también eran limitados en su capacidad para captar los intrincados patrones y matices inherentes a nuestra vasta y variada red de entregas. A medida que nuestras operaciones se ampliaban y las expectativas de los clientes evolucionaban, reconocimos la necesidad de un enfoque más sofisticado.
Nuestra última innovación: Un modelo de predicción de ETA de vanguardia que aprovecha técnicas avanzadas de aprendizaje automático para mejorar drásticamente la precisión. Aprovechando una arquitectura de mezcla de expertos activada por Perceptrón Multicapa, o MLP activada por MoE, con tres codificadores especializados (DeepNet, CrossNet y transformer), hemos creado un modelo que puede adaptarse a diversos escenarios y aprender relaciones complejas a partir de incrustaciones y datos de series temporales para capturar patrones temporales y espaciales. Además, nuestro nuevo enfoque también incorpora el aprendizaje multitarea para permitir que el modelo prediga simultáneamente múltiples resultados relacionados. Por último, exploramos nuevos enfoques de modelización probabilística para ampliar la capacidad del modelo de cuantificar con precisión la incertidumbre de las previsiones de ETA.
¿El resultado? Una notable mejora relativa del 20% en la precisión de las ETA. Este salto adelante no sólo mejora nuestra eficiencia operativa, sino que también aumenta significativamente la fiabilidad de las ETA que proporcionamos a nuestros clientes.
Tenemos una entrada anterior en el blog que profundiza en el contexto empresarial y el espacio del problema. En esta entrada, profundizamos en los detalles técnicos de nuestro nuevo sistema de predicción de ETA e ilustramos cómo cada componente contribuye a su éxito, así como el impacto de este nuevo enfoque en nuestro negocio y en la experiencia del usuario.
¿Qué es ETA?
Antes de entrar en los detalles de la modelización, echemos un vistazo a la hora de llegada que intentamos estimar.
Hora de llegada = Hora de creación del pedido + Duración de la entrega
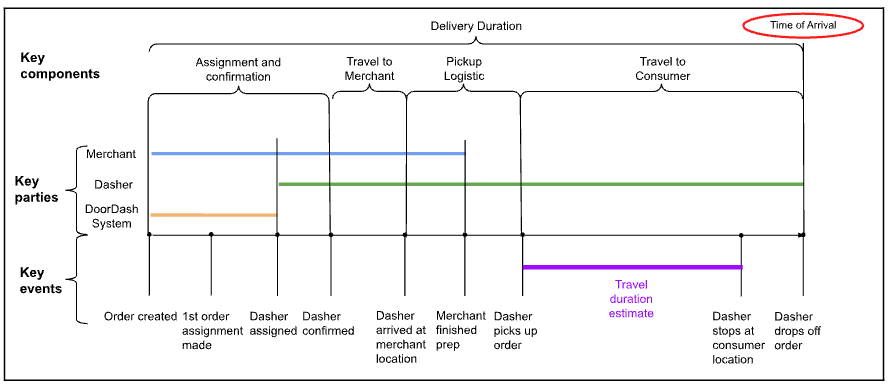
Figura 1: Las distintas fases de la entrega, desglosadas por etapas y partes implicadas
En la figura 1, arriba, podemos ver los componentes que contribuyen a la duración de la entrega de un pedido normal. Incluso en los casos más sencillos, hay al menos tres partes clave: el comerciante, Dasher y el sistema DoorDash. También podemos desglosar la duración de la entrega en varias etapas: Asignación y confirmación de Dasher, viaje al comerciante, logística de recogida y viaje al consumidor. Dadas las distintas partes y etapas, un cambio en cualquiera de ellas puede introducir variaciones en el tiempo de entrega real, lo que nos obliga a utilizar herramientas más capaces para abordar la predicción.
Incrustaciones y series temporales
La ingeniería avanzada de características constituye un componente crucial de nuestro modelo mejorado de predicción de ETA. Aunque mantuvimos algunas de las características existentes, también aprovechamos las incrustaciones de redes neuronales para representar entradas continuas categóricas o bucketizadas, e incorporamos características de series temporales, mejorando significativamente la capacidad de nuestro modelo para captar patrones y relaciones complejas.
Incrustaciones para una rica representación de rasgos
Observamos fuertes señales predictivas en características categóricas con alta cardinalidad. Por ejemplo, hay muchas tiendas en la plataforma DoorDash y algunas -por razones específicas de la tienda, como el tipo de cocina, la popularidad de la tienda o la eficiencia- tienen un tiempo de preparación de la comida más largo que otras. Además, los patrones de tráfico de los restaurantes cambian a lo largo del día y las horas de las comidas atraen a las mayores multitudes, lo que aumenta la duración de la entrega.
Hemos utilizado métodos de codificación de características para capturar patrones basados en categorías, como la codificación de una sola vez, la codificación de objetivos y la codificación de etiquetas. Otros métodos de codificación no son adecuados para captar los patrones de cada categoría porque requieren un esfuerzo manual que a menudo provoca la pérdida de relaciones semánticas. Por ejemplo, es difícil que el modelo ETA aprenda las similitudes entre dos restaurantes de comida rápida cuando se comparan con otros tipos de restaurantes.
Para resolver estos problemas, introdujimos la incrustación en el modelo de predicción ETA. Con las incrustaciones, podemos convertir variables dispersas en representaciones vectoriales densas. Al mismo tiempo, mejoramos la generalizabilidad y equilibramos el enfoque del modelo en características dispersas frente a características densas cuantificando e incrustando características numéricas clave. Este enfoque ofrece ventajas como:
- Flexibilidad dimensional: El tamaño de la incrustación se basa en la importancia de cada característica categórica para la predicción de ETA, en lugar de en su cardinalidad, como se haría con la codificación de una sola vez. Tendemos a utilizar tamaños de incrustación más pequeños para evitar el sobreajuste y reducir el tamaño del modelo.
- Captación de patrones específicos de cada categoría: Las incrustaciones pueden captar patrones intrínsecos y similitudes entre categorías, lo que permite al modelo comprender las relaciones desde múltiples dimensiones; la codificación de objetivos, la codificación de frecuencias y la codificación de etiquetas sólo pueden captar cantidades limitadas de información.
- Generalización mejorada: La representación de características densas cuantizadas permite al modelo generalizar mejor a valores no vistos o poco frecuentes. Por ejemplo, algunos valores de características densas pueden ser extremadamente altos. Estos valores atípicos pueden tener menos impacto durante la inferencia porque probablemente estarán limitados por el cubo en el que caen; el cubo tendrá muchos datos de entrenamiento para encontrar su representación de incrustación.
- Flexibilidad en la combinación de funciones: Las funciones incrustadas pueden combinarse fácilmente con otras entradas numéricas, lo que permite interacciones más complejas.
- Reutilización en otros modelos: La incrustación entrenada puede extraerse y utilizarse como entrada para otros modelos. De este modo, los conocimientos aprendidos por un modelo de ETA pueden transferirse fácilmente a otras tareas.
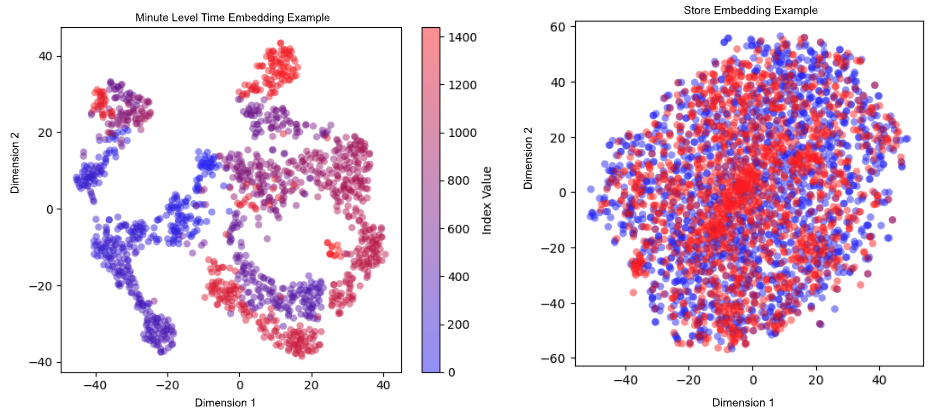
Nuestro modelo de ETA aprende las incrustaciones de características categóricas como cubos de tiempo, ubicaciones de recogida y entrega en varias granularidades, tipo de tienda, taxonomías de artículos y segmentos de asignación. La figura 2 muestra ejemplos de incrustación de tiempo e incrustación de tienda. En el ejemplo de incrustación de la hora, los puntos azules representan las primeras horas del día, mientras que los puntos rojos representan las últimas horas. Los minutos más cercanos se agrupan; En algunos casos, como cuando el final de un día va seguido de cerca por el inicio de la actividad del día siguiente, tanto los puntos rojos como los azules pueden encontrarse juntos. En el ejemplo de la incrustación de tiendas, los puntos azules representan las tiendas que utilizan un sistema de pedidos más estandarizado, mientras que los puntos rojos se refieren a un sistema de pedidos utilizado por los comerciantes más pequeños. Observamos que hay varios grupos de puntos rojos, lo que puede indicar que este sistema de pedidos influye más en la eficacia de la tienda, que a su vez influye en el plazo de entrega. Estas incrustaciones y otros parámetros se introducen en los codificadores DeepNet y CrossNet para captar tanto los patrones no lineales profundos como las interacciones explícitas entre características.
También hay otras características numéricas importantes, como la duración del viaje y el subtotal de la cesta de pedido. Transformamos estas características continuas en valores discretos mediante bucketización. Esto hace que nuestro modelo sea más robusto frente a los valores atípicos, ya que los cubos tapan los valores atípicos, lo que mejora la generalización del modelo. También permite aprender patrones complejos dentro de cada cubo y captar mejor las relaciones no lineales. Mientras tanto, los valores originales de las características no se descartan, sino que también se introducen en el codificador DeepNet para no perder precisión debido a la discretización, lo que proporciona flexibilidad a la hora de tratar distintos tipos de patrones.
Incorporación de series temporales
Nuestro modelo ETA funciona bien cuando la dinámica general del mercado es normal. Cuando se produce un cambio hacia la suboferta de Dasher, ya sea a escala regional o en una subregión, el rendimiento del modelo disminuye. Esto se debe a que las características antiguas sólo captan las condiciones de oferta/demanda a alto nivel y son volátiles a las fluctuaciones. Ambas hacen que la característica sea más ruidosa, lo que dificulta que nuestro modelo aprenda bien el patrón.
Observamos una fuerte correlación entre los pedidos anteriores y los posteriores en una ventana temporal pequeña. Por ejemplo, si una zona ya sufre un desabastecimiento de Dashers, los pedidos realizados en la siguiente ventana temporal rápida se añaden a la cola, lo que provoca efectos acumulativos de desabastecimiento. Para aprovechar esta naturaleza temporal de las ETA de entrega, la incorporación de características de series temporales ha sido crucial para responder más rápidamente a los cambios dinámicos del sistema.
Para transmitir esta información sobre tendencias en tiempo real a nuestro modelo, recopilamos series temporales con una frecuencia de un minuto, como el volumen medio de pedidos por minuto en los últimos 30 minutos. En comparación con el valor medio de los últimos 30 minutos, esta serie temporal transmite información más rica sobre la dinámica del mercado. Dado que este tipo de característica puede ser escasa si el intervalo de tiempo es pequeño, utilizamos el valor agregado del intervalo de cinco minutos y, a continuación, añadimos una incrustación posicional aprendible. Con la representación de aprendizaje del codificador transformador a partir de los datos secuenciales, el modelo ETA aprende una representación para la instantánea contextual de la dinámica del mercado en la ventana temporal pasada.
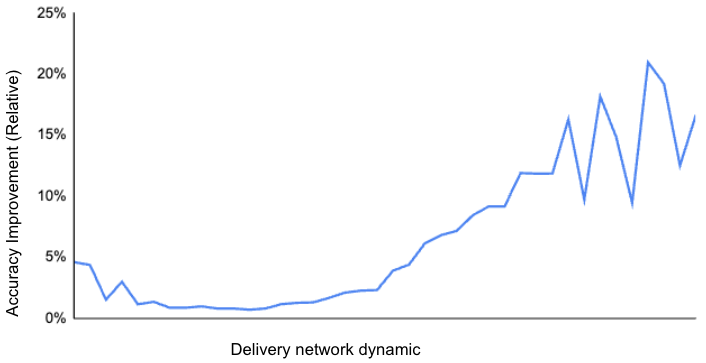
Comparamos el rendimiento del modelo con y sin las series temporales y comprobamos que la mejora del rendimiento puede atribuirse sobre todo a una mejor capacidad de respuesta a las distintas condiciones del mercado, especialmente cuando hay una importante escasez de Dashers, como muestra la figura 3 por la mayor dinámica de la red. Esto sugiere que nuestro modelo se ha adaptado mejor a las condiciones cambiantes a lo largo del tiempo, como la evolución de los patrones de pedidos o una dinámica de red cambiante.
Aunque este enfoque ofrece ventajas significativas, tiene un precio: una mayor complejidad computacional. Tanto el método de ingeniería de características como el codificador transformador contribuyen a una mayor carga computacional durante el entrenamiento y la inferencia. Gracias al firme apoyo de nuestro equipo de la plataforma de aprendizaje automático, este método se está produciendo con éxito y beneficiando a nuestros consumidores con predicciones de ETA de mejor calidad.
Comprender la arquitectura de los ME con MLP
Nos enfrentamos a varios retos a la hora de mejorar la precisión de nuestro modelo de ETA basado en árboles. Las predicciones del modelo tenían menos varianza que la verdad sobre el terreno, lo que indicaba una expresividad limitada, que dificultaba nuestra capacidad para captar toda la complejidad y variabilidad de la variable objetivo, especialmente en la cola larga.
Además, la maldición de la dimensionalidad dificultaba la identificación de divisiones significativas, lo que daba lugar a sobreajustes y subajustes, sobre todo con características dispersas. El análisis de errores sugirió que la incorporación de interacciones de características y dependencias temporales podría ayudar, pero la creación manual de estas interacciones era imposible y el ruido en los datos empeoraba el problema de la dimensionalidad, lo que dificultaba la extracción de patrones útiles.
En el corazón de nuestro modelo mejorado de predicción de ETA se encuentra una arquitectura MLP-gated MoE que mejora la expresividad del modo y aprende varios tipos de información automáticamente. Este enfoque nos permite aprovechar los puntos fuertes de diferentes estructuras de redes neuronales, cada una especializada en capturar aspectos específicos de las complejas relaciones de nuestros datos. Las siguientes secciones describen los componentes clave de esta arquitectura.
Codificadores paralelos
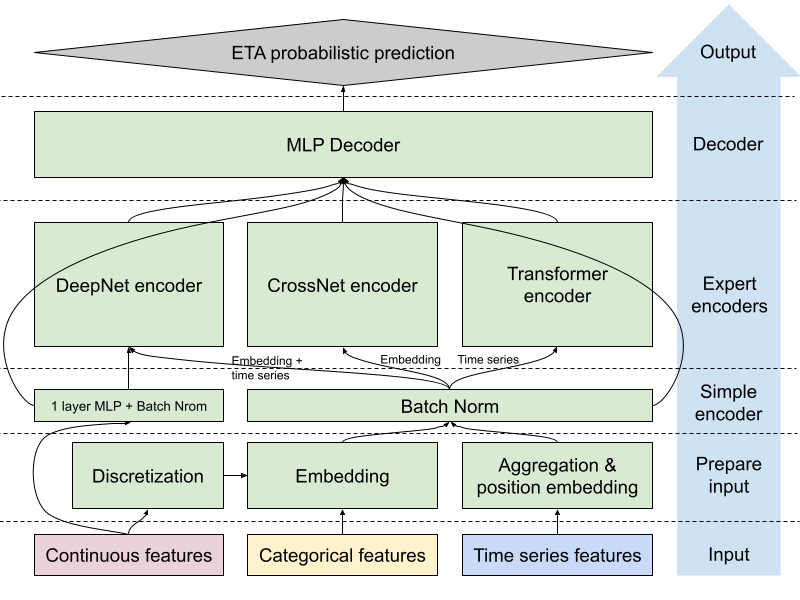
Como se muestra en la Figura 4, nuestro modelo de ME basado en MLP emplea tres codificadores paralelos, cada uno de los cuales actúa como experto en el procesamiento de diferentes aspectos de los datos de entrada:
- Codificador simple: Este MLP de una capa tiene dos objetivos principales: convertir la entrada en una dimensión fija que facilite la adición/eliminación de características y normalizar los valores de las características antes de transmitirlos a los expertos.
- Codificador DeepNet: Esta red neuronal profunda procesa las entradas a través de múltiples capas, incluyendo características numéricas, incrustaciones y características de series temporales agregadas. Destaca en la captura de interacciones de características generales y el aprendizaje de representaciones jerárquicas de los datos, y es particularmente eficaz en la comprensión de relaciones complejas y no lineales entre diversas características de entrada.
- Codificador CrossNet: Inspirado en la DCN v2 de los modelos de recomendación, el codificador CrossNet define parámetros de cruce aprendibles por capa como matrices de bajo rango e incorpora una mezcla de expertos con un mecanismo de compuerta que combina de forma adaptativa las interacciones aprendidas en función de la entrada. En la predicción de ETA, la entrada de este experto incluye todas las incrustaciones de características categóricas y características numéricas bucketizadas. El codificador CrossNet está diseñado para modelar eficazmente las complejidades e interdependencias entre las características temporales/espaciales/de orden. Al mismo tiempo, la profundidad y la complejidad de las interacciones están limitadas por el número de capas cruzadas y el rango de las matrices, lo que da lugar tanto a un efecto regulador como a una mayor eficiencia computacional.
- Codificador transformador: Aprovechando la potencia de los mecanismos de autoatención, el codificador transformador se centra en modelar dependencias y relaciones secuenciales. La entrada de este experto solo incluye la característica de serie temporal, que es una secuencia de señales. Si solo se introdujera en el codificador DeepNet, nuestro modelo ETA capturaría patrones jerárquicos no secuenciales e interacciones de características complejas, pero podría ignorar la información de orden secuencial. Ahí es donde entra en juego el codificador transformador, que puede aprender dependencias de largo alcance y relaciones contextuales dentro de las secuencias utilizando la autoatención. Las dependencias temporales hacen que esta comprensión secuencial sea útil para las predicciones de ETA. El modelo ETA puede responder más rápidamente a los cambios dinámicos si está expuesto a las relaciones temporales de volumen, ciclo de entrega y oferta/demanda.
Combinación de opiniones de expertos
Cada uno de estos codificadores procesa características de entrada diferentes, lo que da lugar a un aprendizaje exhaustivo en torno a diversos aspectos de la información. Reunimos las opiniones de los expertos de cada codificador en una única y rica representación, que luego se introduce en un perceptrón multicapa para traducir los conocimientos combinados en una predicción de la ETA. Esta arquitectura simplificada difiere de un ME tradicional en que no utiliza una red de compuertas separada para ponderar dinámicamente las contribuciones de cada experto. En su lugar, basándose en la representación aprendida de la característica de la serie temporal, el descodificador MLP es consciente de la dinámica, por lo que el descodificador MLP entrenado puede combinar y utilizar eficazmente las salidas de todos los codificadores simultáneamente en función de las diferentes situaciones. Abandonamos la red de compuerta explícita porque no proporciona mejoras de rendimiento incrementales significativas en las predicciones de ETA.
Esta arquitectura MLP-gated MoE nos permite aprovechar los puntos fuertes de diferentes estructuras de redes neuronales, manteniendo al mismo tiempo un nivel manejable de complejidad. Una de las principales ventajas de este enfoque reside en su extensibilidad. Esto permite incorporar fácilmente codificadores adicionales u otros componentes del modelo sin necesidad de rediseñar el mecanismo de compuerta. La arquitectura puede adaptarse para gestionar la integración de nuevas funciones, lo que hace que el modelo sea más versátil a la hora de responder a requisitos o patrones de datos cambiantes.
A medida que seguimos explorando estas vías, nuevas investigaciones para optimizar la integración de distintos codificadores -ya sea mediante diseños de MLP más sofisticados o mecanismos de compuerta novedosos- podrían desbloquear mejoras de rendimiento aún mayores. En última instancia, este enfoque nos permite ir por delante en el desarrollo de modelos y crear un marco que no sólo es potente hoy, sino que también está preparado para las innovaciones del mañana.
Estimación y comunicación de la incertidumbre en las predicciones de ETA
En el mundo de la entrega de alimentos, es crucial ofrecer previsiones de tiempo de llegada precisas. Pero igual de importante es nuestra capacidad para cuantificar y comunicar la incertidumbre asociada a estas predicciones. Aquí es donde entra en juego nuestro enfoque probabilístico de la predicción de ETA, que añade una nueva dimensión de fiabilidad a nuestras estimaciones.
Predicciones probabilísticas
Los modelos tradicionales de ETA suelen ofrecer una estimación puntual, lo que puede inducir a error en entornos muy variables como el reparto de alimentos. Nuestro planteamiento va más allá al aplicar una capa base probabilística para estimar la incertidumbre en nuestras predicciones.
Hemos explorado cuatro enfoques para determinar la incertidumbre sobre una única predicción:
- Estimación puntual: Descubrimos que existe una tendencia coherente entre la estimación puntual y la varianza de la verdad sobre el terreno. Basándonos en esta observación, creamos una fórmula para traducir la estimación puntual en incertidumbre.
- Muestreo: Para cada predicción, ejecutamos la inferencia varias veces, desactivando aleatoriamente conjuntos seleccionados de nodos; a continuación, utilizamos la distribución formada por todos los resultados de la inferencia como predicción final.
- Distribución paramétrica: Asumimos qué familia de distribución debe contener la verdad del terreno y luego dejamos que el modelo prediga los parámetros.¬†
- Distribución no paramétrica: No hacemos suposiciones sobre la distribución en sí, sino que suponemos el rango en el que podría situarse la verdad sobre el terreno. El rango posible se segmenta en múltiples cubos y, a continuación, el modelo predice la probabilidad de cada cubo. Podemos obtener una buena estimación de la función de densidad de probabilidad ajustando la granularidad o las técnicas de suavizado.
Al incorporar esta capa base probabilística, nuestro modelo no se limita a predecir un único valor de ETA, sino una distribución de posibles tiempos de llegada. Esta distribución proporciona información valiosa sobre la incertidumbre asociada a cada predicción.
Retos del aprendizaje de una distribución Weibull
En anteriores entradas del blog de 2021 y 2022, informamos de pruebas fehacientes de que el tiempo de entrega de alimentos sigue una distribución de cola larga que no puede modelarse mediante distribuciones gaussianas o exponenciales. Para capturar la naturaleza de cola larga y predecir con precisión la incertidumbre para cada entrega, optamos por modelar el tiempo de entrega de alimentos a través de la distribución de Weibull, cuya función de distribución de probabilidad toma la forma:
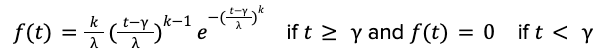
Los parámetros 𝑘, 𝝀, 𝛾 se denominan forma, escala y ubicación de la distribución de Weibull y especifican la forma de la cola, la anchura y el mínimo de la distribución. La tarea de aprendizaje automático es entrenar modelos de IA para predecir estos parámetros 𝑘, 𝝀, 𝛾 como funciones de las características de entrada 𝑋.
When we trained the AI model to maximize the log-likelihood under Weibull distribution, we found that the model sometimes makes unreasonable predictions. For instance, the model may predict a negative location 𝛾 < 𝑂, which means a non-zero chance that the food is delivered within one minute of placing the order, which is impossible in reality. The key challenge is that the parameters 𝑘, 𝝀, 𝛾 appear in the log-likelihood function in highly nonlinear forms
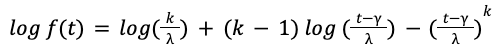
y es probable que el modelo se ajuste en exceso a los datos observados.
Regresión por intervalos
Dado que el uso de la función de pérdida log-verosimilitud no conducía a predicciones precisas, necesitábamos modificar la función de pérdida para facilitar el aprendizaje de los parámetros de la distribución de Weibull. Tras múltiples ensayos, propusimos un enfoque innovador para utilizar la función de supervivencia 𝑆(𝑡), definida como:
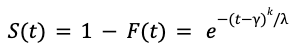
Además, aprovechamos la transformación logarítmica de la función de supervivencia, que adopta una forma funcional mucho más sencilla:
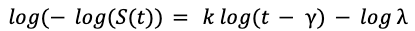
Utilizando esto como función de pérdida, usamos mínimos cuadrados simples para ajustar los parámetros de la distribución Weibull 𝑘, 𝝀, 𝛾.
Por último, necesitábamos derivar la función de supervivencia 𝑆(𝑡) a partir de los datos. La regresión por intervalos ofrece una solución, agrupando las entregas con características de entrada 𝑋 similares y trazando un histograma del tiempo de entrega de alimentos 𝐻(𝑡) en el que la duración de cada cubo es de seis minutos, como se muestra en la figura 5 a continuación.
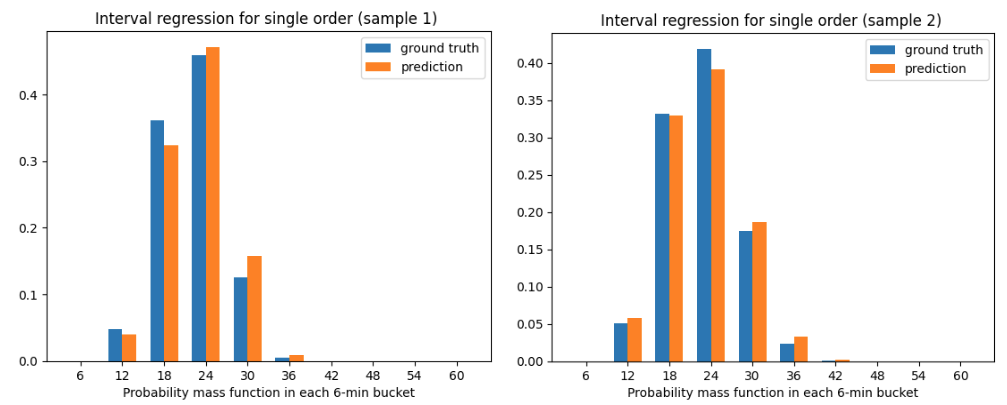
La función de supervivencia en cada momento t se obtiene simplemente sumando los valores del histograma para 𝑡' > 𝑡:
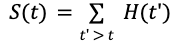
Un estudio de simulación
Validamos la precisión de la predicción del enfoque de regresión por intervalos mediante un estudio de simulación. Para cada entrega con características de entrada 𝑋, utilizamos funciones fijas para generar los parámetros de la verdad sobre el terreno
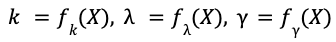
Los modelos de IA deben aprender estas funciones𝑓𝑘,𝑓𝜆,𝑓𝛾. Dado cada conjunto de características de entrada 𝑋, simulamos 1 millón de observaciones extrayendo muestras aleatorias de la distribución Weibull con estos parámetros 𝑘, 𝝀, 𝛾. Esto forma los conjuntos de datos de entrenamiento y validación.
A continuación, utilizamos el enfoque de regresión por intervalos y entrenamos una red neuronal multicabezal para aprender simultáneamente las funciones𝑓𝑘,𝑓𝜆,𝑓𝛾. Comparamos los parámetros predichos con sus valores reales y medimos la precisión de las predicciones de distribución.
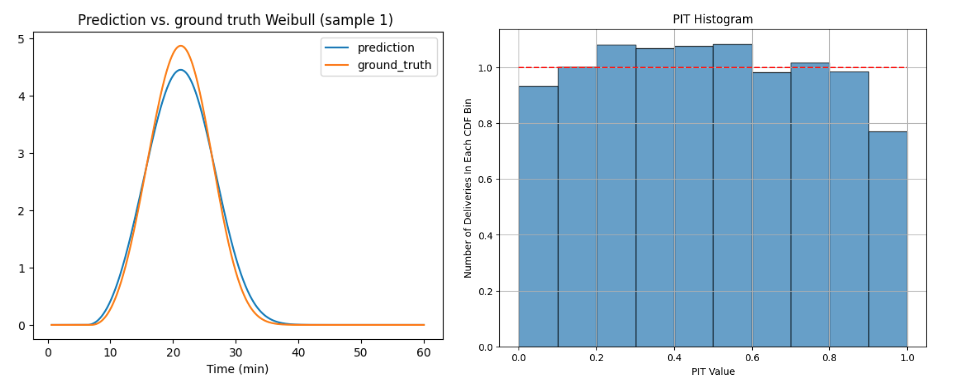
Descubrimos que nuestro enfoque de regresión por intervalos reducía en gran medida el problema del sobreajuste y predecía valores más precisos de los parámetros de Weibull. Como se muestra en la figura 6, los parámetros reales son 𝑘 = 3,37, 𝜆 = 0,27, 𝛾 = 0,11, mientras que sus valores predichos son 𝑘 = 3,22, 𝜆 = 0,28, 𝛾 = 0,10. La calibración del modelo, medida por el histograma PIT (figura 6), también mejora mucho como resultado.
La regresión por intervalos nos permite aprender simultáneamente los parámetros de forma, escala y localización de la distribución de Weibull con gran precisión. Nuestro siguiente paso es aplicar el enfoque de regresión por intervalos a datos reales de reparto. Entonces podremos aprovechar las distribuciones de probabilidad predichas para ofrecer a los clientes los tiempos de llegada más precisos posibles para la entrega de comida, estimando al mismo tiempo de forma fiable la incertidumbre en estas predicciones de tiempo de llegada.
Seguimos estudiando la mejor manera de predecir las incertidumbres de ETA para poder seguir mejorando la precisión y transparencia de nuestro servicio. Comprender la incertidumbre de la ETA también permite una asignación más eficiente de los Dashers y una mejor planificación de las rutas. Este enfoque probabilístico representa un importante paso adelante en nuestra misión de ofrecer la mejor experiencia de entrega posible a nuestros clientes y socios.
Aprovechar el aprendizaje multitarea para diversos escenarios de ETA
El proceso de entrega de un pedido se divide en dos fases: la fase de exploración y la fase de pago, como se muestra en la Figura 7. En la etapa de exploración, los consumidores navegan por las tiendas sin añadir todavía ningún artículo a su cesta de la compra. En esta fase, sólo podemos acceder a funciones relacionadas con la tienda o con el comportamiento histórico del consumidor. En la fase de pago, los consumidores han creado un carrito de la compra, por lo que también accedemos a información sobre los artículos. Utilizamos modelos entrenados individualmente para estas dos etapas, pero descubrimos que esto puede dar lugar a incoherencias en las estimaciones. Las grandes diferencias sorprenden a los consumidores de forma negativa y minan su confianza en nuestras estimaciones. Nuestro primer intento de mitigarlo ha sido aplicar un ajuste en la última etapa basado en estimaciones anteriores. Este ajuste mejoró la coherencia, pero redujo la precisión. En la etapa posterior, la estimación suele ser más precisa debido a la mayor disponibilidad de datos. Este ajuste se basa en estimaciones de etapas anteriores, lo que introduce una reducción de la precisión. Para resolver la incoherencia sin perjudicar la precisión, hemos aplicado un enfoque de aprendizaje multitarea para desarrollar nuestro modelo de predicción de ETA. Esta estrategia nos permite manejar diferentes escenarios de ETA juntos, lo que conduce a predicciones más coherentes y eficientes. Veamos los detalles de nuestro método y sus ventajas.
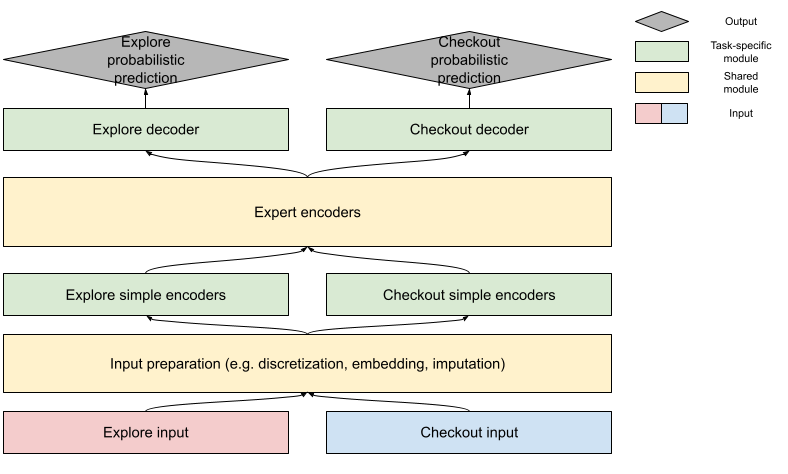
Compartido frente a específico de la tarea
Elaborar una predicción de ETA implica desarrollar predicciones probabilísticas tanto de exploración como de comprobación. Estas dos tareas tienen mucho en común, con etiquetas -la duración real de la entrega- compartidas entre ambas. En la mayoría de las muestras, los valores de las características relacionadas con la tienda y con el consumidor están muy próximos. Por tanto, podemos esperar que la relación aprendida entre estas características y las etiquetas sea similar. Teniendo en cuenta los puntos en común, también es razonable compartir los parámetros que representan la relación entre las características y las etiquetas. Sin embargo, la disponibilidad de la información del pedido es diferente; en el caso de la información en tiempo real, la distribución de los valores de las características de la fase de pago puede ser diferente y suele tener una mayor correlación con la etiqueta. Debido a estas diferencias, los módulos específicos de cada tarea gestionan la diferencia de entrada y convierten la representación codificada final en la predicción. La figura 8 muestra nuestro diseño de entrenamiento para equilibrar la precisión específica de la tarea y el intercambio de conocimientos:
Formación conjunta frente a formación secuencial
Comenzamos este viaje con una decisión crítica entre el co-entrenamiento o el entrenamiento secuencial. El coentrenamiento, que consiste en entrenar todas las tareas simultáneamente utilizando una arquitectura de modelo compartida, parecía inicialmente atractivo por su eficiencia en el tiempo de entrenamiento y en el uso de recursos informáticos. También ofrecía la posibilidad de que las tareas compartieran conocimientos en tiempo real. Al final, sin embargo, observamos una degradación significativa de la precisión en tareas individuales, probablemente causada por la interferencia entre tareas.
En su lugar, recurrimos al entrenamiento secuencial, en el que las tareas se entrenan una tras otra, congelando los parámetros aprendidos durante las tareas anteriores y entrenando los parámetros específicos de la tarea para los esfuerzos posteriores. A pesar de requerir más tiempo, este método demostró ser superior para la predicción de la ETA. Al aislar el proceso de entrenamiento de cada tarea, pudimos reducir el ruido de otras tareas y ajustar mejor los parámetros específicos de cada tarea. Y lo que es más importante, este método facilitó una transferencia eficaz del aprendizaje al compartir parámetros entre tareas y minimizar las interferencias.
El método de entrenamiento secuencial que hemos aplicado comienza con el entrenamiento de nuestro modelo en tareas de pago. Una vez que esta tarea está bien aprendida, congelamos todos los parámetros relacionados con el pago y pasamos a entrenar los parámetros ligeros específicos de la exploración. Dado que la tarea de pago tiene mayor prioridad e información más rica, es mejor entrenar la mayoría de los parámetros, como las incrustaciones y los codificadores expertos, en ella. La mejora de la precisión en la tarea de exploración también demuestra el éxito de la transferencia de conocimientos.
Ventajas de la formación multitarea
Los beneficios de este enfoque de aprendizaje multitarea han sido sustanciales y de gran alcance. En primer lugar, hemos logrado una notable mejora de la coherencia en las predicciones de ETA en las distintas etapas sin sacrificar la precisión. Además, a pesar de la naturaleza secuencial de nuestro proceso de formación, este enfoque ha demostrado ser más eficiente que la formación de modelos separados para cada etapa. Los componentes compartidos proporcionan un punto de partida para otros escenarios, simplificando el desarrollo y reduciendo la velocidad, una consideración crucial a nuestra escala de operaciones.
Quizá lo más interesante es que hemos observado una transferencia significativa del aprendizaje entre etapas, mejorando el rendimiento de la tarea de exploración mediante el ajuste del modelo de la tarea de caja. Esto abre la posibilidad de transferir los patrones aprendidos a más tareas, por ejemplo, utilizando la incrustación de la tienda para otros problemas empresariales posteriores.
El aprendizaje multitarea ha sido una piedra angular en la mejora de nuestra precisión de ETA. Al aprovechar los puntos fuertes del entrenamiento secuencial y las ventajas del aprendizaje multitarea, hemos creado un sistema de predicción del tiempo estimado de llegada más sólido, eficiente y preciso. A medida que seguimos perfeccionando y ampliando nuestro enfoque de aprendizaje multitarea, estamos entusiasmados con su potencial para mejorar aún más nuestras predicciones de ETA, lo que en última instancia conduce a mejores experiencias de los clientes, operaciones de socios más eficientes y entregas Dasher más fluidas.
El futuro de la estimación del plazo de entrega
A medida que concluimos nuestra inmersión profunda en los últimos avances de DoorDash en la predicción de ETA, está claro que nuestro viaje hacia tiempos de entrega más precisos y fiables ha dado resultados impresionantes. La notable mejora relativa del 20% en la precisión del tiempo estimado de llegada es un testimonio del enfoque innovador de nuestro equipo y de su incesante búsqueda de la excelencia. Hemos mejorado la precisión tanto para pedidos grandes como pequeños, entregas a corta y larga distancia, y tanto en horas punta como en horas valle. Este avance mejora directamente la experiencia de nuestros clientes al minimizar los retrasos inesperados y evitar las llegadas prematuras. Como resultado, nuestros clientes ahora pueden confiar más en nuestros plazos de entrega estimados, lo que les permite planificar sus calendarios con mayor confianza.
Este importante avance es la culminación de varias técnicas avanzadas. Nuestra arquitectura simplificada de ME, con sus codificadores paralelos y su novedoso enfoque de combinación, ha demostrado su capacidad para manejar los diversos escenarios inherentes a la entrega de alimentos. La ingeniería avanzada de características, que aprovecha las incrustaciones y los datos de series temporales, ha mejorado la capacidad del modelo para captar patrones matizados y dependencias temporales. El enfoque de aprendizaje multitarea y su entrenamiento secuencial han mejorado la coherencia en diversos escenarios de ETA, facilitando al mismo tiempo una valiosa transferencia de conocimientos entre tareas. Por último, la introducción de predicciones probabilísticas amplía el potencial de nuestro modelo al enriquecer las predicciones con un contexto más probabilístico.
Estos avances han tenido un profundo impacto en las operaciones de DoorDash, dando lugar a una logística más eficiente, una mayor satisfacción del cliente y una experiencia más fluida para todo nuestro ecosistema de clientes, Dashers y comerciantes.
No obstante, reconocemos que la búsqueda de plazos de entrega perfectos es un viaje continuo. De cara al futuro, nos entusiasma explorar nuevas fronteras en la estimación del tiempo de entrega. Nuestro compromiso con la innovación sigue siendo inquebrantable. Creemos que mediante la mejora constante de nuestras predicciones de ETA, podemos crear una experiencia aún mejor para todos en la comunidad DoorDash. Esperamos que esta entrada del blog haya proporcionado información valiosa sobre el complejo mundo de la predicción de ETA y las soluciones innovadoras que estamos implementando en DoorDash.
Agradecimientos
Un agradecimiento especial a Vasundhara Rawat, Shawn Liang, Bin Rong, Bo Li, Minh Nguyen, Kosha Shah, Jie Qin, Bowen Dan, Steve Guo, Songze Li, Vasily Vlasov, Julian Panero y Lewis Warne por hacer posible las mejoras del modelo ETA.





